
You tripled your content output this quarter. You used Claude 4.7, tightened your editorial process, and published faster than ever. Then you checked how your brand shows up in ChatGPT, and the answer was the same as three months ago: it doesn’t.
The problem isn’t the volume. It’s not even the quality. It’s that producing content with AI and getting cited by AI are two completely different games, and most marketing teams are only playing one of them.
The Citation Gap Nobody Talks About
AI-generated content is flooding the web, but almost nobody is tracking whether that content actually earns citations from AI engines. Most brands are still optimizing for keywords and backlinks while ChatGPT, Perplexity, and Google AI Overviews operate on an entirely different logic.
These platforms don’t rank pages. They extract “fact units” that reduce the risk of hallucination. What gets cited isn’t the most polished content — it’s the most extractable content. And there’s a meaningful gap between the two.
The data confirms the asymmetry. Only 28% of brands manage to earn both a mention and a citation link in the same AI response. The rest become background fuel: their data gets used, but the recommendation goes to someone else. In travel, for example, AI-referred visitors convert at 4.5x the rate of traditional search traffic — but fewer than 10% of brand websites earn direct citations. The rest get displaced by Reddit threads and TripAdvisor reviews.
This is the citation gap. You might be feeding AI systems with your content, without ever showing up as the answer.
Why Claude 4.7 Doesn’t Automatically Fix This
Claude 4.7 Opus is a meaningful upgrade. It handles long-document reasoning, legal text analysis, and agentic workflows at a level that earlier models couldn’t match — reducing errors by 21% on complex reasoning benchmarks compared to its predecessor.
But here’s the thing: citation decisions don’t happen at the generation layer.
When a user submits a prompt to ChatGPT, the retrieval system scans an indexed pool (primarily Bing) for fact-dense sources before the generation model writes a word. Claude 4.7’s improvements in tone, nuance, and long-context coherence have no direct influence on whether that retrieval system selects your content as a source.
The table below makes the gap concrete:
| Dimension | Claude 4.7 Upgrade | AI Citation Requirement |
|---|---|---|
| Reasoning quality | 21% fewer logical errors | Entity consistency across domains |
| Output clarity | High instruction-following | BLUF structure (answer in first 300 words) |
| Visual reasoning | 3.3x better image processing | Multimodal data increasingly cited |
| Self-verification | Built-in validation steps | High-authority external source links |
Better writing tools improve human readability. Higher AI citation rates require machine extractability. The two overlap, but they’re not the same thing.
5 Reasons ChatGPT Ignores Your Content
It Looks Like Every Other AI Output
AI retrieval systems are built around risk minimization. If your content is assembled from widely available information — no original data, no first-person expert perspective — it occupies the same semantic space as thousands of similar pages. That makes it “zero information gain” content, and retrieval algorithms deprioritize it accordingly.
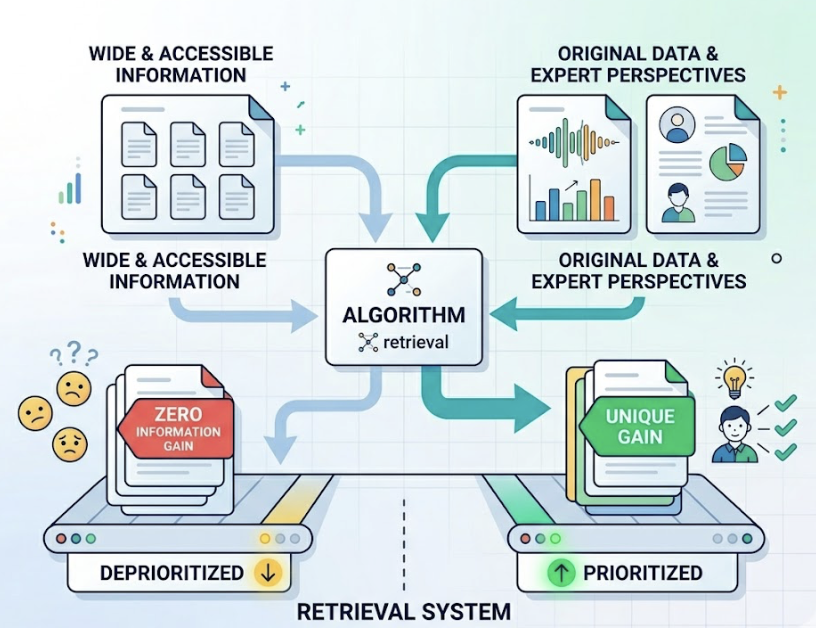
Research from Princeton and Georgia Tech found that pages offering proprietary statistical data earned 41% higher AI visibility than pages summarizing publicly available information. If your content is smooth and frictionless, it’s also invisible. AI systems look for sources that add something they can’t already synthesize from their training weights.
No Authoritative Signals Attached
ChatGPT doesn’t just evaluate content — it runs a background check on the entity producing it. This is the “entity handshake” mechanism, and it’s where most AI-generated content fails silently.
Signals that raise a source’s citation probability include verified author profiles (LinkedIn credentials, published bylines), Organization schema with sameAs links pointing to Wikipedia and LinkedIn, and FAQPage schema that directly embeds Q&A pairs. Pages ranked 6th–10th on Google with strong E-E-A-T signals earn AI citations at 2.3x the rate of first-ranked pages without them. Ranking isn’t the filter. Verified identity is.
It Lives on the Wrong Domains
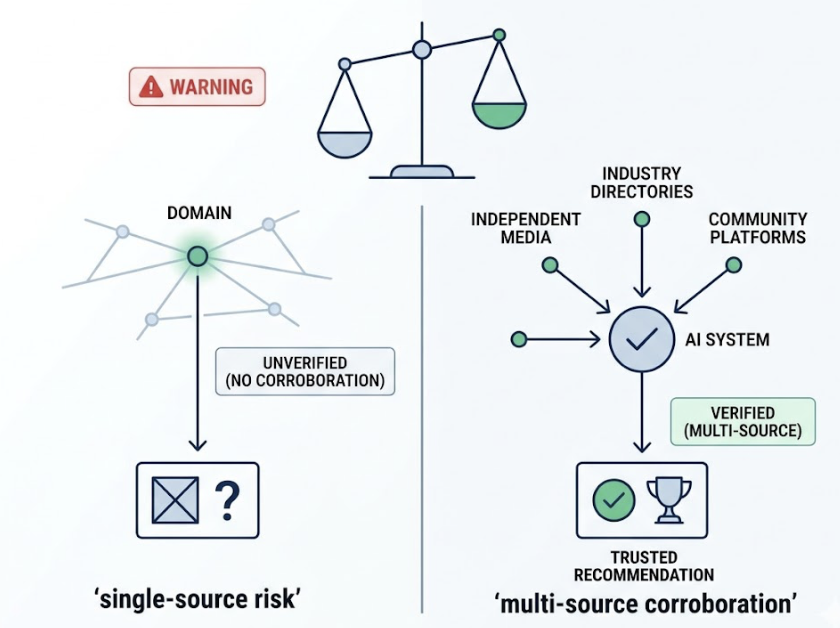
Where your content lives matters as much as what it says. ChatGPT’s citation patterns show strong third-party preference: approximately 47.9% of top citations point to Wikipedia, while Perplexity sources 46.7% of its citations from Reddit. Brand websites account for roughly 9% of AI citations on average.
Content that exists only on your domain, without corroboration from independent media, industry directories, or community platforms, triggers what AI models treat as “single-source risk.” The system looks for multi-source corroboration before committing to a recommendation. If your brand is mentioned in only one place, it doesn’t meet that threshold.
ChatGPT Has Already Seen Better Versions
AI citation networks have a first-mover advantage built in. Once an authoritative source — an industry association, a tier-one publication, an established benchmark study — establishes the “ground truth” on a topic, subsequent content needs to introduce significantly new facts or a better structure to displace it.
On top of that, citation decay accelerates after 90 days without updates: pages that go stale lose citation probability at roughly 3x the rate of actively updated pages. And in the first 3–5 days after publication, a page either enters the retrieval pool or it tends to stay out. The window is narrow.
You’re Not Tracking Which Prompts Trigger Citations
Most teams are optimizing for keywords. ChatGPT is operating on prompt vectors — and they’re not the same thing.
When a user submits a question, ChatGPT typically generates 3–5 sub-queries internally before constructing a response. Close to a third of all citation opportunities occur in those hidden sub-queries, which traditional keyword tools can’t see. If you don’t know which prompts are triggering citations in your category, you don’t know what you’re actually competing for. You’re publishing content aimed at the wrong target.
What AI-Citable Content Actually Looks Like
The gap between “well-written content” and “AI-citable content” comes down to three structural properties.
Fact density. Pages that include at least one specific statistic per hundred words earn 37% higher AI visibility than those relying on qualitative descriptions. Numbers give AI systems something concrete to extract without hallucination risk.
Direct answers up front. 44.2% of AI citations pull from the first 30% of an article. The traditional “build-up to the point” structure is one of the most common citation killers. BLUF (Bottom Line Up Front) — a clear 40–60 word summary immediately under the H1 — dramatically increases the probability that a retrieval system captures your core claim before moving on.
Structure that machines can parse. Comparison tables earn the highest citation probability of any content format, because they’re already structured data. Ordered lists and definition blocks follow closely. Long-form narrative content — even when it’s excellent — scores low because the semantic extraction cost is high.
| Content Format | AI Citation Probability | Why |
|---|---|---|
| Comparison tables | Highest | Pre-structured data, easy to convert to summaries |
| Ordered lists / steps | Very high | Matches instructional answer formats |
| Definition blocks | High | Creates direct entity-attribute mappings |
| Expert quotes with attribution | High | Provides non-synthetic human experience signal |
| Narrative long-form | Low | High semantic noise, extraction cost |
Topify‘s Source Analysis tool is built around this kind of reverse engineering. Rather than showing you whether your brand appeared in AI responses, it shows you which domains AI cited when answering prompts in your category, what content formats those pages used, and where your competitors are earning citations you’re not. That’s the intelligence you need before you write another word.
How to Track Whether ChatGPT Is Citing You Right Now
Manual spot-checking doesn’t work at scale. AI responses are non-deterministic: the same query returns different citations at different times and across different geographic locations. A snapshot tells you nothing about your actual citation rate.
The right approach is a structured prompt matrix — typically 150–300 high-intent prompts covering informational (“what is X”), comparative (“X vs Y”), and decision-stage queries (“best tool for [use case]”). You need to monitor this at least weekly, because AI citation turnover runs between 40–60% per month.
Topify’s Visibility Tracking simulates thousands of real user prompts across ChatGPT, Perplexity, Gemini, and other platforms, generating a probabilistic Visibility Score for your brand. It also surfaces “ghost prompts” — queries with minimal search volume but high AI interaction frequency that represent undercovered citation opportunities. These are often the highest-value targets, precisely because no one is competing for them yet.
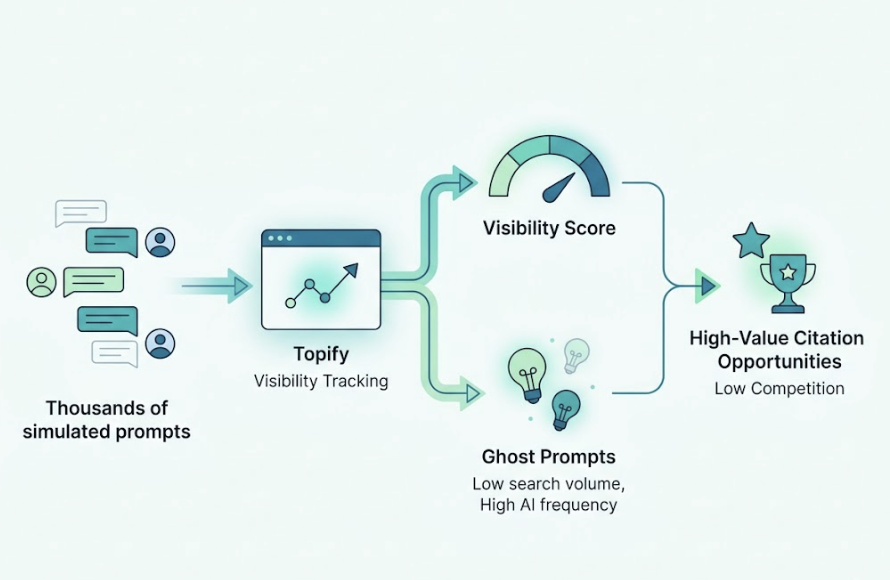
The companion metric is AI Volume Analytics. Traditional SEO tools estimate demand based on click data, but in AI search, a large share of queries never produce a click — the answer is delivered inline. Topify’s AI Volume Analytics estimates conversational demand by analyzing LLM interaction patterns, giving you a picture of what users are actually asking AI, not just what they’re typing into Google.
A Three-Direction Fix That Works Across AI Platforms
You don’t need to rebuild your content library. You need to add the signals that AI systems use to evaluate whether your content is citation-worthy.
Direction 1: Signal strengthening. This means establishing entity consistency across the web. Your brand name, address, and category descriptors should be identical across social profiles, industry directories, Wikipedia (if applicable), and your own schema markup. Deploy Organization schema with sameAs linking to your LinkedIn and any external reference pages. Add author profiles that include verifiable credentials — a byline connected to a LinkedIn profile with clear professional history changes how AI models assess the human authority behind the content.
Direction 2: Channel calibration. Different AI platforms have different source preferences. ChatGPT’s deep integration with Bing means your Bing index presence directly affects ChatGPT citation probability. Google AI Overviews increasingly incorporates YouTube content, so video assets aren’t optional for Google AI visibility. And brands active in Reddit and Quora communities earn 3x the citation frequency of brands with no community presence — the platforms AI trusts most are the ones where real people have left verifiable traces of your brand.
Direction 3: Citation-friendly architecture. Every page targeting AI citation should open with a 40–60 word BLUF summary. Paragraphs should average 2–4 sentences, each carrying one discrete fact. Adding a llms.txt file to your root directory — a Markdown-formatted index of your most citation-worthy pages — gives AI crawlers a structured map to your best content at minimal processing cost.
Topify’s One-Click Execution connects these three directions to automated action. When the system detects a citation gap — say, a competitor earning a citation in “2026 CRM comparison” queries through a structured table you don’t have — it generates a specific optimization recommendation and can implement it with a single approval. The goal isn’t just diagnosis. It’s closing the gap before the next citation cycle.
Conclusion
Claude 4.7 makes you a faster, sharper writer. It doesn’t make your content more citable.
The brands closing the citation gap in 2026 aren’t the ones producing the most content — they’re the ones who understand that AI systems select for trust signals, not quality signals. Fact density, entity verification, third-party corroboration, and structural extractability are the levers that matter. Until those are in place, more content just means more invisible content.
Start by finding out where your brand actually stands. Run a prompt audit. Check which domains are earning the citations in your category. Build the signal layer that AI retrieval systems are looking for. The output will follow.
FAQ
Q: Does using Claude 4.7 directly improve my AI citation rate?
A: Not directly. Citation decisions are made by the retrieval layer (the RAG pipeline), which evaluates fact density, E-E-A-T signals, domain authority, and structural extractability — not the rhetorical quality of the prose. Claude 4.7 improves content quality from a human-readability standpoint, but that’s a separate variable from what AI retrieval systems measure.
Q: What types of content does ChatGPT prefer to cite?
A: ChatGPT has a strong preference for content with high fact density, direct answers in the first 300 words, structured formats (tables, lists, definition blocks), and multiple third-party corroborations. It also weights pages that include verified author entities and Organization schema. Consensus sources — Wikipedia, official standards bodies, G2, and Capterra data — carry disproportionate citation weight.
Q: How fast does AI citation status change?
A: Faster than most teams expect. Citation turnover across AI platforms runs 40–60% per month. A page that earned citations in January may not be earning them in March if a competitor published fresher data or a better-structured source entered the retrieval pool. Weekly monitoring, not quarterly audits, is the right cadence.
Q: How do I find out which domains ChatGPT is citing in my category?
A: Manual spot-checking gives you anecdotes, not patterns. The systematic approach is to use a tool like Topify Source Analysis, which aggregates citations across thousands of AI responses in your topic area, categorizes sources by domain type (brand site, third-party review, community platform), and identifies the specific citation gaps where competitors are outranking you. That’s where your content and PR strategy should focus first.

