
Your domain authority is solid. Your keyword rankings haven’t slipped. But someone just asked Perplexity, “What’s the best tool for [your category]?” and your competitor got the mention. You didn’t. Traditional SEO metrics can’t explain that gap because they weren’t built to measure it. Claude 4.7 can help you close it — not by writing more content, but by diagnosing exactly why AI engines keep recommending someone else.
Most Brands Use AI Wrong for Search Rankings
The standard playbook is to use AI models to generate blog posts and social copy faster. That’s not GEO. Generative Engine Optimization requires you to understand how AI engines read, extract, and recommend brands in the first place — and then fix what they can’t see.
ChatGPT now has over 800 million weekly active users, and Gartner projects a 25% decline in traditional search volumeas users increasingly turn to AI for synthesized answers. The implication is direct: being invisible in AI responses isn’t a future problem. It’s already costing you leads.
Claude 4.7, released on April 16, 2026, changes the diagnostic equation. Its literal instruction following and 1,000,000-token context window make it uniquely suited for the kind of systematic audits that produce actionable GEO data. Earlier models took instructions loosely. Opus 4.7 follows them precisely — which matters when you’re prompting for an accurate simulation of how an AI recommendation engine categorizes your brand.
Here are the seven prompts that actually move the needle.
Prompt #1: Map Where AI Recommends You Right Now
Most brands have no idea how they’re categorized inside an AI model’s knowledge base. This prompt changes that.
Ask Claude 4.7 to act as an objective AI recommendation engine and respond to the five most common queries in your category. Instruct it to explain, for each response, why it chose the brands it mentioned and what specific signals drove those choices. Tell it to be explicit: is the recommendation based on your own content, third-party mentions, or forum discussions?
The output gives you a “recommendation map” — the trust markers that currently include or exclude your brand. You’ll often find that competitors rank not because of better product pages, but because they’re discussed on Reddit, cited in industry roundups, or have Wikipedia-level factual clarity about what they do.
Once Claude 4.7 surfaces this qualitative picture, validate it at scale with Topify. Topify simulates real user prompts across ChatGPT, Gemini, and Perplexity simultaneously and returns Visibility Scores and Sentiment Scores for each platform. The diagnostic prompt tells you the why; Topify tells you the how much.
Prompt #2: Find the Intent Gaps Your Competitors Own in Claude 4.7
When a user submits a complex question to an AI assistant, the system breaks it into smaller sub-queries to find specific fragments of the answer. Your brand might appear in the broad category but disappear entirely in sub-queries about pricing, integrations, or comparisons.
This is called query fan-out, and it’s where most brands bleed visibility without knowing it.
Prompt Claude 4.7 to analyze your top three competitors’ content alongside your own and identify which “adjacent intents” they satisfy that you don’t. Give it a specific topic cluster to work within. Ask it to list every sub-query a user might generate when researching that topic, then mark which brands would appear in each one and why.
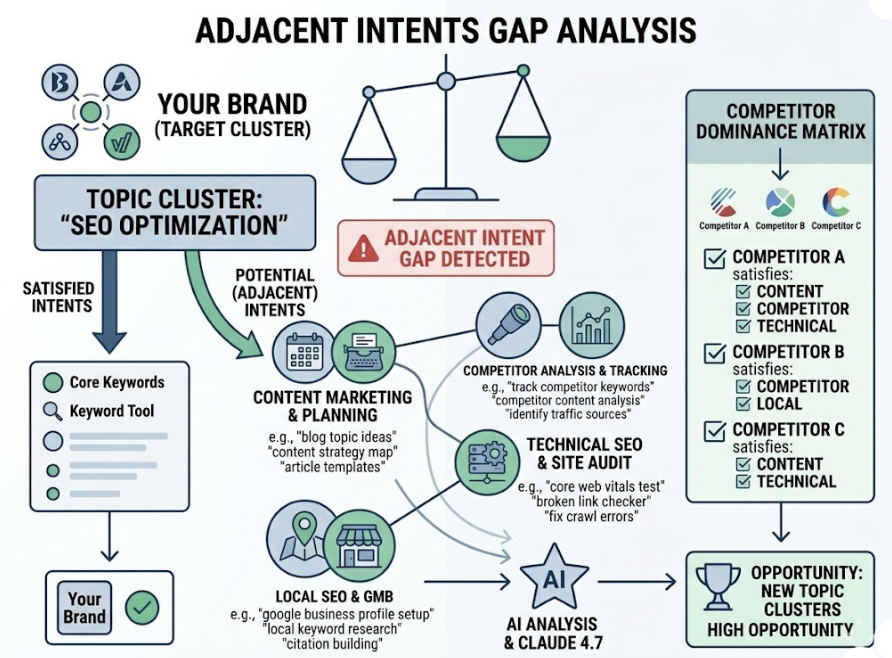
A specification gap — missing comparison tables or detailed integration documentation — means a competitor will get cited every time a user asks “does X work with Y?” A trust gap means your claims appear in your content but nowhere else, so AI engines discount them.
Topify’s AI Volume Analytics can then quantify which of these sub-queries carry actual search volume, so you prioritize the gaps that cost you the most.
Prompt #3: Reframe Your Product Description for Claude 4.7 and Other AI Engines
AI engines don’t read marketing copy the way humans do. They convert text into vector embeddings — mathematical representations that determine how closely your content matches a user’s query. Promotional language, vague superlatives, and context-dependent phrasing all produce weak embeddings.
That means “we help teams move faster” is nearly invisible in AI retrieval. “Platform X reduces sprint cycle time by 23% for teams of 10-50 engineers” is highly extractable.
Prompt Claude 4.7 to surgically edit your product descriptions using the following constraint: every sentence must be able to stand alone as a self-contained, verifiable answer to a specific question. No pronouns without clear referents. No adjectives without measurable backing. No “learn more” without telling the reader what they’d learn.
The before-and-after difference is stark. “Our solution helps you grow” becomes “Brand Y’s platform increases pipeline conversion rates by 15% according to its 2025 customer cohort study.” The second version gets cited. The first gets filtered out.
This isn’t just a copy edit. It’s a fundamental rewrite for Retrieval-Augmented Generation, the pipeline that most frontier AI engines — including those powering ChatGPT and Perplexity — use to construct their answers.
Prompt #4: Extract Citation-Worthy Claims from Your Existing Content
Here’s the thing: many brands already have the data needed to win AI citations. It’s buried in whitepapers, case studies, and product documentation under layers of marketing language.
Content featuring original statistics achieves a 30-40% higher visibility lift in generative engine responses. The problem isn’t usually that the data doesn’t exist — it’s that it isn’t formatted for extraction.
Prompt Claude 4.7 to audit a set of your internal documents and extract every statement that could function as a standalone answer to a common industry question. The criteria: each claim must include a specific number, a timeframe, or an attribution to an authoritative source. Vague claims don’t qualify.
Then use the output to build a “citation asset list” — a structured document of your most quotable facts, each formatted as a standalone sentence. Publish these prominently across your website, press kit, and any content you’re trying to get AI engines to cite.
Proprietary research drives roughly 40% higher citation rates. If you have internal data on customer outcomes, usage patterns, or category benchmarks, this prompt will help you identify and surface it.
Prompt #5: Build a Brand Narrative Claude 4.7 Can Actually Read
AI models build an “entity graph” of every brand they encounter — a structured representation of what a brand is, what it does, and how it relates to adjacent topics. If your narrative is fragmented across platforms, the model assigns lower confidence to recommendations.
Consistency isn’t just good branding. It’s an algorithmic requirement.
Prompt Claude 4.7 to audit your About page, LinkedIn summary, and top-traffic blog posts for entity clarity. Ask it to evaluate: Is it unambiguous what category this brand belongs to? Can the AI determine who the primary competitors are? Are the brand’s core claims consistent across all three sources, or do they conflict?
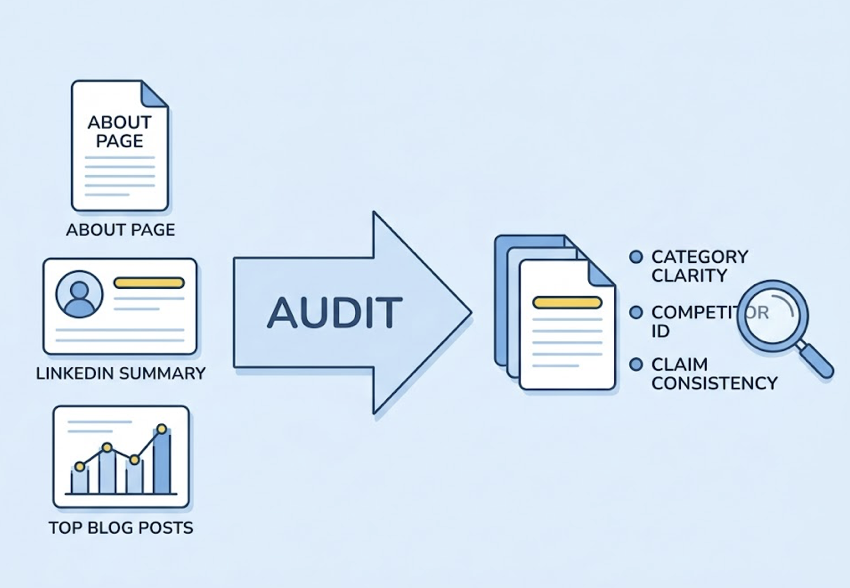
The output will reveal entity inconsistencies you didn’t know existed. A brand that calls itself “an AI-powered analytics platform” on its homepage but “a data intelligence tool” on LinkedIn creates ambiguity in the AI’s entity graph — and ambiguity reduces citation confidence.
The fix is to write in modular, 40-60 word paragraphs that make sense even when extracted independently, and to explicitly name the categories, tools, and industry standards you want to be associated with. Topify’s Sentiment Analysisflags when AI engines are describing your brand inconsistently across platforms, making it easy to catch drift before it compounds.
Prompt #6: Audit Your FAQ for AI Visibility
FAQ sections are among the most frequently cited content formats across every major AI platform. Their structure — a direct question followed by a direct answer — mirrors the input-output logic of AI assistants almost perfectly.
Pages with dedicated FAQ sections that include FAQPage schema are 3.2 times more likely to appear in AI Overviews.Most FAQ pages don’t have schema. Most FAQ answers bury the key information in the third paragraph.
Prompt Claude 4.7 to analyze your existing FAQ against two criteria. First: are the questions phrased the way users actually ask them in conversation, or the way your marketing team thinks about your product? Second: does each answer lead with a concise 1-2 sentence summary that could stand alone as a complete response?
Ask Claude 4.7 to rewrite three of your weakest FAQ entries as examples. The difference between “What are your pricing options?” and “How much does Platform X cost for a team of 10?” is significant — the latter matches conversational AI query patterns.
Also prompt it to flag any FAQ entries that contain named entities without specifics. “We integrate with popular tools” is unfindable. “Platform X integrates with Salesforce, HubSpot, and Slack via native connectors” is highly extractable.
Prompt #7: Generate a GEO Content Brief That AI Will Actually Cite
The last prompt is the most structural. Instead of optimizing existing content, use Claude 4.7 to build a brief for new content that’s designed for AI citation from the first sentence.
A traditional SEO brief specifies keyword frequency and word count. A GEO brief specifies extractability, verifiability, and intent coverage.
Prompt Claude 4.7 to analyze the current top-cited source for a query in your category and generate a content brief that addresses every weakness it finds. Likely gaps: no original data, a promotional opening that AI engines filter out, a heading structure that doesn’t map to the sub-queries users actually generate.
The brief should mandate a “Bottom Line Up Front” opening of 30-50 words, at least one structured comparison table, a minimum of three externally verifiable data points, and a heading hierarchy that maps to five or more adjacent user intents.
44.2% of AI citations occur within the opening section of a piece, and content with strict H1-H2-H3 logical flow is 2.8 times more likely to be cited. That’s not a style preference. It’s an architectural requirement.
How to Measure Whether These Claude 4.7 Prompts Are Working
Running these prompts without a measurement layer is the same as running an SEO campaign without Google Search Console. You’ll be optimizing blind.
Topify tracks brand Visibility Scores, Sentiment Scores, and Position Rankings across ChatGPT, Gemini, Perplexity, and 10+ additional AI platforms simultaneously. After implementing changes based on any of the seven prompts above, you can monitor week-over-week shifts in how frequently your brand appears and whether AI engines are describing it accurately.
The Source Analysis feature is particularly relevant here. It reverses the AI’s citation logic to surface exactly which URLs and domains are driving mentions in your category. If a competitor is consistently cited because of a single industry report or Reddit thread, you can see that — and plan accordingly.
That’s what separates GEO from guesswork. The prompts identify what to change. Topify’s Visibility Tracking tells you whether the changes worked.
Conclusion
Claude 4.7’s literal instruction following makes it a reliable diagnostic engine — not just a content generator. These seven prompts work because they force the model to simulate how AI engines think, not just help humans write faster.
The brands that build AI search visibility in 2026 won’t outspend their competitors on content volume. They’ll outstructure them: clearer entity graphs, denser factual claims, FAQ sections that answer questions AI users actually ask. Run these prompts, implement the fixes, and use Topify to track what moves. Get started here.
FAQ
Q: Is Claude 4.7 better than GPT-5 or Gemini for GEO prompting?
A: For diagnostic GEO work, Claude 4.7 has a measurable edge. Its literal instruction following reduces the “hallucination of intent” that makes other models interpret prompts loosely, and its 1,000,000-token context window lets you run full-site audits in a single session. On the SWE-bench Verified benchmark, Opus 4.7 reached 83.5% accuracy versus GPT-5.4’s 76.9%, which reflects its stronger adherence to structured, multi-step tasks. For generating prose content at scale, GPT-5.5 and Gemini 3.1 are also strong options, but for precision audits, Claude 4.7 is the more reliable tool.
Q: How often should I run these prompts?
A: Run Prompts #1 and #2 (recommendation mapping and intent gap analysis) every 4-6 weeks, as AI citation patterns shift with model updates and new content entering the web. Prompts #3, #5, and #6 (description reframing, narrative audit, FAQ audit) are best run quarterly or after any major product or messaging change. Prompts #4 and #7 (claim extraction and content briefing) can run on an ongoing basis as you publish new content.
Q: Do these prompts work for optimizing presence in ChatGPT and Gemini, not just Claude?
A: Yes. The prompts use Claude 4.7 as a diagnostic engine, but the output applies to all AI platforms. ChatGPT’s citation logic has only a 6.82% overlap with Google’s top 10 results, while Gemini-powered AI Overviews overlap 17-53%. That means you need platform-specific visibility data — which is where Topify’s cross-platform tracking becomes essential for translating diagnostic insights into platform-targeted actions.
Q: What’s the single highest-impact change most brands can make today?
A: Rewrite your most-trafficked product or service page to be answer-first and entity-explicit (Prompt #3). It’s the change with the broadest impact across all AI platforms because it directly affects how your content is processed during RAG retrieval — the mechanism that determines whether your brand gets extracted and cited, or passed over.

