
Most AI cost comparisons stop at the price table. That’s the wrong place to stop.
DeepSeek V4 Flash is generating real buzz in marketing circles, and for good reason: it’s priced at $0.14 per million input tokens, making it over 90% cheaper than Claude Haiku 4.5 and significantly cheaper than GPT-4o Mini. For teams running millions of tokens a month through content generation, tagging, or ad copy pipelines, that’s not a rounding error. That’s a budget category.
But cheap tokens don’t automatically translate to business value. The real question isn’t “how much does it cost?” It’s “which tasks will it actually handle without breaking?”
This breakdown answers that. No hype in either direction.
What DeepSeek V4 Flash Actually Is (And What It Isn’t)
Flash is not a stripped-down version of DeepSeek V4 Pro. It’s a separately engineered system with a different design goal.
Both models share a Mixture-of-Experts (MoE) architecture, but the similarity ends at the naming convention. V4 Pro activates 49 billion parameters per token, while Flash activates 13 billion, out of a total weight set of 284 billion parameters. That 13B active footprint is intentional: it lets Flash run at high batch sizes with lower hardware overhead, which is exactly what high-throughput pipelines need.
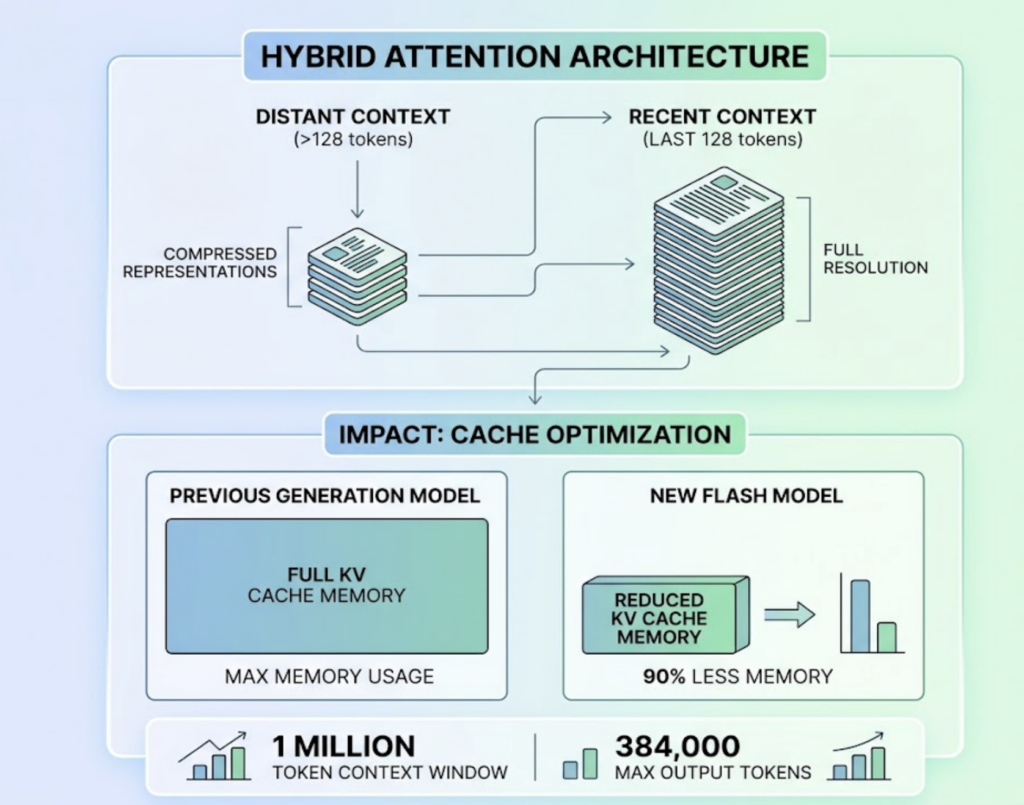
The headline technical feature is the Hybrid Attention Architecture, combining Compressed Sparse Attention (CSA) and Heavily Compressed Attention (HCA). In plain terms: Flash compresses distant context aggressively, keeping only the last 128 tokens in full resolution while reducing the rest to compact representations. The result is a KV cache that uses roughly 90% less memory than previous-generation models at the same context depth. With a 1-million-token context window and a maximum output of 384,000 tokens, Flash is built for bulk.
One more thing worth noting: Flash runs on Huawei’s Ascend 950PR silicon, not Nvidia GPUs. This matters for Western enterprise buyers thinking about supply chain risk, but it doesn’t affect API users at all.
The Pricing Case for DeepSeek V4 Flash in Marketing Workflows
Here’s where the numbers start to matter. The table below compares the models most likely to appear in a marketing team’s stack:
| Model | Input Cost / 1M tokens | Output Cost / 1M tokens | Context Window |
|---|---|---|---|
| DeepSeek V4 Flash | $0.14 (miss) / $0.028 (hit) | $0.28 | 1 Million |
| GPT-5.4 Nano | $0.20 / $0.005 | $1.25 | 128K |
| GPT-5.4 Mini | $0.75 / $0.187 | $4.50 | 400K |
| Claude Haiku 4.5 | $1.00 / $0.10 | $5.00 | 200K |
| Gemini 3.1 Flash | $0.50 / free (tiered) | $3.00 | 1 Million |
The “hit” price for Flash refers to cached tokens. When static content like brand guidelines, a product catalog, or a large FAQ is placed at the start of a prompt, it gets cached. Subsequent calls reuse that cache at $0.028 per million tokens, a 80% discount off an already low base price.
For a team running 10 million tokens per month against a 100,000-word knowledge base, that context caching mechanism alone can cut the effective input cost to near zero on most requests.
The practical upshot: a 10-step agent workflow that costs $0.50 on a frontier US model often runs under $0.05 using Flash with smart prompt design.
5 Marketing Tasks Where DeepSeek V4 Flash Holds Up
Flash performs well when tasks are bounded, structured, and don’t require the model to “think beyond the prompt.”
Email subject line generation. Flash can generate hundreds of variations across audience segments in seconds. The task is formulaic: short output, clear constraints, no long-range reasoning required. Flash performs at parity with V4 Pro here while delivering responses significantly faster.
A/B advertising copy variants. Take one winning headline, generate 30 semantic variations while preserving the original intent. Flash’s throughput makes this viable in real-time programmatic environments where ad copy changes based on the specific page a user is visiting.
SEO metadata at scale. Bulk generation of titles and meta-descriptions for ecommerce catalogs with 50,000+ products. Flash is also reliable for query intent mapping, taking search console exports and categorizing thousands of terms into informational, commercial, or navigational buckets.
Social media content adaptation. Flash can ingest a 5,000-word whitepaper and produce a LinkedIn post, a 10-part thread, and an Instagram caption in one pass. The 1-million-token context window means the final post stays thematically coherent with the source document.
Customer service response drafting. The majority of support queries are routine. Flash identifies the intent of an incoming email, selects the correct template from a predefined list, fills in order-specific details, and surfaces a polished draft for a human agent to approve. It’s not autonomous; it’s a first-pass filter.
Where DeepSeek V4 Flash Starts to Break Down
The failures aren’t random. They follow a clear pattern: the more a task requires holding multiple conflicting constraints simultaneously, the more likely Flash is to underperform.
Multi-step campaign strategy. When asked to produce a 12-month marketing plan with budget allocations, cross-channel attribution, and competitor counter-moves, Flash often produces generic or internally inconsistent outputs. This is a “high-horizon” reasoning task. With only 13B active parameters vs. V4 Pro’s 49B, Flash lacks the global coherence to maintain logical consistency across complex constraint sets.
Brand voice in long-form content. Past the 2,000-word mark, Flash exhibits style drift. The first few paragraphs often match the target brand voice well. By the end, the model tends to revert to neutral, dry prose or begins summarizing rather than continuing to generate original content. For brand-sensitive long-form work, this is a real problem.
Complex agentic tool-use. Flash supports parallel function calling and up to 128 tools in a single call. That said, in sequences requiring 5+ tools in a precise order, Flash has a higher failure rate than Pro: it confuses data types, loses state between tool calls, and tends to repeat mistakes rather than diagnose and pivot when a tool returns an error.
Data analysis and insight generation. Flash can summarize what happened (“sales increased 10%”). It struggles with the “why” when the explanation requires connecting disparate signals across a large dataset. That diagnostic work requires the reasoning depth of a Pro-tier model.
Flash vs. V4 Pro vs. GPT-4o Mini: A Side-by-Side for Marketers
| Dimension | DeepSeek V4 Flash | DeepSeek V4 Pro | GPT-4o Mini |
|---|---|---|---|
| Cost per 1M tokens (blended) | ~$0.20 | ~$2.60 | ~$0.37 |
| Throughput (tokens/sec) | 100 to 150 | 30 to 50 | 80 to 100 |
| Instruction following | Good (requires strict prompts) | Excellent | Very Good |
| Long-form consistency | Moderate | Strong | Strong |
| Agent / tool use stability | Limited | Full | High |
| Multimodal support | No (text only) | No (text only) | Yes (vision) |
| Best for | Bulk drafts, tagging, extraction | Strategy, complex reasoning | Balanced workloads, image analysis |
The standout gap on cost is real: Flash is roughly 13x cheaper than V4 Pro on a blended basis. GPT-4o Mini sits in the middle on both cost and capability. If your workflow involves image analysis or vision tasks, Flash isn’t an option at all. That’s a hard constraint, not a preference.
How to Decide: A Practical Decision Matrix for Marketing Teams
Three variables determine whether Flash is the right call.
Token volume. At fewer than 1 million tokens per month, the cost difference between Flash and alternatives is small enough to be irrelevant. At 10 million tokens per month and above, Flash’s pricing becomes a real budget lever.
Task structure. Template-driven tasks, where the model fills in predictable slots rather than inventing structure, play to Flash’s strengths. Open-ended creative or analytical tasks don’t.
Human review cadence. Flash works best with a human-in-the-loop. If an expert marketer reviews outputs before publication, the risk from Flash’s occasional drift or inconsistency is manageable. In autonomous agent workflows, the lower error rate of Pro-tier models is worth the price premium.
Flash is the right call when:
- Monthly token volume exceeds 10M
- Tasks follow a repeatable, template-driven structure
- A human reviews output before it’s published
- Response latency matters (real-time chat interfaces, programmatic ad copy)
Go with Pro or an alternative when:
- The agent runs without supervision
- Brand voice consistency is non-negotiable in long-form outputs
- The task requires synthesizing disparate data points into non-obvious conclusions
- A factual error has legal or reputational consequences
Your Brand’s Presence on DeepSeek Matters Too
Here’s a dimension most model selection discussions skip entirely.
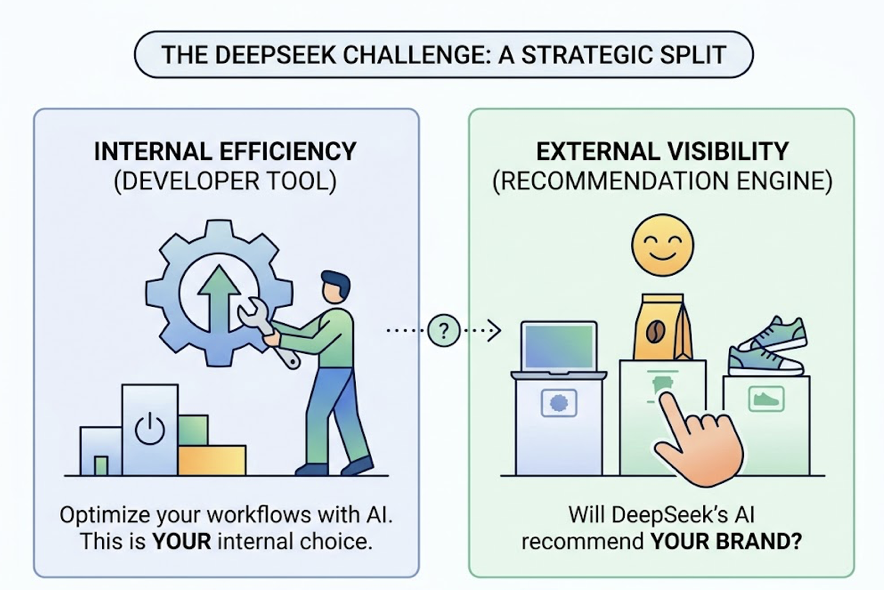
DeepSeek now has over 900 million weekly active users across its ecosystem. It’s no longer just a developer tool. It’s a general-purpose AI platform where real customers are asking questions and getting brand recommendations. The model you choose to run internally is one decision. Whether DeepSeek is recommending your brand externally is a completely separate one.
DeepSeek’s recommendation logic differs from traditional search. It prioritizes sources with high atomic fact density, meaning clear and extractable claims over marketing language. It cross-references information across multiple domains, so if a brand’s claims only appear on its own website, the model discounts them. Content with clear headings and logical structure is reportedly 40% more likely to appear in DeepSeek’s reasoning blocks.
This is where platforms like Topify provide a distinct edge. Topify tracks brand visibility across major AI platforms including DeepSeek, using a method called Swarm Probing: running thousands of prompt variations across geographic nodes to calculate a statistically reliable share of voice. From there, teams get actionable data on:
- Visibility Tracking: the percentage of relevant prompts where your brand appears in DeepSeek’s outputs
- Sentiment Velocity: whether DeepSeek’s default framing of your brand is trending positive or negative
- Citation Reverse-Engineering: the specific URLs DeepSeek is using as its primary sources of truth, whether those are your pages or a competitor’s
- AI Volume Analytics: estimated monthly demand for topics across generative platforms, which moves beyond keyword volume into what Topify calls “Conversational Demand”
If Topify’s tracking reveals a visibility gap or negative sentiment on DeepSeek, teams can deploy “answer-first” content restructuring in one click, making existing articles easier for AI systems to parse and cite. Brands can also engage in Entity Claiming (currently in beta) to push verified data directly to AI knowledge graphs, bypassing the standard crawl cycle.
The point: choosing Flash vs. Pro is a workflow decision. Ensuring your brand is visible and accurately represented on DeepSeek is a growth decision.
Connecting Flash to Your Existing Marketing Stack
Flash is available via DeepSeek’s official API at api.deepseek.com and through aggregators including OpenRouter, Together AI, and Fireworks. It’s compatible with any tool that supports the OpenAI or Anthropic API formats.
In Make.com, DeepSeek now has a native module. A standard scenario: watch a Google Sheet for new products, send each row to Flash for automated generation of three ad headlines and two meta-descriptions, then update Shopify automatically.
In n8n, teams can build smarter routing logic. A prompt enters the workflow, Flash runs a low-cost first pass, and a secondary Flash reviewer checks confidence. If the output is flagged as ambiguous, n8n branches the request to V4 Pro or GPT-5.4. That tiered routing pattern keeps 80% of requests on Flash pricing while escalating only the tasks that genuinely need more reasoning depth.
Since n8n supports self-hosting, teams can also pair it with a local vector database to maintain persistent long-term memory for their agents, with Flash’s 1-million-token window ingesting full retrieved document sets without truncation.
Conclusion
DeepSeek V4 Flash isn’t a cheaper version of a smarter model. It’s a different tool designed for a specific job: high-volume, structured, latency-sensitive tasks where token economics matter and human review is part of the workflow.
The brands that get real value from Flash are the ones running bulk SEO metadata generation, ad copy pipelines, or email variant workflows at scale. The ones who get burned are the ones using it for autonomous agents, complex strategy generation, or brand-sensitive long-form creative without supervision.
Token cost is only one input in that calculation. The other is knowing where your model’s capability ceiling actually sits, and building your stack accordingly.
FAQ
Is DeepSeek V4 Flash available via API for marketing tools?
Yes. V4 Flash is available through DeepSeek’s official API at api.deepseek.com and through aggregators like OpenRouter, Together AI, and Fireworks. It’s fully compatible with any tool that supports the OpenAI or Anthropic API formats.
How does DeepSeek V4 Flash compare to Claude Haiku 4.5 for content generation?
DeepSeek V4 Flash is roughly 10x cheaper on output tokens and over 3x cheaper on input tokens compared to Claude Haiku 4.5. Haiku 4.5 shows stronger emotional nuance and empathy in customer-facing copy. Flash performs better on technical, structured, and data-extraction tasks. For marketing automation at volume, Flash’s cost profile is hard to ignore.
Can I use DeepSeek V4 Flash in n8n or Make.com automations?
Yes. DeepSeek is a native module in Make.com. In n8n, you can use the OpenAI Chat Model node and override the Base URL to DeepSeek’s endpoint, since the API protocols are identical.
Does DeepSeek V4 Flash support function calling?
Yes. It supports native parallel function calling, up to 128 functions in a single call, and a “strict” mode for JSON schema validation. This is one of its strongest features for structured agentic workflows, though complex multi-step tool sequences require careful prompt engineering to avoid state-loss errors.
How do I track whether DeepSeek is recommending my brand?
Platforms like Topify track brand visibility across DeepSeek and other major AI platforms using large-scale prompt sampling. Key metrics include visibility rate, sentiment velocity, and citation source analysis, which shows exactly which URLs DeepSeek is treating as authoritative for your brand’s category.

