
You’ve spent months building domain authority, earning backlinks, and climbing Google’s first page. But when a prospect asks ChatGPT for a recommendation in your category, your brand doesn’t show up. The unsettling part: your DA score, your backlink profile, your keyword rankings don’t explain why. That’s because 80% of LLM citations don’t even rank in Google’s top 100 for the same query. The signals that drive AI to cite one source over another are different from what SEO teams have optimized for over the past decade.
An analysis of 30 million AI citations across ChatGPT, Perplexity, Google AI Overviews, and Claude reveals a new set of rules. And for brands still relying on traditional search metrics alone, those rules are already reshaping who gets recommended and who gets ignored.
Only 11% of Sites Get Cited by Both ChatGPT and Perplexity
The first thing to understand about LLM citation is that there’s no single “AI search authority.” Each platform operates on a fundamentally different retrieval philosophy.
Data from a cross-platform citation study shows that only 11% of domains appear in citations from both ChatGPT and Perplexity for the same buyer-relevant prompts. That means 89% of citations are unique to one platform. ChatGPT leans heavily on the Bing index and training data, with Wikipedia accounting for roughly 47.9% of citations in certain knowledge domains. Perplexity, which maintains a proprietary index of over 200 billion URLs, skews toward freshness and community-driven sources. Reddit alone captures 46.7% of Perplexity’s top-tier citations.
Google AI Overviews follow yet another pattern, with 84.9% of responses pulling from the existing Google index and prioritizing E-E-A-T signals plus top-10 rankings.
The practical takeaway: optimizing for one AI platform and assuming it covers the rest is a strategy that misses 89% of the picture.
Brand Search Volume Beats Backlinks as the Top LLM Citation Signal
Here’s the data point that rewrites the playbook. Brand search volume is the strongest predictor of whether an LLM cites a source, with a correlation coefficient of 0.334. That outweighs traditional backlinks, which show a weak or even neutral correlation with AI citation outcomes.
Why? LLMs run on two knowledge systems: parametric memory (what the model learned during training) and retrieval-augmented knowledge (what it finds through real-time search). Brand search volume acts as a proxy for how deeply a brand is embedded in the model’s parametric memory. If people frequently search for your brand, the model develops higher “Entity Confidence” in you. When a retrieval trigger fires, the model is more likely to select and cite sources tied to entities it already recognizes.
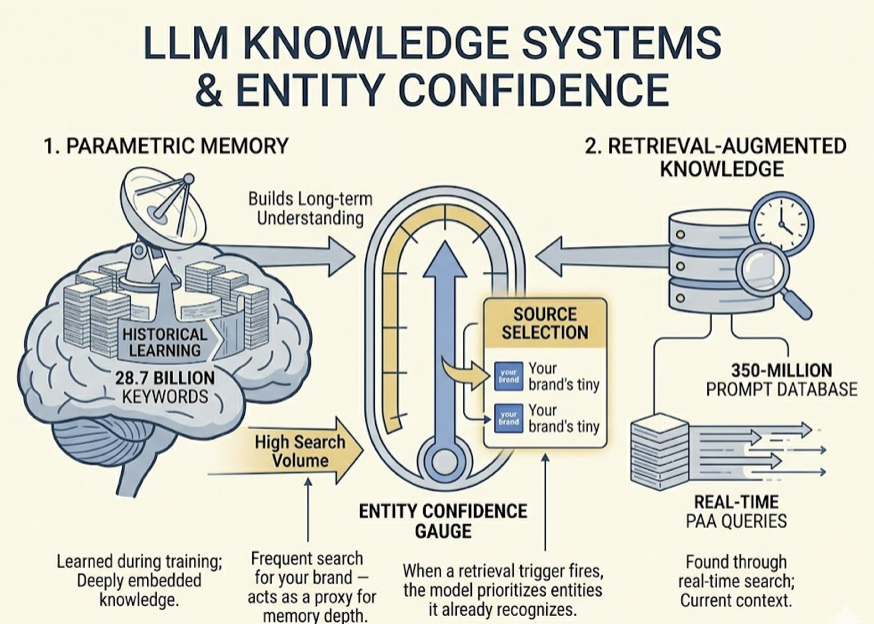
This creates what the research calls a “citation flywheel.” Brands with high search volume get cited more, which reinforces their presence in future training data and retrieval pipelines.
YouTube mentions show an even stronger visibility signal, with a 0.737 correlation with AI citation frequency. That makes brand-building activities like digital PR, community presence, and YouTube visibility more effective for AI search than incremental backlink acquisition.
The shift is clear: “who is talking about your brand” now carries more weight than “who is linking to your page.”
What Content Gets Cited: The 30/44 Rule
LLMs don’t read pages top to bottom the way humans do. They chunk content into modular fragments, and only the fragments that are self-contained and semantically dense survive the selection process. Structure matters more than length.
The data confirms what’s known as the “30/44 rule”: 44% of all LLM citations are extracted from the first 30% of a page’s content. Pages that lead with direct, extractable answers get cited at significantly higher rates than pages that open with background context or definitions.
The Princeton GEO study, which benchmarked optimization techniques across 10,000 queries, measured the impact of specific content signals:
| Optimization Method | Visibility Impact |
|---|---|
| Statistics Addition | +41% improvement |
| Quotation Addition | +37% improvement |
| Fluency Optimization | +15 to 30% boost |
| Expert Citation | +115.1% from Rank 5 baseline |
| Keyword Stuffing | Negative impact |
Adding verifiable statistics and direct quotations are the two most effective methods for increasing LLM citation likelihood. These features act as “trust anchors” for risk-minimizing AI models, which preferentially cite content that provides primary-source data over derivative or promotional material.
Highly cited content also tends to have an entity density of around 20.6%, roughly three to four times higher than standard English prose. And declarative language (“X is Y”) outperforms hedging language (“X might be Y”) by a 14% margin in citation rates.
The “Answer Capsule” strategy, placing a 40-60 word self-contained summary immediately under an H2 heading, has been shown to significantly increase citation probability. Think of it as writing for extraction, not just for reading.
Fan-Out Queries Drive 51% of All AI Citations
When a user types a complex prompt, the LLM doesn’t run a single search. It decomposes the prompt into multiple sub-queries, each targeting a different angle of intent. This process, called “query fan-out,” is one of the most overlooked drivers of LLM citation.
The numbers are striking. Pages ranking for both the main query and multiple fan-out sub-queries account for 51% of all AI citations. Pages that appear in fan-out results are 161% more likely to be cited than pages that only match the primary query. And topic clusters, interconnected pages covering different angles of a subject, capture up to 62% of cross-platform citations.
This behavior structurally rewards comprehensive coverage. A pillar page on “employee retention” supported by sub-pages on exit interviews, onboarding, compensation benchmarking, and manager training will capture more fan-out sub-queries than any single page could. Content optimized narrowly for one keyword is increasingly disadvantaged in generative search.
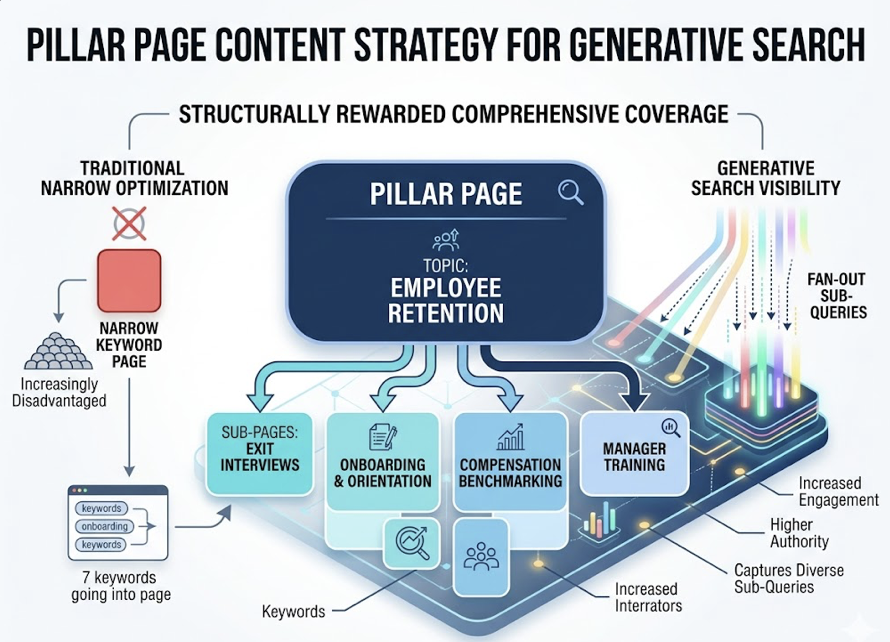
The challenge: unlike traditional keyword research based on search volume, fan-out sub-queries are generated dynamically by the model. Identifying them requires monitoring what questions the AI actually asks behind the scenes, not just what users type.
50-90% of LLM Citations Don’t Fully Support Their Claims
Being cited by AI sounds like a win. But the SourceCheckup study, published in Nature Communications in 2025, found that between 50% and 90% of LLM citations don’t fully support the claims they’re attached to. Across 13 models evaluated, hallucinated citation rates ranged from 14% to nearly 95%.
That’s not an edge case. It’s the norm.
For brands, this means citation ≠ accurate representation. AI models have been observed citing a brand while attributing a competitor’s feature or a fabricated statistic to it. The practical risk is real: your content gets cited, but the AI misrepresents what you actually said.
The user behavior side makes this worse. Research shows that users hover over approximately 12 sources during a traditional search but check only about 2 sources when using an AI answer engine. Users trust AI’s “digital footnotes” more while verifying them less.
This creates a new monitoring imperative. Tracking whether your brand is cited is only half the equation. Tracking what the AI says about you when it cites you is equally important.
How to Track and Optimize Your LLM Citation Performance
The data from 30 million citations points to a clear operational shift: from passive content publishing to active citation monitoring and optimization. Here’s what that looks like in practice.
Build a Prompt Library. Start with 25-50 high-intent queries relevant to your category. Avoid biased phrasing or mentioning your own brand. Run these weekly across ChatGPT, Perplexity, and Google AI Overviews to establish a baseline.
Identify Retrieval Gaps. When a competitor gets cited for a query where your brand should appear, that’s a retrieval gap. Platforms like Topify make this visible by tracking which specific URLs, both owned and third-party, AI engines are using to build their answers. Topify’s Source Analysis feature reverse-engineers AI citations at scale, showing you exactly which domains appear in responses and where your content is missing.
Retrofit Content for Extractability. Apply the 30/44 rule. Move your most citation-worthy content, original statistics, expert quotes, direct answers, into the first third of each page. Use Answer Capsules under H2 headings. Add JSON-LD schema (FAQPage, SoftwareApplication), which has been shown to drive a 67% improvement in AI coverage.
Monitor Citation Quality. Visibility tracking alone isn’t enough. You need to know whether AI accurately represents your brand when it cites you. Topify’s cross-platform monitoring covers ChatGPT, Perplexity, Gemini, and Google AI Overviews, tracking not just mention frequency but sentiment and positioning relative to competitors.
Invest in Brand Signals. The 0.334 correlation between brand search volume and citation probability means that digital PR, community engagement, and YouTube presence aren’t just brand-building activities anymore. They’re direct inputs into your AI citation performance.
86% of AI citations come from sources brands already control or influence, with 44% from owned websites and 42% from business listings and directories. AI search isn’t a black box of uncontrollable community chatter. It’s a data structure problem, and the data is largely within your reach.
Conclusion
The analysis of 30 million AI citations reveals a fundamental disconnect between traditional SEO metrics and the signals that drive LLM citation decisions. Backlinks and Domain Authority still matter for Google rankings, but they’re secondary in AI search. Brand search volume, content structure, semantic density, and fan-out query coverage are the primary drivers now.
The stakes are high. AI search traffic converts at an average rate of 14.2%, compared to 2.8% for traditional organic search. Being the reference source for an AI model is becoming the modern equivalent of ranking number one on Google. The brands that treat LLM citation as a measurable, optimizable channel, rather than a black box, will capture that value first. Get started with Topify to see where your brand stands across AI search today.
FAQ
What is an LLM citation?
An LLM citation is a hyperlink or source reference included in an AI-generated response to attribute information to a specific external source. It signals that the AI is grounding its answer in retrieved data rather than generating purely from parametric memory.
How do I check if my content is cited by AI?
You can manually run category, comparison, and use-case prompts across ChatGPT, Perplexity, and Gemini to see which URLs appear in the “Sources” section. For systematic tracking, platforms like Topify monitor citations and mentions across multiple AI engines automatically.
Do backlinks still matter for LLM citations?
Backlinks show a weak correlation (around 0.218) with AI citation outcomes, compared to brand search volume (0.334) and YouTube mentions (0.737). They still help with initial indexing and general authority, but they’re no longer the primary signal for AI retrieval systems.
How often should I update content to maintain AI citations?
Freshness is a high-priority signal, especially for Perplexity and Bing-powered AI. Content updated within the last 12 months is 3.2x more likely to be cited. High-visibility pages typically follow a 14-to-30-day update cadence.

