
Your content team switched to AI-assisted drafting six months ago. Output is up. But the editing queue hasn’t shrunk. Every long-form piece still comes back needing a full structural rewrite, or the brand voice has drifted by paragraph four, or the research section quietly invented a statistic. The problem isn’t that the model is bad. It’s that you’re using a general-purpose tool for precision work.
Claude 4.7 was built differently. Here’s where that difference shows up in practice.
Long-Form Drafts That Don’t Fall Apart at 1,500 Words
Most models handle short content well. The drop-off happens in longer documents, where “structural drift” kicks in: sections start repeating, the argument loses its thread, and the conclusion no longer connects to what the introduction promised.
Claude 4.7 addresses this directly through improved document reasoning. Data from Databricks’ OfficeQA Pro evaluation shows a 21% reduction in document reasoning errors compared to its predecessor, Opus 4.6. In practice, this means a 3,000-word whitepaper maintains its internal logic from premise to recommendation, without the model losing track of what it established three sections earlier.
GPT-4o compensates differently. It relies heavily on visual formatting, bullet points, and section breaks to create the appearance of structure. That approach works for scannable marketing copy. It falls apart in deep-dive reports where the argument has to hold across the entire document.
Content teams at Bolt and Hexagon reported that Claude 4.7 pushes the ceiling on what ships in a single session, with measurable improvement in longer document drafting tasks. That’s not a feature. That’s fewer rewrites.
Brand Voice Instructions It Actually Follows on Output #5
Here’s where Claude 4.7 is genuinely different from every prior model: it’s substantially more literal.
Previous versions performed what researchers call “intent inference.” The model would guess what you probably wanted based on limited context and fill in the gaps. That sounds helpful until you’re running a brand with a precise style guide and you notice the tone has drifted by the third output.
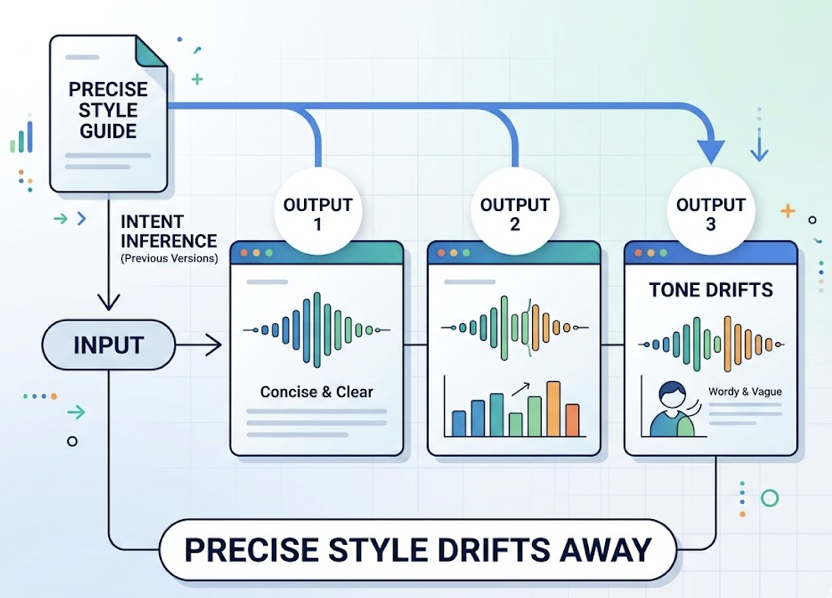
Claude 4.7 doesn’t infer. It follows what’s written. If your system prompt says “no passive voice, no hedging, no bullet points,” that instruction holds in output five the same way it held in output one. The model tracks what’s been done without losing the goal state.
The trade-off is real: if your prompt is vague, the output goes clinical. Users have described the default as “smart but intake-therapist energy.” The fix is explicit scoping. Brand teams need to encode their style defaults in a standing context file rather than relying on the model to read between the lines.
That’s extra upfront work. On the flip side, it’s also the reason you can trust the output to stay on-brand at scale.
Research-Heavy Content With a Lower Hallucination Rate
The hallucination problem hasn’t been solved. But Claude 4.7 has moved the needle more than most.
The model scores a 91.7% honesty rate and ranks at the top against comparable models on sycophancy metrics. More specifically, it demonstrates what researchers call “calibration on ambiguity”: when the data isn’t there, the model says so rather than generating a plausible-sounding substitute.
In legal document work, Claude 4.7 scored 90.9% on BigLaw Bench at high effort, including correctly distinguishing between document clause types that historically tripped up other models. For SEO whitepapers and technical reports, this matters more than the headline benchmark. You need a model that flags the gaps, not one that papers over them.
There’s one documented regression worth knowing about: when synthesizing multiple conflicting sources, the model occasionally blends them into a “both are true” response rather than flagging the contradiction. For high-stakes research, run a secondary verification pass on any section that draws from more than two sources.
That’s not a dealbreaker. It’s a workflow consideration.
Editing Passes That Cut Instead of Polish
Tell GPT-4o to reduce a 2,000-word section by 30% and you’ll often get a 1,900-word version with slightly tighter sentences. The word count barely moves. The structure is preserved. Nothing got cut.
Claude 4.7 behaves differently because of how it handles literal constraints. Negative instructions stick. “Remove fluff. Do not rewrite or enhance.” produces actual removal, not enhancement disguised as reduction.
The prompt structure that works:
- System role: “You are a ruthless content editor specializing in word-count reduction.”
- XML separation: Use
<instructions>and<content_to_edit>tags to separate the directive from the content. - Explicit outcome: “Rewrite this section to be 30% shorter while keeping every core recommendation intact.”
- Verification step: “After completing the edit, list any core information that was removed.”
The API also supports task budgets (currently in beta), which let you give the model a token ceiling for a full editing loop. The model self-moderates to hit the target rather than expanding to fill the space.
For content teams running recurring compression tasks, this is the most underutilized capability in the current release.
Multilingual Output That Reads Like a Native Wrote It
Claude 4.7 shipped with a redesigned tokenizer built explicitly for non-Latin scripts. For Mandarin, Japanese, Korean, Arabic, and Hindi, token efficiency improved by 20–35% compared to the previous version. That’s not just a cost story. Better tokenization means more information fits within the same context limit, which directly affects output quality in complex-grammar languages.

On professional knowledge work, Claude 4.7 scores 1,753 Elo on the GDPval benchmark, compared to GPT-5.4’s 1,674 Elo. For global content teams, that gap matters most when the task requires sustained argument and domain precision, not just translation fluency.
The realistic limitations: Japanese and Korean syntax still benefits from human localization review, particularly for cultural nuance and postposition accuracy. And English-dominant workloads will see a 12–18% increase in token counts due to the tokenizer shift, so budget accordingly if your team is primarily writing in English.
The model’s strength is “round-trip accuracy”: translating from source to target and back with minimal semantic loss. For brands producing regional content at volume, that’s a meaningful baseline to work from.
Where Claude 4.7 Still Loses Ground
No honest evaluation skips the weaknesses.
Real-time web research: On the BrowseComp benchmark, GPT-5.4 Pro scores 89.3% versus Claude 4.7’s 79.3%. If your content workflow depends heavily on live web synthesis across multiple pages, that gap is real and currently matters.
Long-context recall above 100K tokens: Some documented regressions exist in “needle-in-a-haystack” retrieval for contexts above that threshold. Facts in the middle third of very long documents are more likely to be missed or misattributed than in the previous version.
Plugin ecosystem: Claude’s integration surface is expanding, but it still doesn’t match the breadth of OpenAI’s GPT Store or Google’s native Workspace integrations. If your stack depends on a specific third-party plugin, check availability before committing.
These aren’t reasons to avoid the model. They’re reasons to be clear about where it fits in a multi-model workflow.
How to Decide If Claude 4.7 Belongs in Your Content Stack
The question isn’t whether Claude 4.7 is better than GPT-4o in some abstract sense. It’s whether it’s better for the specific tasks your team runs most often.
| Task Type | Recommended Model | Reason |
|---|---|---|
| Long-form reports / whitepapers | Claude 4.7 | Superior structural integrity above 1,500 words |
| Real-time web research synthesis | GPT-5.4 Pro | Clear lead on multi-hop browsing benchmarks |
| Multilingual professional content (CJK) | Claude 4.7 | Token efficiency gains + GDPval lead |
| Brand voice at scale | Claude 4.7 | Literal instruction following; requires explicit prompts |
| Surgical content compression | Claude 4.7 | Negative constraints actually stick |
One layer that often gets missed in these comparisons: even if your Claude 4.7-generated content is structurally strong, you still need to know whether it’s being cited by AI platforms. That’s a separate measurement problem.
Topify tracks brand visibility across ChatGPT, Gemini, Perplexity, and other major AI platforms, showing where your content earns citations and where competitors are getting recommended instead. Use Claude 4.7’s precision editing to implement GEO recommendations, and use Topify’s Source Analysis to understand which content formats AI engines are actually pulling from. The combination closes the loop between production quality and AI search performance.
If you want to get started tracking your brand’s AI visibility, the gap between what you’re publishing and what AI is citing is usually the first thing worth measuring.
Conclusion
Claude 4.7 isn’t a universal upgrade. It’s a precision tool that rewards teams willing to invest in explicit prompts and disciplined workflows. For long-form synthesis, brand voice fidelity, and surgical editing, it outperforms what most content teams have been working with. The structural drift problem alone is worth the switch for teams producing deep-dive content at volume.
The models are getting more differentiated, not less. The teams that understand which tool handles which task, and measure the downstream AI visibility of what they publish, are the ones building a compounding advantage.
FAQ
Q: Is Claude 4.7 better than GPT-4o for SEO content?
A: For long-form, topic-authority content, yes. Claude 4.7 maintains narrative arc and editorial consistency over deep-dive articles in a way that GPT-4o doesn’t. GPT-4o produces more scannable output, which works for short-form but loses coherence in complex reports. The distinction matters most for content designed to establish topical authority rather than drive quick engagement.
Q: Does Claude 4.7 have a longer context window than GPT-4o?
A: Yes. Claude 4.7 supports a 1,000,000-token context window, compared to GPT-4o’s 128K. That allows for full book-length synthesis in a single prompt. Note that retrieval accuracy can degrade for content in the middle third of very long contexts, so verify critical facts placed above the 100K threshold.
Q: Can Claude 4.7 handle structured content like tables and briefs?
A: It handles structured content well. The improved vision capabilities (2,576px resolution) allow it to parse complex tables, multi-column layouts, and structured briefs with high precision. For content teams working with data-dense visual assets, coordinate mapping accuracy is significantly improved over the previous version.
Q: How do I keep Claude 4.7 from going clinical when generating brand copy?
A: The default tone without explicit guidance tends toward direct and clinical. The fix is upfront: encode your brand voice in the system prompt with specific examples, a “do not use” word list, and sample sentences. Claude 4.7’s literalism works in your favor once the instructions are explicit. Don’t rely on it to infer tone from vague context.

