
Your domain authority is 70. Your keyword rankings are solid. But when someone asks Perplexity for a recommendation in your category, it cites a Reddit thread from three weeks ago instead of your well-optimized landing page.
That’s not a fluke. It’s a pattern.
When the same prompt runs across ChatGPT, Perplexity, Gemini, and Google AI Overviews, the overlap in cited domains is roughly 11%. Four platforms, four almost entirely separate source lists. The traditional SEO playbook, built on backlink profiles and domain authority, doesn’t explain why your brand appears on one platform and vanishes on another.
Each AI engine runs its own retrieval pipeline with distinct preferences for authority, recency, and source type. Understanding those differences isn’t optional anymore. It’s the foundation of any serious generative engine optimizationstrategy.
ChatGPT Treats Wikipedia Like a Trust Anchor
ChatGPT’s citation behavior reflects two layers: pre-training weight and real-time retrieval. Both skew heavily toward institutional authority.
An analysis of 680 million ChatGPT citations shows commercial domains (.com) account for 80.41% of all cited URLs. Non-profit (.org) domains follow at 11.29%. Country-specific TLDs (.uk, .au, .ca) collectively represent about 3.5%. The hierarchy is clear: ChatGPT defaults to established, commercially credible entities.
Within that landscape, Wikipedia holds a singular position. It contributes 7.8% of ChatGPT’s total citations and commands nearly half (47.9%) of the top 10 cited sources. Brands with a detailed Wikipedia entry get their first ChatGPT citation in an average of 28 days. Without one, that timeline stretches to 52 days.
That’s not a minor gap. That’s a structural disadvantage.
Wikipedia functions as what researchers call an “entity anchor.” When ChatGPT encounters a brand name through its Bing-powered search, it cross-references Wikipedia to verify the entity’s attributes and credibility. If that verification step fails, the brand gets filtered out during the re-ranking phase, regardless of how strong its on-site content is. ChatGPT also co-cites Wikipedia with institutional references like Britannica and Merriam-Webster at a rate of 43%, reinforcing its preference for encyclopedic, fact-dense sources.
One detail worth noting for tech brands: .io and .ai domains, while small in overall share (1.67% and 1.13% respectively), show high penetration in developer-focused and technology-related queries. In vertical categories, domain authority matters less than topical authority.
| TLD | Share of ChatGPT Citations |
|---|---|
| .com | 80.41% |
| .org | 11.29% |
| .uk | 2.16% |
| .io | 1.67% |
| .ai | 1.13% |
| .net | 1.01% |
| .co | 0.97% |
Perplexity Reads 10 Pages but Cites 3
Perplexity positions itself as the most transparent AI search engine. It shows numbered citations inline. It looks accountable.
The numbers tell a more complicated story.
Perplexity’s Sonar model averages 21.87 citations per response, the highest density of any major LLM platform. But its retrieval pipeline visits approximately 10 relevant websites per query and only credits 3 to 4 of them. Researchers describe this as a “high-volume, low-credit” pattern: the model absorbs information from sources it never attributes.
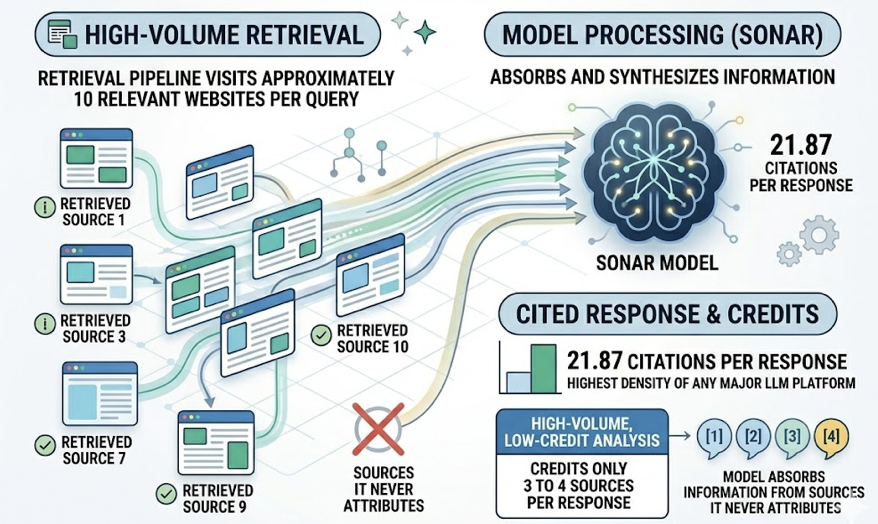
That gap has real consequences for brands. Your content may be shaping Perplexity’s answer without you ever knowing it, and without any referral traffic flowing back.
Perplexity’s strongest signal preference is recency. 82% of its cited content was updated within the past 30 days. For content older than six months, citation rates drop to 37%. If you’re not publishing or refreshing regularly, Perplexity’s attention window closes fast.
Then there’s the Reddit factor. Reddit accounts for 6.6% of Perplexity’s total citations and 46.7% of its top 10 cited sources. The distribution within Reddit is specific: Q&A posts make up over 50% of Reddit-sourced citations, comparison threads account for 25%, and discussion threads contribute 15%. When a user asks Perplexity which CRM is best for startups, it trusts an upvoted Reddit thread over your product page.
That’s not a bug. Perplexity’s model interprets Reddit as a proxy for human consensus, a crowdsourced credibility layer that branded content can’t easily replicate.
Gemini: The Platform That Rarely Cites Anything
Gemini presents a paradox. It sits on top of Google’s entire index, the largest repository of web content in existence. And yet it operates as if citations are optional.
The data is striking: 92% of Gemini’s responses include zero clickable citation links. Even when the model clearly draws on external information, it doesn’t disclose where. On top of that, 34% of Gemini responses are generated entirely from pre-training data without triggering any external search at all.
For brands, this creates a visibility black hole. You can’t earn a citation from a platform that doesn’t give them. And you can’t redirect traffic from an AI answer that doesn’t link anywhere.
| Metric | Gemini | ChatGPT (GPT-4o) | Perplexity (Sonar) |
|---|---|---|---|
| No-search response rate | 34% | 24% | < 5% |
| Zero-citation response rate | 92% | 30% | 0% (cites by default) |
| Avg. attribution gap (sites) | 3.04 | Very small | 3.12 |
Researchers frame this behavior as a form of “data enclosure.” Gemini trains on the open web but keeps users within Google’s ecosystem at the point of delivery. The practical implication: optimizing specifically for Gemini citation is a low-ROI activity for most brands right now. The platform’s architecture simply doesn’t reward external content with traffic.
That said, Gemini’s user base is massive. Even without clickable citations, brand mentions in Gemini’s responses influence perception. Monitoring what Gemini says about your brand, even when it doesn’t link to you, matters for reputation management.
AI Overviews Play by Different Rules Than Gemini
Here’s where it gets interesting. Google AI Overviews (AIO) and the standalone Gemini model share a parent company but not a citation philosophy.
AIO operates more like a curated editor than a knowledge synthesizer. It pulls from a wider range of source types, integrates richer media, and cites more diversely than Gemini. The data shows AIO cites YouTube at 30 times the rate of ChatGPT. For retail and purchase-intent queries, AIO references major retailer domains at roughly 30% compared to ChatGPT’s 15%.
This makes sense when you consider AIO’s context. It sits at the top of Google Search results, layered alongside shopping cards, local packs, and People Also Ask boxes. Its citation logic is designed to complement that existing infrastructure, not replace it.
For brands, this means the path to AIO visibility is closer to traditional SEO than to LLM-specific optimization. Pages that rank well in organic search have a stronger shot at being cited in AIO, though it’s not a one-to-one mapping. Research shows only about 12% of links cited in AI-generated responses also appear in the top 10 traditional search results.
Reddit also matters here, but less than in Perplexity. Reddit represents 2.2% of AIO citations, a meaningful but not dominant share.
What Gets Cited Across All Four Platforms
Despite the divergence, there are patterns that hold across platforms. These are the structural features that make content “citable” regardless of which AI engine is doing the retrieval.
Research from Princeton University, Georgia Tech, and the Allen Institute for AI (published at KDD 2024) tested nine content modification strategies and found that targeted structural changes can boost AI visibility by up to 40%.
The most impactful interventions:
| Strategy | Visibility Lift |
|---|---|
| Adding specific statistics | +41% |
| Citing authoritative sources within content | Significant increase |
| Including expert quotes | High trust signal |
| Fluency optimization (no new info, just better writing) | +28% |
| Schema markup (FAQPage, Article, HowTo) | +30% |
AI engines, particularly Perplexity and ChatGPT, process web pages as a series of extractable chunks. The optimal snippet length falls between 40 and 60 words. Leading with the conclusion in the first 100 words of each section, what researchers call BLUF (Bottom Line Up Front), correlates with 90% of top-cited passages.
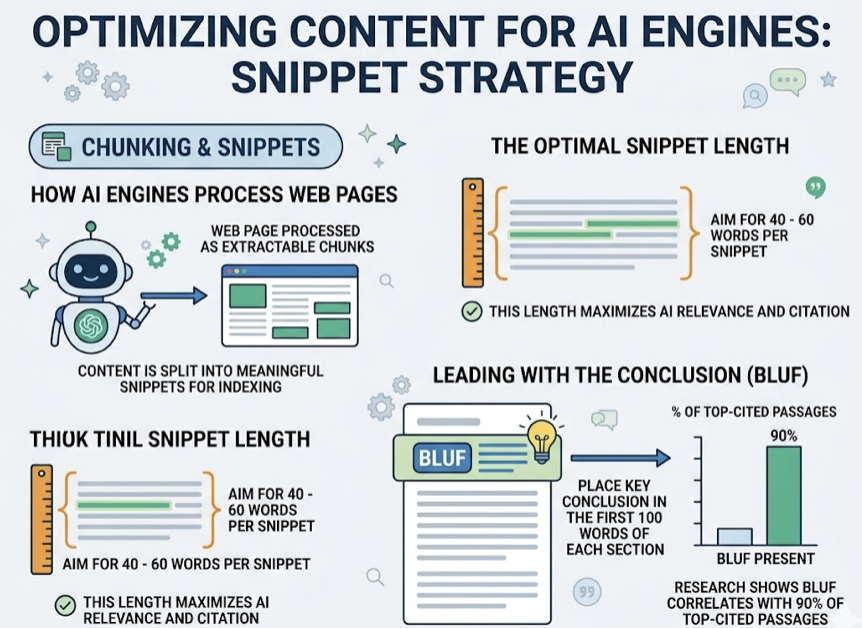
Rewriting H2 and H3 headings as specific, searchable questions also improves extraction rates. “What is GEO?” gets picked up. “Understanding the Research Landscape” doesn’t.
The common thread across all of this: AI engines reward content that’s structured for extraction, not for scrolling. Fact density, clear hierarchy, and self-contained answer blocks are the currency.
How to Track LLM Citations When Every Platform Plays a Different Game
Manual checking doesn’t scale. Running your core prompts across four platforms, noting which sources get cited, and repeating that weekly for every relevant query is a full-time job. And the data decays: citation performance drops to roughly 40% of its initial level within 90 days.
That’s where purpose-built tracking becomes necessary.
Topify approaches this through a seven-metric framework that covers visibility, sentiment, position, volume, mentions, intent, and conversion visibility rate (CVR). But the feature most relevant to LLM citation analysis is its Source Analysis capability.
Source Analysis doesn’t just report whether your brand was mentioned. It identifies exactly which URLs AI platforms cited, how often each page appears across different prompts, and where your competitors are getting cited instead of you. If a competitor’s comparison table keeps showing up in Perplexity’s vendor briefings, Topify flags that as a content gap you can act on.
The cross-platform dimension is where this matters most. Since ChatGPT, Perplexity, Gemini, and AI Overviews share only about 11% of their cited domains, single-platform tracking gives you a distorted picture. Topify monitors all four major US platforms plus regional models like DeepSeek, Doubao, and Qwen, so you can see patterns like: your brand has strong Wikipedia-backed authority in ChatGPT but is invisible in Perplexity because you have zero Reddit presence.
For teams that want a starting point before committing to a full platform, the Topify GEO Score Checker runs a free baseline scan covering AI bot access, structured data, content signals, and visibility. It’s a quick way to identify whether your citation gap is a technical problem (AI crawlers blocked), a structural problem (content not formatted for extraction), or an authority problem (no third-party consensus around your brand).
GEO Score Checker
Conclusion
LLM citation isn’t one game. It’s four separate games running on the same field.
ChatGPT rewards institutional authority and Wikipedia presence. Perplexity chases recency and Reddit consensus. Gemini barely cites at all. AI Overviews borrows from traditional search ranking but applies its own editorial logic.
The brands that win across all four share three traits: their content is structured for extraction (short, fact-dense, BLUF-formatted), their entity exists beyond their own website (Wikipedia, Reddit, G2, industry publications), and they track citation performance continuously rather than auditing once a quarter.
The 11% overlap statistic isn’t just a research finding. It’s a strategic mandate. Optimizing for one platform while ignoring three others means you’re visible to a fraction of the AI search audience.
Start with data. Know where you’re cited, where you’re not, and why. Then build from there.
FAQ
What is an LLM citation?
An LLM citation is a reference link that an AI platform includes in its generated response, pointing to the external source it used to construct its answer. Different platforms handle these differently: Perplexity shows inline numbered citations by default, ChatGPT provides citations selectively, and Gemini rarely includes clickable links at all.
Which AI platform cites the most sources per response?
Perplexity leads by a wide margin, averaging 21.87 citations per response. ChatGPT averages 7.92. Google AI Mode comes in at 8.34. Gemini provides almost no clickable citations in 92% of its responses.
Can I rank well on Google but still be invisible to ChatGPT?
Yes. ChatGPT’s citation logic depends heavily on entity authority, not just search ranking. If your brand doesn’t have sufficient presence on Wikipedia, Reddit, or major industry publications, ChatGPT’s retrieval pipeline may filter you out during the re-ranking phase, even if your page ranks first on Google.
How often should I update content to stay cited by Perplexity?
Perplexity has a strong recency bias. 82% of its cited content was updated within the past 30 days, and citation rates for content older than six months drop to 37%. A monthly refresh cadence for your highest-priority pages is a practical baseline.
Does adding Schema markup actually help with AI citations?
Yes. Pages with properly implemented Schema (FAQPage, Article, HowTo) see citation rates 30% to 47% higher than pages without markup. Schema helps AI models extract structured facts at lower computational cost, making your content easier to cite.

