
You’ve watched your Google rankings hold steady for months. Then a prospect tells you they “just asked ChatGPT” for a recommendation in your category, and your brand wasn’t in the answer. Your competitor was. Twice.
The gap between traditional SEO performance and AI search visibility is growing faster than most marketing teams realize. Over 73% of brands that rank in the organic top 10 have zero mentions in AI-generated answers for the same query category. That’s not a minor discrepancy. That’s a structural blind spot.
Claude 4.7, GPT-4.5, and Gemini 2.0 now mediate approximately 80% of all information-seeking behaviors. Choosing which one to prioritize for brand visibility isn’t a technical question. It’s a revenue question.
Your Search Rank Doesn’t Predict Your AI Visibility
The collapse of traditional click-through rates makes this concrete. By mid-2025, approximately 60% of all Google searches concluded without a single click to an external website. When Google’s AI Mode was active, that figure climbed to 93%.
For every 100 clicks a brand historically earned at position #1, current data shows Google now retains 58 of them through AI Overviews. That’s not a trend. That’s a fundamental restructuring of the buyer journey.
AI brand visibility measures something different from a keyword rank. It tracks the frequency, prominence, and favorability with which a brand appears in AI-generated answers across conversational prompts. The “new first-page placement” is the primary recommendation within an AI response, and the first brand mentioned in that response receives disproportionate trust-building weight.
The conversion data reinforces this shift. While traditional organic search converts at an industry average of around 2%, AI-referred visitors convert at 14.2%. The AI has already handled the research and qualification phases before the click ever happens.
| Feature | Traditional SEO Ranking | AI Brand Visibility (GEO) |
|---|---|---|
| Primary Goal | Top-3 blue link position | Inclusion in synthesized AI answers |
| Success Metric | Clicks, CTR, organic sessions | Mention rate, share of model, sentiment |
| Conversion Rate | ~2% industry average | ~12-18% for AI-referred visitors |
| Content Focus | Keyword density and backlinks | Extractability, factual density, authority |
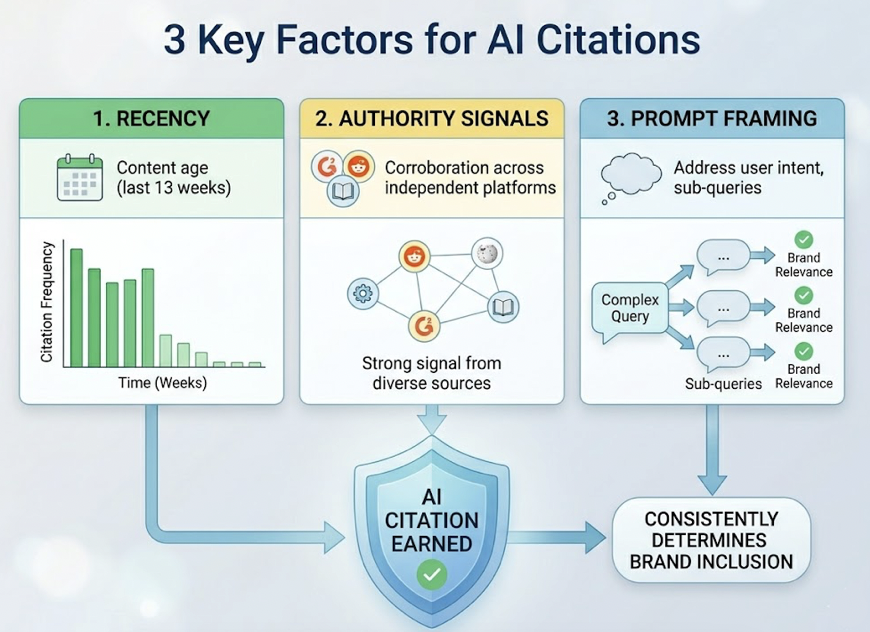
Three factors consistently determine whether a brand earns a citation in AI answers: recency, authority signals, and prompt framing. More than half of all observed citations reference content published within the last 13 weeks. Authority is no longer just domain age; it’s corroboration across independent platforms like G2, Reddit, and major media. And prompt framing matters because AI engines use “query fan-out” techniques, breaking complex questions into sub-queries that brands must address to stay relevant.
Claude 4.7 Rewards Depth Over Volume
Claude 4.7 interprets prompts conservatively. It won’t engage in hallucinated name-dropping or list-filler recommendations. A brand has to be explicitly relevant to the user’s specific constraints to earn a mention, which is actually a signal of quality when your brand does appear.
The strength here is context-aware synthesis. In professional knowledge work benchmarks, Claude models lead with an Elo score of 1633, reflecting their superiority in analysis, documentation, and decision support. When a buyer asks for a vendor evaluation, Claude 4.7 is more likely to produce a structured, evidence-backed justification for its recommendation.
That said, Claude’s “selective citation” bias is real. Content that presents multiple perspectives, acknowledges trade-offs, and uses well-defined technical terms earns Claude’s trust. Standard pricing pages and marketing collateral typically don’t.
Claude 4.7 is also 30% more likely to cite content formatted with bulleted lists and clear heading hierarchies. Because its updated tokenizer increases effective token costs by up to 35% on identical text, the model favors “atomic answers”: concise 40-to-60-word paragraphs that can be integrated into a response with minimal modification.
The GEO implication is clear: depth and citation-ready sourcing are what move the needle in the Claude ecosystem. Brands with extensive third-party source coverage in technical blogs and research contexts are disproportionately favored.
| Claude 4.7 Lever | Impact on Brand Visibility |
|---|---|
| Literal Instruction Scope | Minimal surfacing for vague queries; brand needs tight ICP focus |
| Nuance Recognition | Favors brands that acknowledge complexity and trade-offs |
| High Output Verbosity | Cited brands gain deep narrative share in responses |
| Tokenizer Efficiency | Concise, extractable summaries perform better |
GPT-4.5 Surfaces More Brands, But Watch the Sentiment
GPT-4.5 is the consensus engine. It excels at recognizing patterns across the broadest possible dataset, which translates to a high brand mention frequency. ChatGPT mentions brands in approximately 73.6% of responses, compared to Google’s AI Overviews at 48.5%.
The mechanism is “patterned intuition.” If a brand has a high volume of mentions on Reddit, Quora, or YouTube, GPT-4.5 is likely to surface that name as a consensus choice regardless of traditional SEO strength. That’s both an opportunity and a risk.
The risk is product-evaluation negativity. While only 1.6% of ChatGPT mentions are negative overall, 19.4% of that negativity surfaces during the consideration-to-purchase phase, a rate 13 times higher than Google. GPT-4.5 is more likely to provide critical “is it worth it” assessments precisely when users are closest to a buying decision.
The persistence problem is also significant: only 30% of brands show up in consecutive identical queries. High mention frequency doesn’t mean consistent mention frequency.
ChatGPT Search draws 87% of its citations from Bing’s top 10 results, which means traditional technical SEO is still the entry ticket. But brand building across communities is what determines recommendation strength. Consistent facts across your website, media placements, and social profiles matter because AI models resolve conflicting information by favoring the most frequently repeated version.
Gemini 2.0 Runs on Google’s Ecosystem
Gemini occupies a genuinely different position. It’s natively embedded across Google Workspace, Chrome, and 5 billion Android devices. That ubiquitous distribution creates multiple touchpoints where a brand is either present or invisible.
Gemini’s brand surfacing is grounded in the Google Search index and the Knowledge Graph. In 2026 tests of local business information, Gemini achieved 100% accuracy due to its integration with Google Maps, while ChatGPT and Perplexity averaged only 68%. Brands with a robust Google footprint get a measurable head start.
The filtration is aggressive, though. Gemini assistants recommend only 11% of available business locations, prioritizing high ratings and complete profile coverage over proximity. Newer or niche brands that lack sufficient Google-verified signals are often excluded entirely.
Approximately 99.5% of the sources synthesized in Gemini-powered AI Overviews come from the top 10 organic search results. That’s the most direct dependency on traditional SEO of any major AI model. Strong Search Console performance, Core Web Vitals, and indexing are the direct substrates for Gemini visibility.
| Gemini Integration Point | Strategic Visibility Impact |
|---|---|
| AI Overviews | 2B monthly users; 99.5% of sources from Google top 10 |
| Google AI Mode | 75M daily active users; 93% zero-click rate |
| YouTube Grounding | Native video indexing favors “how-to” visual content |
| Knowledge Graph | Relationship mapping connects brand entities to category intents |
Claude 4.7 vs GPT-4.5 vs Gemini 2.0: Side-by-Side
| Metric | Claude 4.7 | GPT-4.5 | Gemini 2.0 |
|---|---|---|---|
| Visibility Rate | Moderate (selective retrieval) | High (pattern consensus) | High (SERP-integrated) |
| Sentiment Accuracy | High (nuanced, analytical) | Moderate (neutral, broad) | High (E-E-A-T driven) |
| Citation Depth | Deep (logic, research) | Moderate (news, social) | High (index, maps) |
| SEO Dependency | Low (internal reasoning) | Moderate (Bing index) | Extreme (Google index) |
| GEO Lever | Analytical depth and logic | Reddit and social consensus | Schema and map accuracy |
| Purchase Phase Risk | Legal and structural caveats | High negative criticism rate | Star rating and NAP filters |
No single model wins across all contexts. Claude 4.7 is the definitive engine for high-stakes B2B research and professional analysis. GPT-4.5 dominates general consumer discovery and broad market consensus. Gemini 2.0 leads in transactional commerce, local intent, and integrated workflow discovery.
That combination is why optimizing for only one platform is a strategic mistake in 2026.
Manual Testing Doesn’t Scale. Here’s What Does.
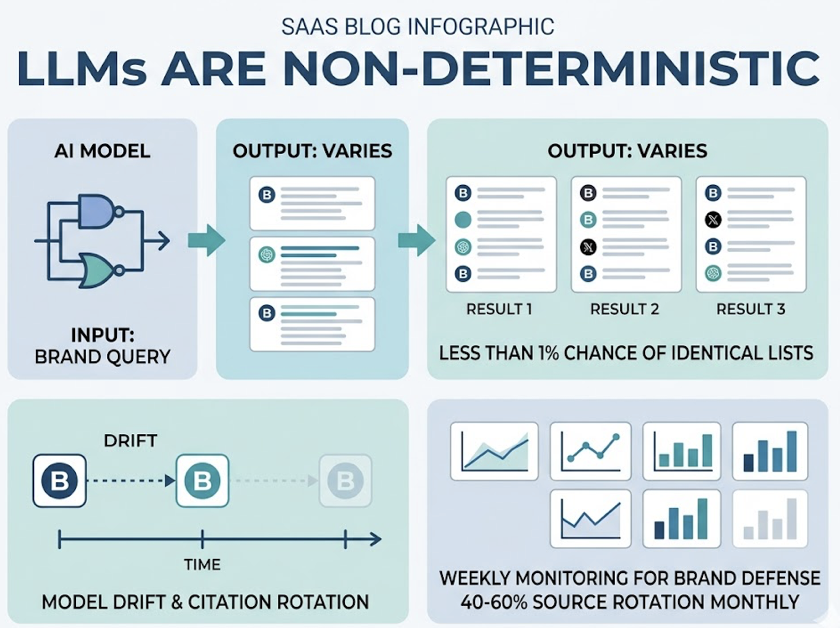
LLMs are non-deterministic. There’s less than a 1-in-100 chance that an AI will produce the identical list of brand recommendations twice in a row across 100 attempts. A brand may appear in a single response today and be invisible in an identical query an hour later due to model drift or citation rotation. Roughly 40-60% of AI Overview citation sources rotate monthly, making weekly monitoring the practical minimum for brand defense.
This is why marketing teams are adopting dedicated GEO tracking platforms. Topify automates the querying process across ChatGPT, Gemini, Perplexity, and Claude, tracking seven metrics that traditional SEO dashboards can’t see:
AI Visibility Rate (AVS) tracks the frequency and prominence of brand mentions across dozens of industry-relevant queries, normalized by platform and competitor. Sentiment Score evaluates whether a brand is being mentioned factually or actively recommended as a solution. A drop in sentiment is often the first warning signal of perception drift.
Position Ranking monitors where in the AI response your brand appears. Being listed first in a recommendation drives 32% higher purchase intent than being listed fourth. Prompt Coverage measures how many distinct user intents trigger a brand mention, revealing gaps in top-of-funnel discovery.
Citation Rate distinguishes between a text mention (building awareness) and a clickable citation (driving traffic). Mentions are 3x more predictive of overall AI visibility than backlinks, but citations are the only mechanism that preserves the direct revenue pathway. Intent Mapping connects visibility to high-intent decision-making prompts versus low-intent informational queries, identifying gaps where competitors are winning citations at the final research phase.
Conversion Visibility Rate (CVR) estimates the probability that an AI answer is driving meaningful user interaction. With AI-referred visitors converting at 14.2% compared to 2.8% for traditional organic search, this is the critical revenue signal for any GEO program.
For teams ready to stop guessing and start tracking, get started with Topify to see where your brand actually stands across all three platforms.
Conclusion
The 2026 research confirms a structural decoupling of search rankings from AI visibility. Brands winning the click-war of 2015 may be losing the “share of model” war of 2026. And since 65% of searches are expected to be zero-click as traditional search volume continues declining, that gap has direct revenue consequences.
The brands that will dominate AI discovery treat measurement as the prerequisite for strategy, not the follow-up. Track visibility, sentiment, and position across Claude 4.7, GPT-4.5, and Gemini 2.0. Identify the specific source domains and content structures that drive AI recommendations for your category. Then optimize for the platforms where your buyers actually search, not just the one you can see in your current dashboard.
FAQ
Q: Is Claude 4.7 better than GPT-4.5 for brand mentions?
A: It depends on the objective. GPT-4.5 is superior for broad, top-of-funnel awareness due to its higher mention frequency of 73.6% of responses. Claude 4.7 is the better choice for detailed professional recommendations and analytical contexts, and is 30% more likely to cite your specific content if it’s technically dense and logically structured. For high-stakes B2B evaluations, Claude 4.7 carries more weight. For mass market consumer discovery, GPT-4.5 reaches more users.
Q: Does Gemini 2.0 favor brands that rank well on Google?
A: Yes, more definitively than any other engine. Approximately 99.5% of the sources synthesized in Gemini-powered AI Overviews are drawn from the top 10 organic search results. Strong traditional SEO fundamentals including indexing, Core Web Vitals, and Search Console authority are the direct substrates for Gemini visibility. A brand that doesn’t rank on Google is unlikely to surface in Gemini.
Q: How often do AI models update their brand recommendations?
A: The retrieval-augmented layer updates as fast as search engines crawl the web, which means near-real-time changes are possible. AI Overviews show high volatility, with 40-60% of cited sources rotating monthly. The underlying foundational knowledge updates during major training runs. Weekly monitoring is the practical minimum for brand defense, especially in fast-moving categories.
Q: Can I optimize for Claude 4.7, GPT-4.5, and Gemini 2.0 at the same time?
A: Yes. While each platform has unique retrieval preferences (Claude favors logic, GPT favors social consensus, Gemini favors ecosystem signals), there’s a significant core of universal GEO best practices. High-quality, evidence-grounded content with clear heading hierarchies, answer-first introductory blocks, and comprehensive schema markup will satisfy the ranking and citation criteria of all three major generative engines simultaneously.

