
Your SEO rankings are solid. Your content calendar is full. But on April 24, 2026, a new frontier model dropped that your current dashboard can’t measure, and a growing segment of high-intent technical users is already querying it for product recommendations in your category.
That model is DeepSeek V4. And most brands have near-zero visibility on it.
DeepSeek V4 Isn’t Just Another Open-Source Model
Most marketers still think of DeepSeek as a developer toy. That framing is outdated.
The V4 release introduced two variants: DeepSeek-V4-Pro, a 1.6 trillion-parameter Mixture-of-Experts model that activates only 49 billion parameters per token, and DeepSeek-V4-Flash, a 284 billion-parameter model built for extreme speed and cost efficiency. Both share a 1-million-token context window. Both are already deployed globally via API and web interface.
The economic disruption is real. DeepSeek-V4-Pro is priced at $1.74 per million input tokens, compared to $5.00 for GPT-5.5. DeepSeek-V4-Flash drops that to $0.14. That’s an 85% to 98% cost reduction relative to Western frontier models, achieved through sparse attention and domestic hardware compatibility.
When inference costs collapse, adoption accelerates. Fast.
90 Million Monthly Users and Growing
DeepSeek crossed 22.15 million daily active users in January 2025. By early 2026, monthly active users are estimated to exceed 90 million, driven primarily by cost-sensitive enterprise adoption and developer communities.
The geographic footprint matters for brand strategy. China, India, and Indonesia collectively account for over 50% of monthly active users, while the U.S. holds roughly 4% to 9%. The 18 to 24 age group represents 40% to 44% of total users, skewing toward developers, students, and early-career professionals.
Over 80% of DeepSeek traffic is desktop-based. That’s not a casual social media audience. That’s a research-oriented, decision-making audience running technical queries.
And here’s what those users are actually doing: asking for product comparisons, infrastructure recommendations, software stack decisions, and vendor evaluations. The same queries that used to go to Google’s first page are now going to DeepSeek’s synthesis engine.
Why Google Rankings Don’t Transfer to DeepSeek V4
This is where most marketing teams are caught off guard.
A healthy AI Visibility Rate for a category leader typically exceeds 30%. Preliminary audits of brands with dominant Google rankings often show less than 5% visibility on DeepSeek. The gap isn’t a bug. It’s by design.
DeepSeek doesn’t use the same signals as traditional search. Domain authority doesn’t translate. Keyword density doesn’t help. What the model values is something different: machine-legible expertise and citation density across specialized technical repositories.
DeepSeek V4 runs a novel memory architecture called Engram conditional memory, which separates static knowledge retrieval from active neural reasoning. What this means in practice: the model has a static “memory table” built during pre-training from over 32 trillion tokens of web pages, e-books, and technical manuals. If your brand’s factual data isn’t in that memory table with precision, the model will struggle to identify you reliably.
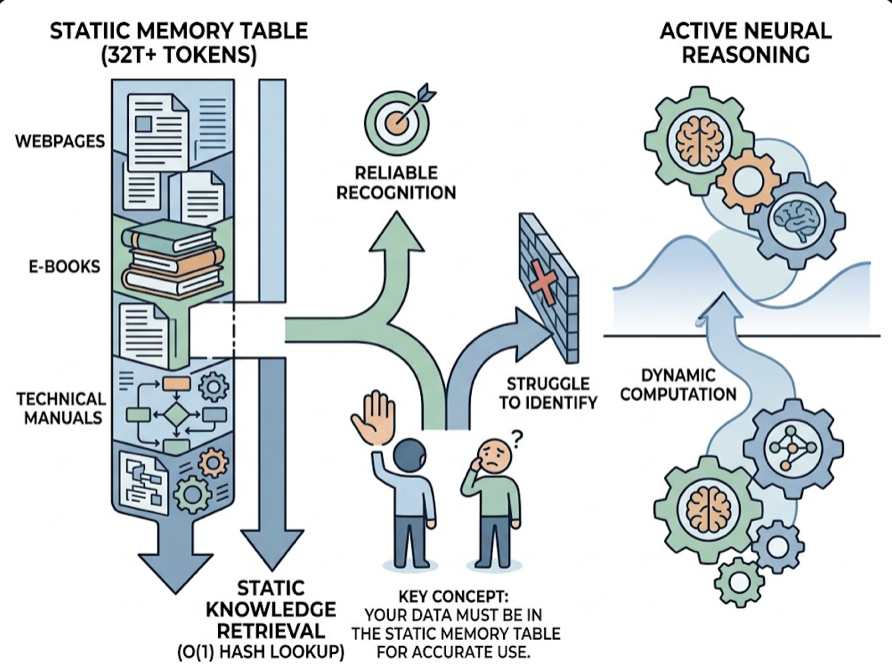
Its SimpleQA benchmark score of 57.9% versus Gemini’s 75.6% tells the story. DeepSeek is a reasoning champion, but it has voids in consumer brand knowledge. That void is both a risk and an opening.
3 Signs Your Brand Is Already Behind on DeepSeek
Signal 1: You don’t know your AI Visibility Rate.
If your team can’t answer “what percentage of DeepSeek queries in our category mention our brand,” you don’t have the baseline to work from. Most teams don’t. That blind spot is expensive in an environment where high-intent research traffic is shifting from traditional search to AI synthesis engines.
Signal 2: Competitors appear first in multi-brand comparisons.
DeepSeek’s MoE architecture uses a Response Position Index where the first brand listed in a comparison carries implicit endorsement. If a competitor is consistently the primary recommendation when users ask “compare [your category] options for a fintech stack,” that positioning compounds over time. Early-stage AI visibility is significantly easier to build than it is to claw back from a competitor.
Signal 3: Your content can’t be parsed into discrete facts.
DeepSeek’s Hybrid Attention mechanism is optimized for scanning long-context documents to extract specific data points. Blog posts written as continuous narrative prose, without structured Q&A sections, schema markup, or modular data, are effectively invisible to this parsing logic. The model will prefer a competitor’s well-structured documentation over your 3,000-word thought leadership piece.
How DeepSeek V4 Actually Decides What to Recommend
Understanding the citation logic changes how you approach content strategy.
When a user asks DeepSeek for a product recommendation, two pathways activate. The Engram memory pathway handles factual recall, pulling structured brand data directly from the static knowledge base. The MoE reasoning pathway handles the actual recommendation, drawing on patterns found across the training corpus.
That second pathway is where brand positioning happens. The model’s recommendation “consensus” is shaped by how your brand appears across authoritative, technically rigorous sources: Reddit’s engineering forums, GitHub discussions, peer-reviewed technical documentation, and specialized industry publications. Frequent, consistent, and unbiased mentions in those contexts carry more weight than any amount of generalist content.
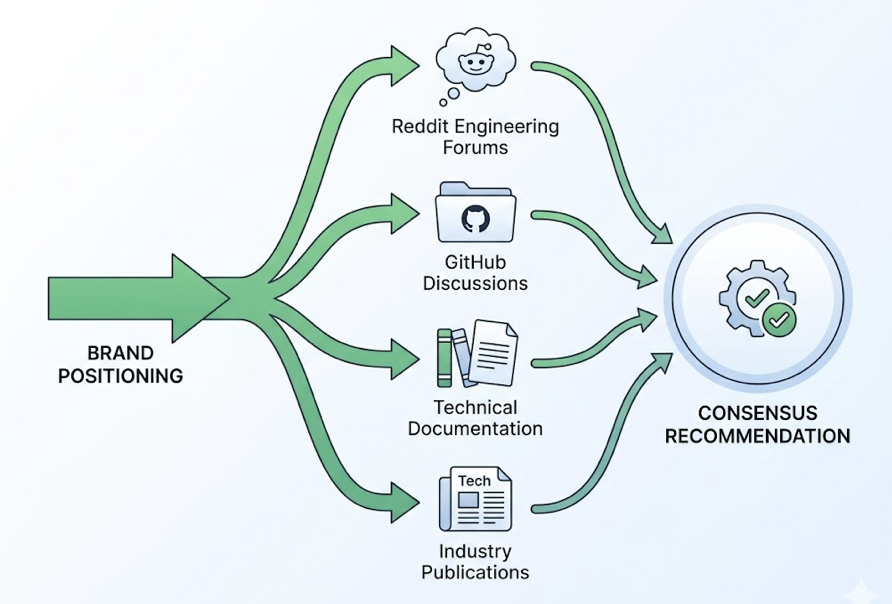
This is structurally different from ChatGPT’s citation logic, which leans on high-authority generalist sites and Bing-indexed content. DeepSeek rewards narrow authority, not broad domain authority.
What You Can Actually Do Starting This Week
The good news: DeepSeek V4 visibility is buildable. The model updates brand mentions within 2 to 4 weeks as it ingests fresh web signals. The window for early positioning is still open for most categories.
A practical 90-day sequence looks like this:
Weeks 1 to 2: Establish your baseline. Run a set of 20 to 30 high-intent category prompts on DeepSeek and document mention frequency, position, and the external domains the model cites as sources. This is your starting point.
Weeks 3 to 4: Audit your technical foundation. Implement Schema Markup for all products and organization data. Schema increases what researchers call “Entity Confidence,” the model’s ability to distinguish your brand from similarly named entities in its static knowledge table.
Weeks 5 to 8: Publish structured authority content. Launch 10 to 15 high-specificity articles addressing technical questions identified in your baseline audit. Target platforms DeepSeek weights heavily: GitHub documentation, LinkedIn technical posts, and specialized forums where your category’s practitioners actually discuss tools.
Weeks 9 to 12: Track and iterate. Monitor Sentiment Velocity alongside Visibility Rate. A stable or improving sentiment score indicates the model is building a positive “consensus” about your brand across its reasoning pathway.
For teams managing this at scale, Topify has integrated DeepSeek V4 into its tracking coverage, alongside ChatGPT, Gemini, Perplexity, and other major platforms. Its seven-dimension metric system connects AI citation data to revenue signals, with research indicating that traffic arriving from AI citations can convert at rates up to 12.9x higher than traditional organic search.
The core metrics worth monitoring:
| Metric | What It Measures | Target Range |
|---|---|---|
| Visibility Rate | % of category prompts where brand appears | 30% to 45% |
| Sentiment Score | AI’s attitude toward the brand (0-100) | 70+ |
| Sentiment Velocity | Rate of sentiment change over time | Stable or positive |
| Response Position Index | Where brand appears in multi-brand comparisons | Below 1.5 |
| Source Citation Share | % of AI-cited sources owned by the brand | Above 20% |
DeepSeek V4 vs. ChatGPT: Do You Need a Different Strategy?
Yes. The strategies are complementary but distinct.
Content depth and tone diverge significantly. DeepSeek V4 rewards dense, technically specific content. Think the kind of writing that appears in engineering documentation or detailed product teardowns, not accessible summaries or broad overviews. ChatGPT’s alignment favors more balanced, accessible formats.
Source weighting works differently too. ChatGPT leans on mainstream news sources and Wikipedia. DeepSeek gives significant weight to narrow authority: GitHub repositories, technical manuals, and specialized forums. A brand that publishes a detailed API integration guide on GitHub is doing more for DeepSeek visibility than one publishing polished blog content on its own domain.
Regional audience profiles also differ. DeepSeek is the primary AI gateway for tech-heavy markets in Asia, while ChatGPT remains dominant for North American and European general consumers. For brands with a global footprint, treating these as two distinct channels, each requiring tailored source strategy, is no longer optional.
The bottom line: ranking on one doesn’t transfer to the other. Both require active GEO strategy.
Conclusion
DeepSeek V4 didn’t create the AI search visibility problem. It made it bigger and harder to ignore.
Most brands are running a marketing stack built for a world where Google rankings predict discovery. That world still exists. But alongside it, a parallel discovery layer is forming, one where 90 million monthly users are asking AI systems for vendor recommendations, and where brand presence is determined by machine-legible reputation, not keyword rankings.
The brands building DeepSeek visibility now are establishing the kind of positioning that’s significantly harder to displace later. Get started with Topify to see where your brand stands across DeepSeek, ChatGPT, Gemini, and Perplexity, before your competitors do.
FAQ
Q: Does DeepSeek V4 use the same ranking signals as ChatGPT?
A: No. While both systems draw on web-based training data, DeepSeek V4 places a significantly higher premium on technical accuracy and STEM-focused sources. Its Engram memory architecture prioritizes structured, machine-legible data, making Schema Markup more important for DeepSeek than for ChatGPT. The two models also weight sources differently: DeepSeek favors narrow authority sources like GitHub repositories and technical documentation, while ChatGPT leans on mainstream, high-authority generalist sites.
Q: How do I start tracking my brand’s visibility on DeepSeek V4?
A: The most practical starting point is to manually run 20 to 30 high-intent category prompts on chat.deepseek.com and document how often your brand appears versus competitors. For systematic tracking, GEO platforms like Topify query models at scale to generate Visibility Rate, Sentiment Score, and Position data across DeepSeek and other major AI platforms.
Q: Is DeepSeek V4 available globally?
A: Yes. DeepSeek V4 is available globally via its official API and web interface, with open-source weights available on Hugging Face for local deployment. Enterprises in regulated sectors, including healthcare and defense, often prefer on-premises self-hosting to meet data residency and compliance requirements.
Q: How often does DeepSeek update its model recommendations?
A: Major versions follow roughly an annual release cycle, but the underlying endpoints receive frequent minor updates. Brand mentions typically reflect content changes within 2 to 4 weeks as the model ingests fresh web signals and fine-tuning data. This makes early and consistent visibility-building more effective than periodic content bursts.

