
Your team’s been pulling AI search data by hand for months. You’ve got the screenshots, the color-coded spreadsheets, and the proof that your brand actually shows up in ChatGPT and Perplexity answers. The strategy works. The problem is that it currently takes 8 to 12 hours a month just to audit 100 prompts, and that number only grows as you add platforms, queries, and clients. You’re not questioning whether AEO matters. You’re stuck on a harder call: when does “good enough” become a ceiling?
That’s a judgment call with a quantifiable answer.
Your Manual AEO Process Works. That’s Exactly the Problem.
Manual AEO validation is the closest thing to ground truth in generative search. You physically see how ChatGPT frames your brand, whether Perplexity cites your product page, and how Gemini handles your competitor’s name. That visibility is real, and it’s what proved the channel was worth investing in.
But “proven” and “scalable” aren’t the same thing.
Generative engines aren’t static indexes. They’re probabilistic text generators that synthesize answers from real-time data ingestion, personalized user context, and continuous model updates. A foundational AEO campaign might start with 20 core prompts. But because users ask full conversational questions, not isolated keywords, the tracking universe expands to hundreds of semantic variations fast. Multiply that across four AI platforms and a weekly cadence, and the math stops working for humans.
The ceiling isn’t strategic. It’s operational. Your team hits it not when the strategy fails, but when the volume of data extraction prevents them from acting on what they find.
5 Signals You’ve Outgrown Manual AEO
The switch from manual tracking to an AEO agent isn’t a philosophical debate. It’s a threshold check. If your team hits three or more of these five signals, the manual workflow is already costing you more than it’s delivering.
Signal 1: You’re Tracking More Than 50 Prompts
Manual entry works for 10 to 20 core brand defense queries. Beyond 50, the cross-referencing required to analyze citation presence, sentiment shifts, and competitor movement makes the reporting cycle slower than the data it captures. By the time the spreadsheet is finalized, the answers have already changed. Automated agents bypass this entirely by running discovery algorithms that surface thousands of long-tail query variations without human input.
Signal 2: You’re Covering More Than 3 AI Platforms
Each generative engine has a distinct citation personality. ChatGPT allocates 41.3% of its citations to established retail and marketplace domains while nearly ignoring social channels (0.4%). Google AI Overviews flip that bias, with YouTube capturing 62.4% of citations. Perplexity pulls from over 8,000 unique domains with an average of 8.79 citations per response.
The practical result: there’s only a 10% to 15% citation overlap between ChatGPT, Perplexity, and Google AI Overviews. Tracking one platform leaves an 85%+ blind spot. If you’re manually checking 50 prompts across four engines, that’s 200 checks per cycle. Cross-platform comparison at that scale is physically impossible without automation.
Signal 3: Content Velocity Exceeds 3 Assets Per Week
AEO-optimized content (structured FAQ pages, comparison guides, topical clusters) needs immediate monitoring after publication to determine whether it’s being cited. If your team publishes more than three assets weekly, the output velocity has outrun the manual feedback loop. Monthly reporting means you won’t know for weeks whether a new page crossed the citation threshold or got ignored entirely.
Signal 4: Citation Drift Is Faster Than Your Reporting Cycle
This is the most severe signal. An analysis of over 82,000 prompts across 17 weeks found that ChatGPT replaces up to 74% of its cited sources every single week. Google AI Mode shows a 56% weekly replacement rate. Roughly 34% of URLs cited by ChatGPT experience weekly citation swings greater than 50%.
If your monthly snapshots consistently show entirely new competitors in your target citation slots, you’re not tracking visibility. You’re documenting history.
Signal 5: Your Team Spends More Time Tracking Than Acting
Agencies average 2.5 hours per client per week on manual AEO reporting. For a 20-client portfolio, that’s 50 hours of senior analytical time buried in data extraction every single week. When the execution ratio inverts (more time tracking than optimizing), the organization is paying strategist rates for data-entry work.
What an AEO Agent Actually Does That Spreadsheets Can’t
An AEO agent isn’t a fancier dashboard. It’s an active participant in the marketing stack that continuously monitors, reasons over data, and triggers execution.
Here’s the operational difference:
| Dimension | Manual AEO | AEO Agent |
|---|---|---|
| Monitoring Frequency | Monthly or bi-weekly | Continuous / daily |
| Platform Coverage | 1 to 2 engines | 4+ engines simultaneously |
| Response Speed | 14 to 30 days (lagging) | Near real-time alerting |
| Reporting Output | Static CSVs, cropped screenshots | Interactive dashboards, sentiment scoring, visual proof |
| Human Cost | 8 to 12 hours per 100 queries | Zero hours on data collection |
| Pattern Recognition | Surface-level observations | Citation drift analysis, formatting bias detection, source-level attribution |
Three capabilities separate agents from spreadsheets.
Continuous UI-simulated monitoring. API-based tracking queries the model directly but skips the rendering layer, creating a 40% decision-making error gap compared to what users actually see. Agents spawn headless browsers to capture the fully rendered interface, retaining 100% of visual context including downloadable screenshots for client reporting.
Automated pattern detection. Agents map citation drift across thousands of variables, identifying when an LLM shifts its preference from blog posts to forum discussions, or when a new competitor’s domain begins appearing in your category’s top citations. Human analysts can’t spot these macro-patterns at scale.
One-click execution. LLMs are 28% to 40% more likely to cite content that follows specific hierarchical structures. Agents scan a brand’s domain, detect pages missing optimal formatting, and generate execution tickets to deploy structured data directly to the CMS.
Topify takes this further by natively connecting to Google Search Console, blending traditional search metrics with generative visibility data. Its AEO agent automatically tracks combined performance using Content Groups, clusters queries by topic to surface semantic gaps, and runs autonomous Near-Top 3 reports to prioritize quick wins. Rather than treating AI visibility as a separate silo, Topify maps it against existing SEO infrastructure so teams don’t have to choose between legacy analytics and generative intelligence.
The Real Cost of Staying Manual Too Long
Delaying the switch is usually framed as a budget decision. In practice, it’s a competitive one.
Generative search operates on a winner-takes-most model. An analysis of over 36 million AI Overviews and 46 million citations shows the top 20 domains control 66.18% of all AI citation real estate. The top 5 alone capture 38.13%. Competition for the remaining third is intense, and the window to claim a position is narrow.
There’s a stability mechanic that makes timing even more critical. Once a domain crosses a threshold of roughly 50 citations for a given query set, its weekly volatility drops from 50% to approximately 8%. That’s a 70x stability gap. Manual teams can’t react fast enough to push a domain across that threshold before the algorithmic window closes.
Here’s what a 3-month delay actually looks like:
A competitor deploys an AEO agent on Day 1. By Week 3, the agent detects that the LLM is beginning to favor structured FAQ schema for your core product category. The competitor autonomously deploys the schema. By Week 4, your manual team runs its monthly report and notices a slight visibility dip but lacks the granular data to understand why. By Week 8, the competitor has crossed the 50-citation stability threshold, locking in dominance at an 8% volatility rate. By Month 3, when your team finally identifies the schema deficit, the competitor is entrenched. Reclaiming that position could take a year.
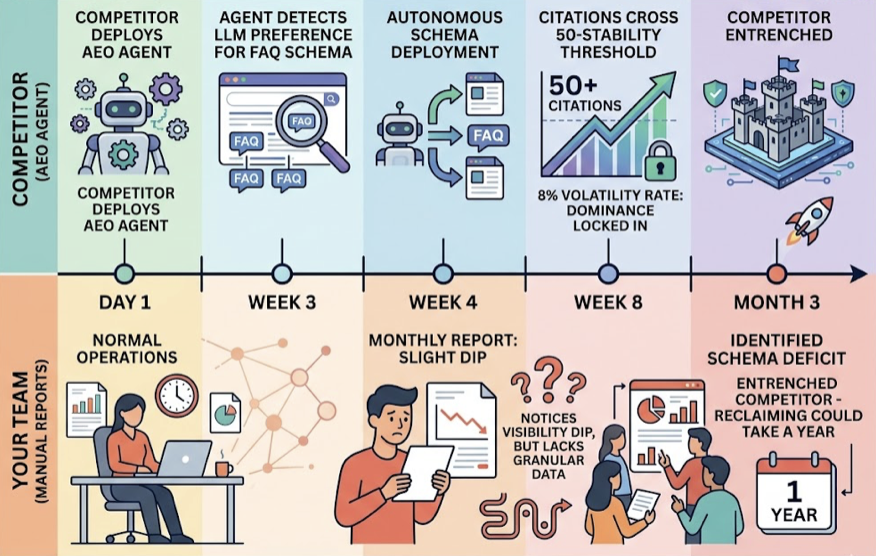
The cost of those 12 weeks isn’t a line item. It’s category leadership in generative search.
How to Make the Switch Without Losing Momentum
Ripping out a manual workflow overnight is a mistake. The goal is a parallel migration that preserves historical baselines while scaling operational bandwidth.
Step 1: Audit and consolidate your baseline. Identify the 50 to 100 highest-converting prompts that currently define your brand’s generative visibility. This dataset becomes the control variable. Don’t discard it. Import it into the new system to establish a historical foundation for algorithmic tracking.
Step 2: Pick a platform that supports gradual migration. Avoid “all-or-nothing” architecture overhauls. Topify’sonboarding requires no complex technical setup. Enter the brand name and core URLs. The system overlays a read-only SEO analytics layer via Google Search Console, instantly blending traditional search data with incoming generative metrics.
Step 3: Run a 14-day parallel trial. Deploy the agent to track the exact same baseline prompts your team is monitoring manually. During those two weeks, compare manual observations against the agent’s output. This phase validates the agent’s accuracy, highlights personalized LLM response variations that manual tracking misses, and builds organizational trust before the manual safety net is removed.
Step 4: Expand autonomously. Once validated, decommission the manual process. Reallocate the team hours previously spent on data extraction to strategy and content creation. Let the agent scale the tracking scope from your static 50 prompts to hundreds of long-tail semantic variations using automated prompt discovery.
Ready to run the parallel trial? Get started with Topify and reclaim the hours your team is currently spending in spreadsheets.
Conclusion
Manual AEO validated the channel. It proved that brand visibility in AI search is real, measurable, and worth optimizing. That validation isn’t a reason to stay manual. It’s the prerequisite for upgrading.
Apply the decision framework: if your workflow triggers three or more of the five signals (tracking over 50 prompts, covering more than 3 platforms, publishing more than 3 assets weekly, facing rapid citation drift, or spending more time tracking than acting), the switch is overdue. An AEO agent like Topify automates the intelligence-gathering layer so your team can stop documenting what AI said last month and start shaping what it says next.
Let agents do the tracking. Your team should be doing the marketing.
FAQ
Q: What’s the difference between AEO and an AEO agent?
A: AEO (Answer Engine Optimization) is the strategic practice of structuring content and managing brand presence so AI models cite and recommend your brand. An AEO agent is the software layer that operationalizes that strategy: it automates continuous monitoring, prompt discovery, cross-platform data parsing, and execution recommendations. AEO is the “what.” The agent is the “how.”
Q: How many prompts should I track before switching to an agent?
A: The practical breaking point is around 50 prompts. Human analysts can reliably handle 10 to 20 core brand defense queries. Beyond 50, the cross-referencing required across multiple platforms (citation presence, sentiment, competitor movement) makes manual reporting too slow and error-prone. If you’re already past that number, the switch pays for itself in recovered team hours alone.
Q: Can an AEO agent work alongside my existing SEO tools?
A: Yes. Platforms like Topify connect directly to Google Search Console, importing traditional search data to inform generative strategies. This lets teams create unified Content Groups, spot keyword cannibalization across both traditional and AI search, and prioritize opportunities without abandoning existing SEO infrastructure.
Q: How long does it take to set up an AEO agent?
A: Modern AEO agents are built for rapid deployment. Setting up Topify takes minutes: enter the brand name and target URLs, and the system autonomously discovers relevant prompts and generates core GEO performance metrics. The 14-day parallel trial with your existing manual process is recommended, but data starts flowing almost immediately.

