
Your domain authority is climbing. Your keyword rankings look stable. But when a potential buyer asks ChatGPT for a recommendation in your category, the response pulls three competitors, links to two industry blogs you’ve never heard of, and doesn’t mention your brand once. You check Perplexity. Same story, different competitors. The SEO dashboard says you’re winning. The AI says you don’t exist.
That disconnect isn’t a glitch. It’s a measurement gap. Traditional search metrics weren’t built to capture how LLMs decide which brands to cite, and most teams don’t yet have a system to track it. LLM citation tracking closes that gap by turning an opaque AI behavior into something measurable and actionable.
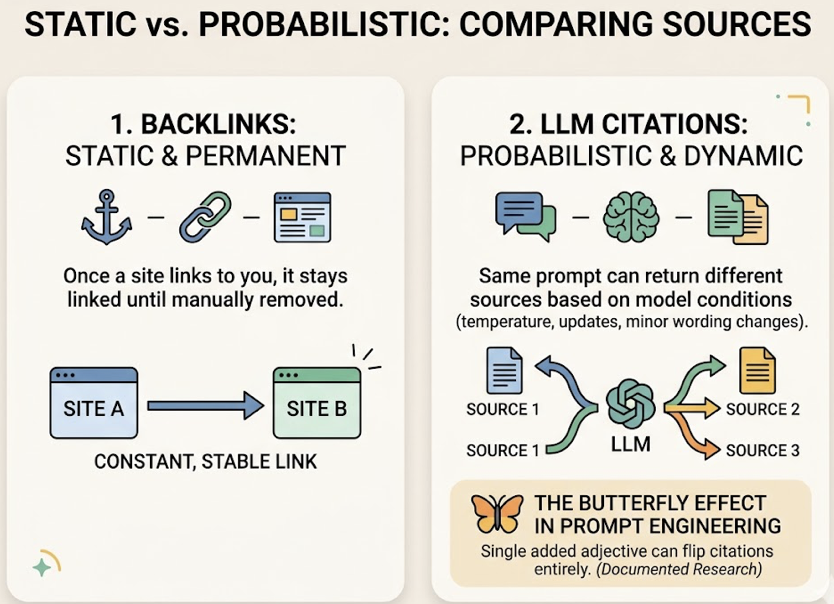
What LLM Citations Are and Why They Don’t Work Like Backlinks
An LLM citation happens when an AI engine references your brand, domain, or content in its generated response. It might appear as a clickable source link in Perplexity, a named recommendation in ChatGPT, or a cited domain in Google’s AI Overview. On the surface, it looks like a backlink. It isn’t.
Backlinks are static. Once a site links to you, it stays linked until someone removes it. LLM citations are probabilistic. The same prompt can return different sources depending on model temperature, retrieval index updates, and even minor wording changes. Research has documented what analysts call the “Butterfly Effect” in prompt engineering: a single added adjective can cause the model to flip its citations entirely.
The sourcing logic also varies dramatically across platforms. ChatGPT leans heavily on established reference sites, with Wikipedia appearing in nearly 48% of its top citation lists. Perplexity prioritizes recency and community validation, with Reddit accounting for over 46% of its top citations. Google AI Overviews maintain a 76% overlap with traditional organic rankings but weight YouTube and user-generated content far more than other engines.
That fragmentation is the core challenge. Only 60% to 65% of queries share even a single cited domain across Gemini, ChatGPT, and Perplexity. A brand winning citations on one platform can be completely invisible on another.
5 LLM Citation Metrics That Actually Tell You Something
Not all visibility is equal. A mention buried in a footnote carries less weight than a primary recommendation. Here are the five metrics that separate noise from signal in LLM citation tracking.
Citation Rate. The percentage of relevant prompts where an AI platform includes your domain as a source. Unlike a keyword ranking, which is binary, citation rate is statistical. If you’re tracking 100 high-value prompts and your brand shows up in 34 responses, your citation rate is 34%. Topify calculates this across ChatGPT, Gemini, Perplexity, and AI Overviews simultaneously, giving you a single cross-platform baseline.
Citation Position. Where your brand appears in the AI’s response matters as much as whether it appears at all. The first brand mentioned in an AI recommendation list earns significantly more trust and click-through than the third or fourth. Research shows the #1 ranked brand in AI mentions captures an average of 62% of total AI Share of Voice, and the gap between #1 and #3 is typically 5x.
Source Attribution. This tracks the specific domains and URLs the AI is citing when it talks about your category. If Perplexity is pulling from a Reddit thread you’ve never seen, or if ChatGPT trusts a competitor’s G2 page over your product page, source attribution tells you exactly where the authority gap lives.
Sentiment Context. Being cited isn’t always good news. A study published in Nature Communications found that between 50% and 90% of LLM-generated citations don’t fully support the claims they’re attached to. If an AI describes your premium product as a “budget alternative,” that visibility is a liability. Sentiment scoring evaluates whether AI platforms frame your brand positively, neutrally, or negatively on a 0-to-100 scale.
Citation Stability. LLM outputs are non-deterministic. Research into AI search volatility indicates that only about 30% of brands maintain consistent visibility across multiple regenerations of the same query. Citation stability measures how reliably your brand appears over repeated runs of the same prompt, separating durable authority from statistical flukes.
How to Set Up Your First LLM Citation Tracking Workflow
Tracking LLM citations isn’t a one-time audit. It’s a continuous loop. Here’s how to build the foundation.
Step 1: Build your prompt library. The unit of measurement in LLM citation tracking isn’t a keyword. It’s a prompt: a full-sentence, conversational query that often exceeds twenty words. Start by mapping four categories of prompts that mirror your buyer’s journey: awareness prompts (“Why is my team’s velocity dropping?”), consideration prompts (“What are the top 5 agile tools for developers?”), validation prompts (“Tool A vs Tool B for small teams”), and brand prompts (“Does [your brand] have SOC2?”). Pull language from sales transcripts, support tickets, and community forums. Then validate which prompts actually carry volume. Topify’s High-Value Prompt Discovery surfaces which conversational clusters are active and where competitors are currently capturing the narrative.
Step 2: Establish your baseline across platforms. Run your prompt set across ChatGPT, Perplexity, Gemini, and Google AI Overviews. Record which brands appear, in what order, and how they’re described. But here’s the catch: manual checks don’t scale. AI responses are probabilistic, meaning different users get different answers for the same query. Leading frameworks recommend running each priority query at least 10 to 20 times to establish a statistical baseline. Topify automates this by running real-time monitoring across thousands of prompts simultaneously, detecting visibility regressions with 92% sensitivity compared to 64% for manual monitoring.
Step 3: Map your citation gaps. Once you have a baseline, the question becomes: who’s showing up instead of you? Citation gap analysis identifies the specific pages and third-party platforms that AI engines currently trust for your category. If a competitor is cited because of a G2 review thread or a mention in a specific industry blog, getting your brand into that same source becomes a concrete target. Topify’s Source Analysis reverse-engineers exactly which domains and URLs each AI platform cites, so you can prioritize outreach with evidence rather than guesswork.
Step 4: Set your audit cadence. AI models update their retrieval systems frequently. A bi-weekly audit cadence is the minimum. Every optimization action, whether adding a statistic, updating a price, or earning a Reddit mention, should be tracked against changes in citation rate and response position. This creates a closed-loop system where visibility data directly informs the next cycle of content production.
The Prompts That Drive LLM Citations in Your Category
Not every prompt is worth tracking. The average AI query runs closer to 23 words, packed with specific qualifiers: budget constraints, industry verticals, company size, use-case scenarios. These qualifiers push an AI from “explanation mode” into “recommendation mode,” and that transition is where brands either get cited or get ignored.
The distinction between prompt types matters. Category-level prompts (“best CRM for small teams”) determine whether you make the shortlist. Brand-level prompts (“Does [your brand] integrate with Salesforce?”) determine whether the AI’s answer is accurate. Both need tracking, but they require different optimization strategies.
Here’s a pattern most teams miss: generative engines don’t just answer the prompt you type. They generate sub-questions internally to build a more complete response. A prompt about “best project management tools” might trigger the model to also retrieve information about pricing, integrations, and user reviews. If your content covers the primary topic but not those adjacent questions, you’ll lose the citation to a competitor whose content does.
Topify’s AI Volume Analytics shows which conversational clusters are active and provides a “Share of Model” indicator, so you’re building content around questions AI is actually being asked.
What Your Competitors’ LLM Citations Reveal About Your Gaps
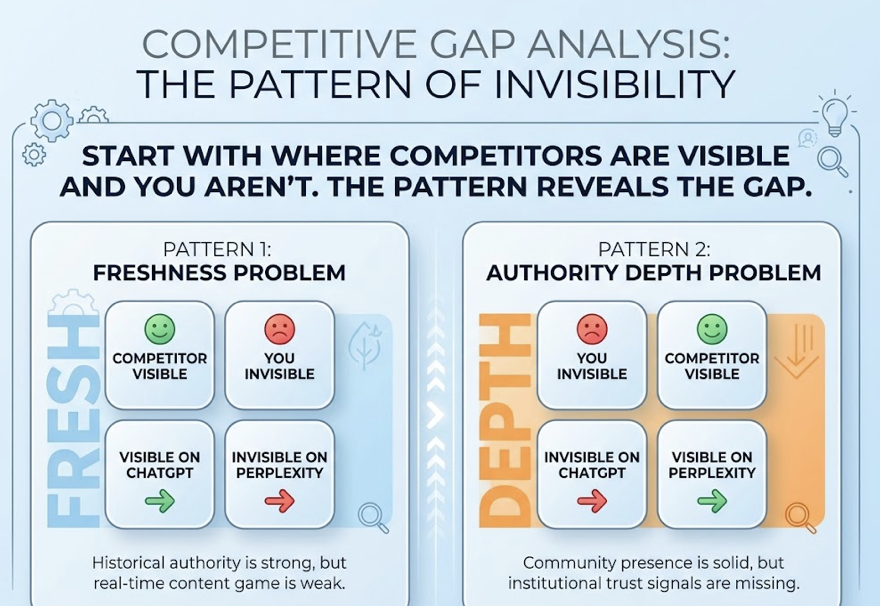
Competitive citation analysis isn’t just about knowing who’s ahead of you. It’s a diagnostic tool for understanding what the AI values in your category.
Start with the platforms where your competitors are visible and you aren’t. That pattern tells you the type of gap you’re dealing with. Visible on ChatGPT but invisible on Perplexity? That’s a freshness problem. Your historical authority is strong, but your real-time content game is weak. Visible on Perplexity but invisible on ChatGPT? That’s an authority depth problem. Your community presence is solid, but institutional trust signals are missing.
The sources themselves tell a clearer story than any aggregate score. If the AI is citing a competitor because of a specific Forbes mention, a G2 review cluster, or a Reddit thread, those aren’t abstract “content gaps.” They’re specific, targetable opportunities. In mature categories, top brands dominate nearly 86% of the consideration set in AI responses. If you’re not in that set, source-level data shows you exactly what’s keeping you out.
Topify’s Competitor Monitoring automatically detects your competitive set, compares Visibility, Sentiment, and Position side by side, and flags when a new competitor enters the AI’s recommendation set.
AI Competitor Analysis
3 Mistakes That Tank Your LLM Citation Tracking
Tracking mentions without tracking sources. Knowing your brand was mentioned in 40% of relevant AI answers is a start. But if you don’t know which domains the AI is using to justify those mentions, you can’t protect or expand your position. Source attribution is the layer that connects visibility data to content strategy.
Watching one platform and calling it done. Each AI engine runs a different retrieval pipeline. ChatGPT Search mode relies heavily on Bing’s index. Perplexity pulls from Reddit and real-time news. Gemini prioritizes pages that already rank well in traditional Google search. A single-platform approach leaves enormous blind spots. The Princeton GEO study demonstrated that a site ranking at position #5 on a traditional SERP could achieve a 115% visibility lift in an AI answer simply by improving its citatability, but that lift varies dramatically by platform.
Treating citation tracking as a one-time audit. Pages updated in the last 60 days are nearly twice as likely to appear in AI-generated answers as older content. AI systems continuously recalibrate. Research from the Princeton GEO study found that specific structural interventions, like adding expert quotations (+41% visibility boost) or statistics (+32% boost), directly improve citation likelihood. But those gains erode without ongoing monitoring. Brands that set-and-forget their content lose ground in real time to competitors who keep publishing.
Conclusion
The gap between SEO performance and LLM citation performance isn’t shrinking. As zero-click rates climb past 58.5% in the US and AI-referred visitors convert at rates up to 23x higher than traditional organic traffic, the brands that build citation tracking into their workflow now will compound that advantage over time.
The starting point is specific: build a prompt library, establish a cross-platform baseline, map your citation gaps, and set a recurring audit cadence. If you’re looking for an immediate snapshot, Topify’s free GEO Score Checker gives you a baseline of AI bot access, structured data, and content signals in under a minute. From there, continuous monitoring through the full Topify platform turns that snapshot into a system.
FAQ
Q: What is an LLM citation?
A: An LLM citation is when an AI engine like ChatGPT, Perplexity, or Gemini references your brand, domain, or content in its generated response. It can appear as a clickable source link, a named recommendation, or a cited domain. Unlike a backlink, LLM citations are probabilistic and can change with each query.
Q: How often should I check my LLM citations?
A: At minimum, bi-weekly for your core prompt set. AI models update their retrieval systems frequently, and citation patterns can shift within days. For high-priority prompts tied to revenue-driving queries, weekly monitoring is recommended. Automated tools provide continuous tracking that manual checks can’t match.
Q: Can I track LLM citations manually?
A: You can start manually by running prompts across ChatGPT, Perplexity, and Gemini and recording which brands appear. But manual tracking doesn’t scale: AI responses are non-deterministic, so a single check captures one snapshot of a probabilistic system. Professional tracking runs each prompt multiple times across platforms to calculate statistically reliable baselines.
Q: Which AI platforms should I track for citations?
A: At minimum, ChatGPT, Perplexity, Google AI Overviews, and Gemini. Each platform operates on a distinct retrieval model with different sourcing preferences. Research shows that only 60% to 65% of queries share even one cited domain across these platforms, so single-platform tracking leaves major blind spots.

