
You’ve sat through five vendor demos this month. Every product calls itself an “AEO agent.” Every slide deck promises autonomous optimization, real-time visibility, and AI-native intelligence. But when you ask the one question that matters, “Show me exactly how this executes an optimization,” most vendors point you to a data export button.
That’s the gap. While 79% of enterprise organizations say they’ve adopted AI agents, only 11% have actually deployed them into production workflows. The rest are running dashboards with a language model bolted on top.
Most AEO “Agents” Are Just Dashboards with a Chat Box
The enterprise AI market has a naming problem. Legacy platforms are rebranding basic retrieval-augmented generation (RAG) dashboards as “agents” simply because they’ve added an LLM summarization layer or a conversational interface. That architectural mismatch creates real confusion for marketing teams trying to scale visibility across AI search surfaces.
Here’s a quick way to cut through the noise: does the system do things, or does it show you things?
Dashboards are post-hoc reporting tools. They tell you what happened, then leave you to manually extract data, build a content brief, coordinate with your dev team, and publish the fix. That pipeline eats weeks.
A true AEO agent is goal-oriented. It understands a high-level objective, plans multi-step sequences, uses digital tools autonomously, and adjusts strategies based on real-time feedback. Analyst frameworks from Gartner and Forrester draw this exact line: passive reporting vs. actual agency.
| Dimension | Dashboard | True AEO Agent |
|---|---|---|
| Operational Mode | Passive, retroactive reporting | Proactive, real-time reasoning and execution |
| Workflow | Siloed; manual export and coordination | Integrated; connects to CMS and citation environments |
| Logic | Rule-based, static keyword matching | Goal-oriented, probabilistic, multi-step planning |
| Adaptability | Manual config updates | Self-adjusting via closed-loop feedback |
The seven capabilities below are what separate real agents from the marketing label.
1. Autonomous Prompt Discovery, Not Just Keyword Tracking
Traditional SEO runs on keyword strings: short, fragmented phrases of two to three words. Conversational search is different. The average prompt submitted to ChatGPT is 23 words long, and research-heavy queries regularly exceed 2,000 words.
A dashboard tracks what you already know. You manually input a keyword list, and the tool monitors those specific terms. The problem is obvious: your team can’t anticipate the exact phrasing, comparison terms, and micro-intents that real buyers use inside LLM sessions.
An autonomous AEO agent flips this. It crawls your brand’s digital footprint, analyzes your market category, and queries major AI search engines to surface high-volume commercial, informational, and comparison prompts you didn’t know existed.
Topify does this through its High-Value Prompt Discovery engine. The system continuously surfaces new prompt opportunities as AI recommendations evolve, building a target database without requiring manual keyword configuration. That’s the difference between reacting to data you already have and discovering opportunities you’d otherwise miss entirely.
2. Multi-Platform Monitoring Without Manual Setup
Traditional search monitoring focuses on Google. Conversational discovery happens across ChatGPT, Gemini, Perplexity, DeepSeek, Claude, Doubao, Google AI Overviews, and more. Retrieval and citation behaviors vary significantly between these models.
Most dashboards support one or two platforms, or they require complex manual API setups for each engine. That’s an operational bottleneck during a period when new AI search surfaces are launching quarterly.
An enterprise-grade AEO agent orchestrates multi-platform monitoring simultaneously. Topify’s global engine coverage spans ChatGPT, Gemini, Perplexity, DeepSeek, Doubao, Qwen, and AI Overviews, all from a single interface. No per-platform configuration. No fragmented data silos.
3. Real-Time Competitor Detection, Not Static Lists
In AI search, the competitive landscape is probabilistic. Models synthesize information from across the web, and they frequently recommend disruptive startups, niche providers, or alternative solutions that never appear in traditional SERPs.
A dashboard compares your brand against a static list of competitors that someone on your team manually entered six months ago. Meanwhile, a new entrant just started showing up in ChatGPT’s top-three recommendations for your category.
A real AEO agent runs dynamic competitor benchmarking. It continuously queries AI platforms for category-level recommendations, automatically detects which brands the models are pairing with yours, and alerts you when a rival gains visibility or a new entrant captures share of voice. It then decodes the competitor’s advantage by analyzing the exact sources the AI is citing to support that recommendation.
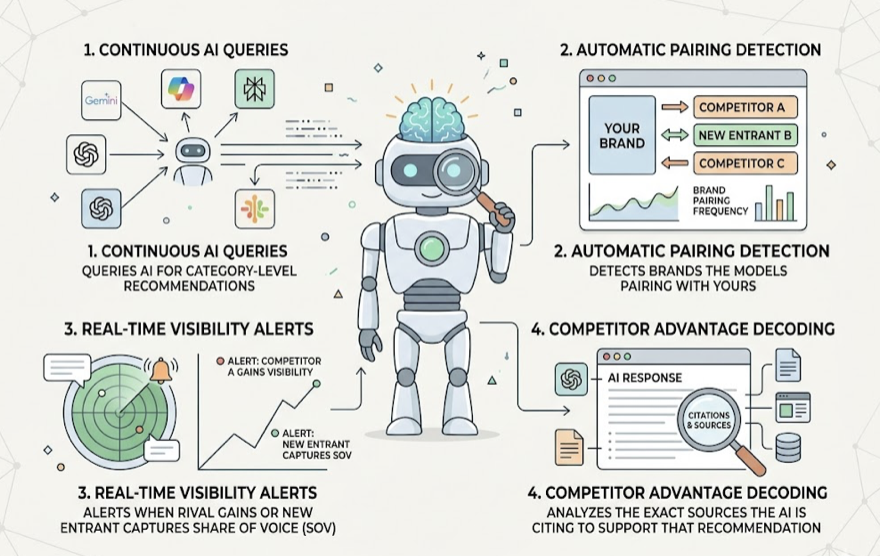
You can’t outmaneuver competitors you don’t even know exist.
4. Multi-Signal Analysis Across 7+ Metrics
A single “visibility score” tells you almost nothing. It’s the equivalent of knowing your flight is delayed without knowing the cause, the new departure time, or the gate change.
Legacy dashboards lean on this kind of oversimplified metric because they can’t track what happens inside the black box of LLM-mediated queries. A genuine AEO agent needs a multi-signal matrix across at least seven dimensions:
- Visibility: Presence, frequency, and positioning across AI search results.
- Sentiment: The tone, adjectives, and qualitative descriptors AI uses when mentioning your brand.
- Position: Ordinal ranking within the AI’s recommended set. Are you the first recommendation or a footnote?
- Volume: Frequency of brand mentions across multi-turn conversational threads.
- Citations: The specific domains and URLs that AI platforms rely on to shape their answers.
- Intent: Mapping queries across informational, comparison, and transactional states.
- CVR (Conversion Visibility Rate): The percentage of AI interactions that drive high-intent brand actions.
Topify’s Comprehensive GEO Analytics tracks all seven simultaneously. In practice, this means you can spot a sentiment shift in Gemini, trace it to a specific cited source, and connect it to a position drop in ChatGPT, all within the same view.
5. One-Click Strategy Execution: The Agent Litmus Test
This is the capability that separates the category. Everything above is intelligence. This is action.
A dashboard highlights a visibility gap or a missing citation, then hands you a to-do list. What follows is a fragmented manual pipeline: an analyst identifies the gap, a content strategist drafts an update, a developer coordinates the upload, a manager reviews the live page. That process takes weeks and burns operational budget on coordination, not creation.
A true AEO agent collapses that entire pipeline. Topify’s One-Click Agent Execution works like this: you state your goals in plain English, review the proposed strategy, and deploy with a single click. The agent identifies specific content deficits where competitors are being cited instead of your brand. It drafts optimized, answer-first content using structured data, FAQ schemas, and concise answer blocks designed to match the linguistic and semantic preferences of LLM search crawlers.
The agent then connects directly to your CMS, whether that’s WordPress, Shopify, or Framer. Each recommendation in the action feed is a completed piece of work: an optimized article, an updated comparison table, or a custom landing page. It details the targeted visibility gap, the quantitative reasoning, and the projected impact. One click publishes it live with proper formatting, metadata, and schema markup.
Human-in-the-loop review stays intact. You approve every piece before it goes live. But the operational distance between “insight” and “published optimization” shrinks from weeks to minutes.
That’s the litmus test. If your “agent” can’t publish, it’s a dashboard.
6. Citation Source Reverse-Engineering
To show up in AI-generated answers, you need to understand how these systems retrieve information. Most answer engines use RAG architectures: they run real-time web searches, extract text passages from multiple sources, and feed those passages into an LLM to synthesize a response. With zero-click searches reaching 58.5% of all queries, the inline citation has become the primary vehicle for brand discovery.
A passive dashboard tells you a competitor got cited. A real agent tells you why and shows you exactly how to take that citation.
The data here is specific. Research shows that 44.2% of ChatGPT citations and 55% of Google AI Overview citationsoriginate from the first 30% of a webpage’s content. Content structured as an “answer capsule,” a self-contained 40-to-60-word factual summary placed directly below an H2 question tag, yields a 72.4% citation rate. And 91% of those successfully cited capsules contain zero outbound links, meaning high link density within targeted passages actually hurts retrieval.
Topify’s source analysis engine reverse-engineers the entire citation chain. When it finds an answer gap, a query where competitors are cited but your brand isn’t, it identifies the exact third-party domains, review platforms, and media publications that the model used. Then it builds a content roadmap to close those gaps using structured HTML, Schema.org markup (which delivers a 2.3x lift in citation probability), and definitive language patterns that LLMs prefer to cite.
7. Closed-Loop Feedback, Not Snapshot Reports
AI search is volatile. Models retrain, retrieval databases refresh, and citation patterns shift from week to week. A snapshot report from last Tuesday is already partially stale.
Dashboards are inherently snapshot-based. They freeze performance at a point in time, and you manually run new reports to see what changed.
A genuine AEO agent operates on a continuous closed-loop cycle: execution, GEO monitoring, strategy optimization, re-execution. Every optimization action feeds new performance data back into the system. The agent automatically measures how each change influenced visibility, citations, and sentiment across platforms, then refines its recommendations accordingly.
This is the difference between a tool that shows you the weather once and a system that adjusts the thermostat.
The Quick AEO Agent Evaluation Checklist
Bring this to your next vendor meeting.
| Capability | Dashboard Behavior | True Agent Behavior |
|---|---|---|
| Prompt Discovery | User manually inputs keyword lists | Autonomously discovers conversational buyer queries |
| Platform Scope | 1-2 platforms; manual setup | ChatGPT, Gemini, Perplexity, DeepSeek, Claude, Doubao simultaneously |
| Competitor Tracking | Static, pre-defined competitor list | Dynamic detection of AI-recommended competitors in real time |
| Insight Depth | Single generic “visibility score” | 7-dimension matrix: Visibility, Sentiment, Position, Volume, Citations, Intent, CVR |
| Execution | Static reports; manual copywriting and coordination | Auto-drafts structured, answer-first content optimizations |
| CMS Integration | Exports raw data or content briefs | One-click publishing to WordPress, Shopify, Framer |
| Feedback Loop | Periodic manual reporting | Continuous closed-loop: measures results, refines strategy automatically |
Conclusion
The shift from “search, click, browse, convert” to “ask, get answer, convert” is compressing the marketing funnel in real time. Buyers are delegating product research, vendor filtering, and technical evaluations to AI assistants. Brands that aren’t cited in those conversations get eliminated from the consideration set before a human ever makes contact.
Relying on a passive dashboard in this environment isn’t just slow. It’s a structural risk. The seven capabilities above aren’t a wish list. They’re the minimum threshold for a tool that deserves the word “agent.” If your current platform can’t discover prompts, monitor multiple AI engines, detect competitors dynamically, analyze seven signal dimensions, execute with one click, reverse-engineer citations, and learn from its own results, it’s a reporting tool with a better logo.
Get started with Topify to see what an actual AEO agent looks like in practice.
FAQ
Q: What is an AEO agent?
A: An AEO (Answer Engine Optimization) agent is autonomous software that analyzes, optimizes, and maintains a brand’s visibility within generative and conversational AI search engines. Unlike a dashboard, a true agent discovers high-value conversational queries, reverse-engineers competitor citation patterns, and executes direct content optimizations to improve how AI models recommend the brand.
Q: How is an AEO agent different from an AI visibility dashboard?
A: A dashboard is a passive reporting tool that tracks brand mentions and visualizes historical data. You still have to manually extract insights, write content, and coordinate publishing. An AEO agent is an active execution system. It diagnoses visibility gaps, drafts optimized content, and publishes directly to your CMS with a single click.
Q: What questions should I ask vendors when evaluating AEO agents?
A: Four qualifying questions expose pseudo-agents fast. First, does the platform integrate directly with your CMS to publish, or does it only export recommendations? Second, how does the system discover new prompts, and does it require manual keyword input? Third, does it automatically detect AI-recommended competitors, or do you have to build a static list? Fourth, can it reverse-engineer the specific URLs and domains cited by ChatGPT, Gemini, and Perplexity for your target queries?
Q: Why do most “AEO agents” fail in production?
A: The 79%-adoption-vs-11%-deployment gap comes down to architecture. Most tools labeled “agents” are reflex systems running on fixed, rule-based sequences. They lack the reasoning capabilities needed to navigate dynamic search environments. A real agent needs goal comprehension, multi-step planning, tool use, persistent memory, and closed-loop feedback to operate autonomously.

