
Most marketing teams tracking AI search visibility hit the same wall around week three. The Monday morning spot-check across ChatGPT, Perplexity, and Gemini that started as a 30-minute task has ballooned into 20 to 30 hours of manual querying per week. Multiply that across 50 monitored prompts, each requiring 10 to 20 repeat runs for statistical reliability, and you’re looking at a full-time analyst doing nothing but copy-pasting queries into chat windows.
That’s the exact workload an AEO agent compresses into a structured, auditable weekly cycle. Not by removing human judgment, but by concentrating it at five specific decision points across five days.
Monday: Baseline Scan and Why Your Visibility Score Shifted Overnight
The week starts with drift detection, not dashboards.
An AEO agent doesn’t log into a platform and wait for you to ask questions. It runs an automated baseline scan across every prompt in your monitored portfolio before your team opens their laptops. The scan measures the statistical shift in brand representation compared to the previous week, not the absolute numbers.
Why relative drift matters more than raw scores: only 30% of brands maintain visibility from one AI-generated answer to the next. Across five consecutive runs of the same query, that number drops to 20%. Volatility is the default state, which means a single Monday snapshot tells you almost nothing without last week’s data as a reference point.
Topify’s agent scans across seven core metrics: Visibility Score, Sentiment Score, Position Rank, AI Search Volume, Mention Rate, Intent Analysis, and Conversion Visibility Rate (CVR). Each one captures a different layer of how AI engines perceive your brand. A drop in Position Rank from #2 to #5 on a high-volume transactional prompt is a different kind of problem than a Sentiment Score sliding from +60 to +30.
The agent compiles all flagged anomalies into a prioritized Drift Report. You review it. You decide whether a drop warrants a deep drill-down or gets logged as normal variance. That’s Monday’s human checkpoint: 15 minutes of strategic triage, not 4 hours of manual data collection.
Tuesday: Your AEO Agent Audits the Prompts You Should Be Tracking
Users don’t type keywords into ChatGPT. They write full sentences, sometimes full paragraphs. The average AI search prompt runs 23 to 60 words, packed with context like budget constraints, tech stack requirements, and team size.
Those prompts shift constantly. A query that drove 500 monthly AI searches last quarter might be irrelevant now. A new prompt phrasing might be surging and your competitors are already showing up in answers for it.
On Tuesday, the agent audits your active prompt portfolio using a weighted scoring model. Each candidate prompt gets an Opportunity Score based on four factors: AI Query Volume (30% weight), Visibility Gap (25%), Commercial Intent (25%), and Content Readiness (20%). The Visibility Gap score spikes when your brand is completely absent but competitors are actively recommended. Content Readiness evaluates whether your existing pages can realistically support the query.
The output is a shortlist: prompts to add, prompts to retire, and a clear rationale for each. Your job is to approve or adjust the list, making sure the tracking budget maps to your actual marketing priorities. That takes roughly 10 minutes, not the hours it would take to manually research prompt trends across four AI platforms.
Wednesday: Where Your Citations Break and What to Fix First
Here’s the thing about generative search engines: they don’t share sources. Only 11% of web domains get cited by both ChatGPT and Perplexity. ChatGPT leans heavily on commercial .com domains, with Wikipedia anchoring 47.9% of its top 10 sources. Perplexity has an extreme bias toward fresh content, with 82% of cited URLs updated within 30 days, and Reddit accounting for 46.7% of its top sources. Gemini pulls 34% of its responses entirely from pre-training weights with zero live web retrieval.
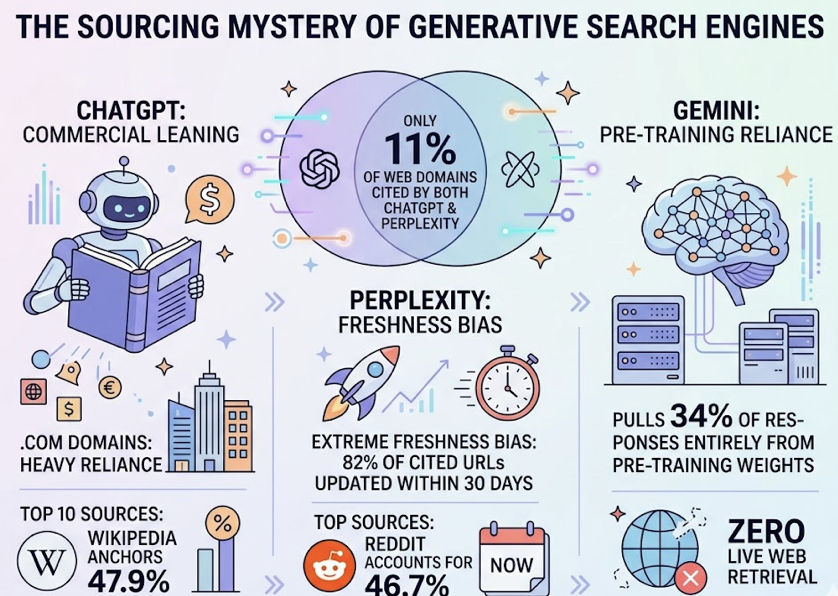
That fragmentation is why Wednesday’s content gap analysis matters. The agent cross-references your visibility data with citation source data, prompt by prompt. When a competitor gets recommended for a query where you’re absent, the agent traces the citation trail back to the specific URLs that powered that recommendation.
Then it outputs actionable fixes, ranked by impact. The highest-priority recommendations typically include placing a dense, direct answer in the first 150 words of your key pages. 55% of Google AI Overview citations and 44.2% of ChatGPT citations pull from the top 30% of a page. Converting qualitative comparisons into HTML data tables also ranks high, since tables get cited 2.5 times more frequently than equivalent plain-text paragraphs.
Wednesday’s human checkpoint: the content team reviews the prioritized fix list, approves specific pages for production, and assigns owners. The agent built the analysis. Your team decides what ships.
Thursday: The Competitor Signals Your AEO Agent Catches First
Traditional competitive tracking watches keyword rankings and backlink profiles. That’s almost useless in generative search. LLMs group brands by semantic relationships, not keyword matches. A competitor might gain ground in AI recommendations because of a positive G2 review wave or a Wikipedia edit, months before those signals show up in Google rankings.
Thursday is when the agent maps competitor movement across a six-step process: entity extraction (who’s emerging in your category), recommendation frequency benchmarking (daily mention trends), share of voice segmentation (platform-by-platform), trigger word association (which prompt phrasings favor competitors), citation source auditing (the specific Reddit threads, G2 pages, and media articles powering their visibility), and threat prioritization.
That last step is where it gets practical. Branded domains account for only about 9% of all LLM citations. Third-party sources dominate. So the agent doesn’t just tell you a competitor surged. It shows you which Reddit threads, which review sites, and which industry listicles are fueling that surge, and suggests specific off-page tactics to close the gap.
Thursday’s decision point: your team evaluates whether a competitor’s movement warrants a counter-positioning campaign or a content priority shift. The agent flags the threat and drafts the playbook. You decide whether to execute.
Friday: What “One-Click Deploy” Actually Means for an AEO Agent
Friday is execution day, but “one-click” doesn’t mean autopilot.
The agent aggregates every validated recommendation from the week into a single, prioritized execution queue. A typical Friday queue contains three on-page content optimization updates (fully drafted paragraphs designed for answer capsules on critical landing pages), one schema and metadata configuration (pre-compiled FAQPage or Product JSON-LD ready for deployment), and two competitor counter-strategies (flagged third-party citation targets with pre-structured response outlines).
Each item in the queue is pre-compiled, structured, and formatted for your CMS. The marketing manager reviews each edit, adjusts copy for brand voice, rejects anything low-impact, and publishes approved changes to WordPress, Shopify, or Framer with a single confirmation.
That’s the real meaning of one-click execution: the agent did 95% of the preparation work. The human applies 5% of strategic judgment. The result ships in minutes, not days.
Weekend: The Agent Keeps Scanning. You Don’t.
The agent doesn’t take weekends off. It continues simulating searches, tracking citations, and ingesting data across every monitored platform. It just doesn’t send you notifications.
This matters because citation performance for unrefreshed content typically drops to 40% of its initial level within 90 days. Algorithm changes and competitor updates don’t pause on Saturday. When your team logs in Monday morning, the baseline scan is already complete. Any visibility shifts from the weekend are flagged, analyzed, and waiting in the Drift Report.
The weekly cycle is a loop, not a line.
What Happens When You Scale from 50 Prompts to 500
At 50 prompts, a skilled analyst can manage AEO with spreadsheets and manual spot-checks. At 500, the math breaks.
Tracking 500 prompts across four AI engines means running 2,000 separate search queries per week. Factor in the 10 to 20 repeat runs needed for statistical reliability, and you’re looking at 40,000 queries. That’s an estimated 150+ hours of manual labor per week, which is roughly four full-time analysts doing nothing but querying chat windows.
There’s also a geographic blind spot. Most manual tracking focuses on Western LLMs. But global brands need coverage across Chinese AI engines like DeepSeek, Doubao, and Qwen, which mention brands at an 88.9% rate for English-language queries. Ignoring that ecosystem means missing a significant share of AI-driven brand discovery.
An agent-driven approach compresses that 150-hour workload into roughly 2 hours of strategic oversight per week. It auto-adjusts tracking frequency based on prompt performance: high-volume transactional prompts get daily checks, stable informational queries shift to weekly. Topify’s tiered plans scale from 50 daily monitored prompts at $99/month to 300+ prompts at the Pro level, with enterprise options for custom volumes.
The agent’s value at scale isn’t speed. It’s focus. Your team stops logging data and starts making decisions.
Conclusion
The gap between “we have an AEO strategy” and “our AEO agent runs a structured weekly cycle” is the gap between intention and execution. Monday’s drift scan, Tuesday’s prompt audit, Wednesday’s citation analysis, Thursday’s competitor intelligence, and Friday’s one-click deploy form a repeatable loop where every human intervention happens at a defined checkpoint, not in a reactive scramble.
If your team is still manually querying AI engines to check brand visibility, the bottleneck isn’t insight. It’s operational overhead. An AEO agent doesn’t replace your judgment. It gives you a clean, prioritized surface to apply it. Start with Topify to see what that weekly cycle looks like with your own prompt portfolio.
FAQ
Q: What is an AEO agent?
A: An AEO agent is an autonomous software framework that tracks, audits, and improves your brand’s visibility within AI answer engines like ChatGPT, Perplexity, Gemini, and Google AI Overviews. It automates query simulation, citation mapping, content gap identification, and structured update deployment, while keeping humans in the loop for every strategic decision.
Q: How much human oversight does an AEO agent need?
A: Roughly 1 to 2 hours per week. The heaviest checkpoints are Monday’s Drift Report review and Friday’s execution queue approval. The agent handles all data collection, analysis, and draft preparation. You handle the “yes, no, or adjust” decisions.
Q: Can an AEO agent replace my content team?
A: No. An AEO agent automates structural optimizations, schema deployment, and initial draft formatting. But brand voice, technical accuracy verification, and qualitative storytelling still require human expertise. The agent empowers your content team to work on higher-impact tasks instead of manual data logging.
Q: How long before an AEO agent shows measurable results?
A: Most organizations see initial increases in AI search visibility and citation frequency within two to four weeks. Building a dominant Share of Model position across a competitive category typically takes two to three months of consistent optimization cycles.

