
You picked a keyword. Built the content. Earned the backlinks. Then a procurement manager asked GPT-5 to recommend vendors in your category, and your brand wasn’t in the response. A week later, a developer queried DeepSeek V4 for the same use case, and again, nothing.
The issue isn’t your content quality. It’s that each AI model retrieves and recommends brands through completely different logic, and optimizing for one doesn’t automatically win you the others.
Why the Model You’re Missing Costs You More Than You Think
Traditional search was a single battlefield. AI search is three separate ones running simultaneously.
DeepSeek V4, Anthropic’s Claude (Opus 4.7), and OpenAI’s GPT-5 each operate on distinct retrieval architectures, training data compositions, and citation biases. A brand that dominates ChatGPT recommendations can be entirely absent in DeepSeek V4 responses, and vice versa. This isn’t a content quality gap — it’s a structural gap that most marketing teams haven’t mapped yet.
The stakes are rising. Traditional search volume is predicted to drop by 25% by 2026, replaced by AI-generated answers. That traffic isn’t disappearing. It’s being redistributed to brands that AI engines choose to cite.
That’s the gap most brands still can’t see.
DeepSeek V4’s Visibility Profile and What It Recommends
DeepSeek V4 is not just another AI assistant. With approximately 1.6 trillion total parameters and a 32B–49B active parameter Mixture-of-Experts (MoE) design, it delivers frontier-level performance at a fraction of the inference cost of Western models. Some estimates put it at up to 95% cheaper than comparable Western frontier models. That cost advantage matters because it makes DeepSeek V4 the preferred engine for high-volume agentic workflows, the kind of “under-the-hood” B2B research and procurement cycles where no human is watching the model choose.
The core technical differentiator is the “Engram” conditional memory architecture. It separates static fact retrieval from dynamic reasoning, using hash-based DRAM access for simple lookups. The result: a “Needle-in-a-Haystack” factual accuracy that reportedly improved from 84.2% to 97%. For brands, this means once a fact is correctly ingested into DeepSeek’s knowledge tables, it’s retrieved with near-perfect consistency — provided it’s presented in a dense, machine-readable format.
Here’s where Western brands typically lose. DeepSeek V4 references approximately 211 unique domains in its responses, compared to over 2,385 for Google’s Gemini. That narrow retrieval pool creates a winner-take-all environment with a high barrier to entry, and it shows an amplified preference for APAC-region domains and high-authority Chinese sources. Western brands without presence in those specific repositories often face a “Visibility Gap” — they’re not misrepresented; they’re simply omitted.
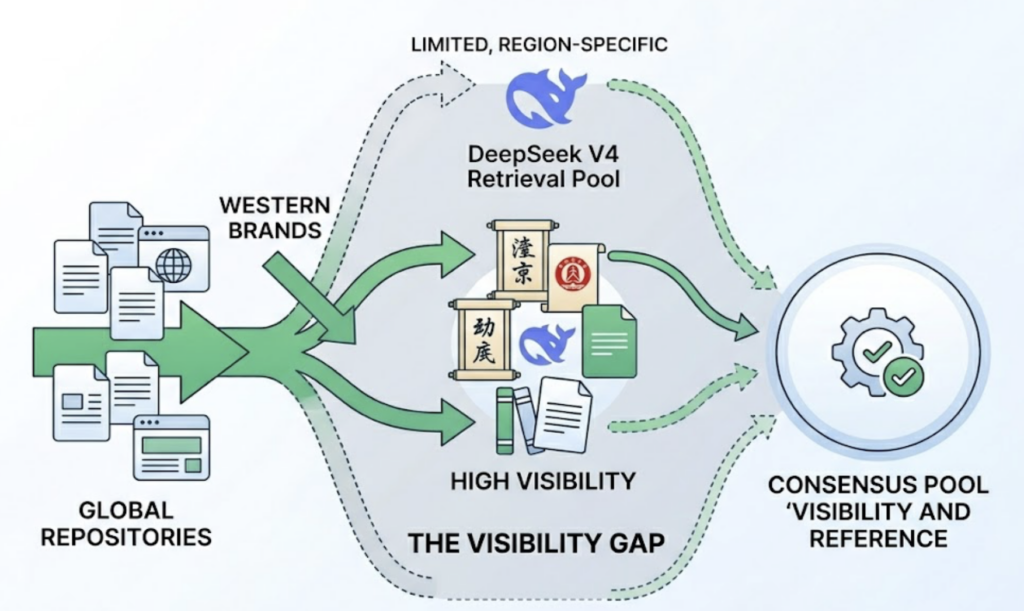
One more thing: 95.6% of DeepSeek V4 brand mentions are neutral. The model doesn’t recommend. It cites. So your goal on DeepSeek isn’t sentiment — it’s citation presence.
Claude’s Approach: The Verification-First Trust Model
Claude Opus 4.7 operates on a fundamentally different philosophy. Where DeepSeek V4 prioritizes efficiency and factual density, Claude prioritizes verifiability. This stems from Anthropic’s Constitutional AI framework, which orients the model toward safety, honesty, and balanced perspectives.
In practice, Claude is conservative with citations. It favors whitepapers, primary research, technical documentation, and third-party validated case studies. Content relying on superlative language — “the best CRM,” “industry-leading solution” — gets skipped in favor of pages that provide specific benchmarks, SOC 2 compliance details, or concrete performance data. Claude is 30% more likely to cite pages that use clear headings, structured data, and JSON-LD schema markup.
Claude’s real-time retrieval shows an 86.7% citation overlap with Brave Search. That means your Brave Search footprint directly affects your Claude visibility. For brands in YMYL sectors — healthcare, finance, legal — Claude’s preference for credentialed authors and official documentation isn’t optional; it’s the gate.
When comparing services, Claude frequently cites multiple brands to offer balanced perspectives. It acknowledges uncertainty and notes where evidence is limited. That actually creates an opportunity: brands that publish content acknowledging tradeoffs and limitations tend to rank higher in Claude’s confidence. One-sided promotional content gets filtered out.
GPT-5 and the Brand Visibility Game: Reach and Agentic Selection
GPT-5 operates at a different scale. With a weekly active user base exceeding 900 million, it’s where the majority of consumer-facing brand discovery currently happens. But its recommendation logic is shifting. The most significant change in GPT-5 isn’t a smarter chatbot — it’s the transition to an “Agentic Native Model.”
GPT-5 is increasingly optimized for Computer Use: navigating browsers, using terminals, and executing tasks autonomously. In this environment, brand visibility isn’t about appearing on a list. It’s about being selected as the fulfillment partner when an agent is tasked with procuring software, booking a service, or researching vendors. If an agent is researching fleet laptops for a design studio, it evaluates brands based on machine-readable data and its ability to autonomously execute the transaction.
GPT-5’s citation logic is heavily influenced by commercial consensus. OpenAI’s partnerships with major news organizations and data aggregators (News Corp, Reddit) shape what the model defaults to recommending. Brands with strong Reddit presence and broad news coverage have a structural advantage. For brands without that footprint, building entity signals across directories, industry associations, and editorial mentions is the path to visibility.
Content strategy also matters. GPT-5 favors pages that lead with a clear, one-paragraph answer in the first 150 words. “Snippet-Ready” definitions and opinionated comparisons outperform safe, hedged blog posts. Reddit community participation, in particular, has become one of the highest-weighted content signals in GPT-5’s training corpus.
Side-by-Side: Which Model Favors Which Brand Type
The retrieval logic differences translate directly into which brand categories each model surfaces most effectively.
| Brand Category | DeepSeek V4 | Claude Opus 4.7 | GPT-5 |
|---|---|---|---|
| High-Volume B2B SaaS | Strong: favors efficiency docs, API integration | Moderate: requires SOC 2, authority signals | Strong: default for general discovery |
| Academic & Medical | Moderate: strong STEM, weaker on Western medical nuance | Highest: favors E-E-A-T, primary research, YMYL balance | Moderate: accurate but often defaults to generic |
| Consumer Retail | Weak: APAC bias, limited Western consumer sentiment | Moderate: favors ethical, well-documented reviews | Highest: strongest sentiment tracking and reach |
| Technical & Coding Tools | Highest: world-leading algorithmic and MoE benchmarks | Strong: excels at multi-file reasoning and depth | Moderate: strong generalist, trails in specialized coding |
| Local Services | Weak: no Western local map pack integration | Moderate: relies on Brave Search local signals | Strong: deep Bing/Google local directory integration |
The pattern is clear. No single model is dominant across all brand categories. A technical SaaS brand that wins on DeepSeek V4 may be invisible on GPT-5 without Reddit presence. A consumer brand dominant on GPT-5 may be entirely absent from Claude’s citations without E-E-A-T documentation.
You Can’t Optimize What You Can’t Measure Across All Three
Single-model optimization is a bet. A “Unified Visibility” strategy is a system.
Most marketing teams are still doing manual audits — querying ChatGPT once a week, taking screenshots, logging responses in a spreadsheet. That approach doesn’t scale, and it misses the most important signals: sentiment velocity (is an AI becoming more critical of your brand over time?), citation forensics (which specific source triggered a negative sentiment?), and hallucination alerts (is a model confidently stating something false about your company?).
This is where platforms like Topify change the operational picture. Topify tracks brand visibility across DeepSeek, ChatGPT, Gemini, Perplexity, and other major AI platforms simultaneously, normalizing raw mentions into a comparable Share of Voice percentage. Instead of guessing why your brand dropped in ChatGPT recommendations last month, you can trace it to a specific source that stopped citing your brand, then act on it.
Consider a concrete scenario: a brand is dominant on GPT-5 due to strong news coverage and Reddit presence, but invisible on DeepSeek V4. A Topify divergence analysis might reveal the gap — the brand lacks presence in the specific technical repositories and APAC-indexed domains that DeepSeek V4 prioritizes. That insight shifts the content strategy from general PR to targeted technical entity disambiguation, recapturing visibility in the high-volume agentic market where DeepSeek V4 increasingly operates.
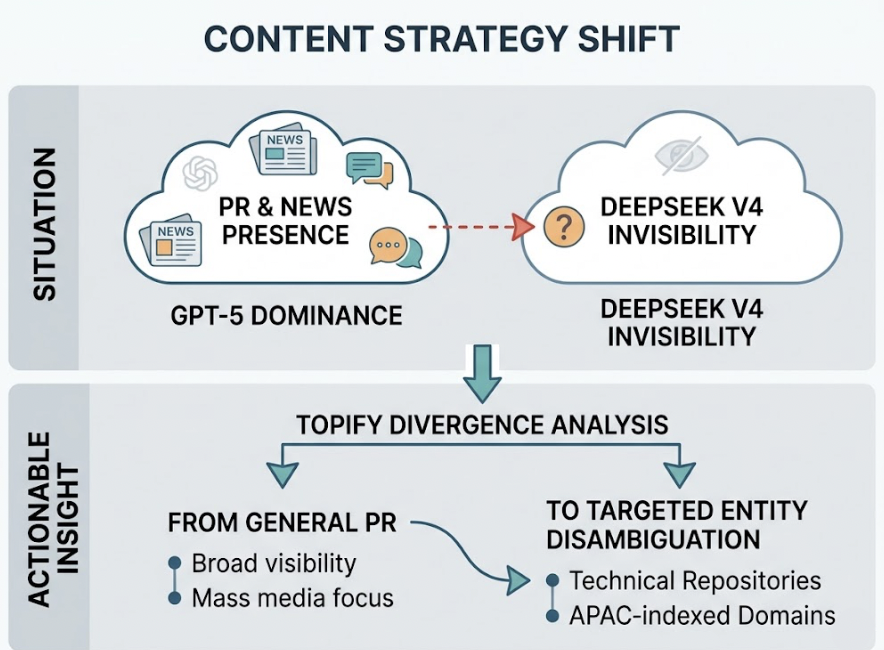
Sentiment Velocity Monitoring, Hallucination Alerting, and Source Forensics aren’t premium add-ons. In a landscape where a single false AI claim about your brand can persist across millions of queries, they’re table stakes.
Conclusion
The question isn’t which model is “best.” Each of DeepSeek V4, Claude, and GPT-5 is the dominant discovery channel for a different audience, use case, and buying context. DeepSeek V4 is winning agentic B2B workflows on efficiency and factual precision. Claude is the authority signal for high-stakes B2B and YMYL decisions. GPT-5 is the mass-market consumer and commercial gateway.
A brand that only optimizes for one is effectively invisible in the others. The strategic move for 2026 is unified measurement first, then targeted optimization per model. Get started with Topify to see exactly where your brand stands across all three — and which gaps are costing you the most.
FAQ
Q: Is DeepSeek V4 replacing ChatGPT for brand search?
A: Not in general consumer search in Western markets. But it’s rapidly becoming the dominant engine for “under-the-hood” agentic research and B2B procurement due to its extreme cost efficiency and superior coding and logic benchmarks. If your brand serves technical or enterprise audiences, DeepSeek V4 visibility is no longer optional.
Q: How do I know which AI models are mentioning my brand?
A: Manual auditing doesn’t scale once you’re tracking across multiple models. Professional marketing teams use GEO platforms like Topify to simulate thousands of prompts daily, tracking Share of Voice, sentiment, and citation sources across DeepSeek, ChatGPT, Gemini, and Claude simultaneously.
Q: Does content optimized for GPT-5 work on DeepSeek V4?
A: Only partially. Both value clear, direct answers. But GPT-5 is heavily influenced by commercial consensus and Reddit activity, while DeepSeek V4 prioritizes APAC-indexed technical repositories and dense factual formats over social sentiment. Content strategy needs to be differentiated by model.
Q: What’s the fastest way to improve my brand’s visibility across all three models?
A: Start with a baseline audit across all three. Identify where your brand is cited, where it’s absent, and where it’s misrepresented. Then prioritize gaps by the cost of invisibility for your specific brand category. The AI search visibility guide from Topify outlines a practical framework for that process.

