
You ran the numbers. Your GEO score came back lower than expected, and now you’re looking at four dimensions wondering which one to actually fix first. Most teams pick the easiest one, or the one that sounds most familiar. That’s usually the wrong call.
GEO score improvement isn’t about effort volume. It’s about fix order. The four dimensions interact, and optimizing Visibility before fixing Authority is roughly equivalent to running ads to a page that doesn’t load. The sequence matters. So does knowing which problems inside each dimension show up most often, and which ones move your score the most.
Before anything else: if you haven’t run a baseline check yet, use the Topify GEO Score Checker to get your dimension-level breakdown. The fixes below are organized to match exactly what you’ll see in that report.
The Fix Order That Actually Moves Your GEO Score
Not all four dimensions carry equal weight. Research into AI citation patterns shows a clear hierarchy:
| Dimension | Role in GEO | Fix Timeline |
|---|---|---|
| Authority | Prerequisite: AI won’t cite what it can’t verify | 3–6 months (compounds) |
| Content Relevance | Lever: fastest scoring gains once entity is established | 30–45 days |
| Sentiment | Filter: blocks recommendations even with strong visibility | 60–90 days |
| Visibility | Outcome: the measure, not the mechanism | Ongoing |
The logic is this: LLMs run an entity resolution check before they surface any content. If the model can’t confirm who you are through third-party corroboration, your on-site optimization goes to waste. That’s why Authority is the prerequisite. Content Relevance is where you gain fast ground once the model recognizes your entity. Sentiment is the last filter before a recommendation is made. Visibility is what you measure, not what you directly control.
Work top to bottom. Here’s what breaks in each dimension, and how to fix it.
Dimension #1 — GEO Authority: The Prerequisite You Can’t Skip
Authority in GEO isn’t about domain rating or backlink count. It’s about what AI systems call “entity confidence”: how consistently and how broadly your brand is described across independent sources. Research shows that unlinked brand mentions are 3x more predictive of AI visibility than traditional backlinks, with a correlation coefficient of +0.664 compared to backlinks, which show roughly -70% predictive correlation with AI citation rates.
This is the dimension most teams underestimate, because it looks nothing like traditional SEO.
Problem 1: AI Platforms Can’t Find Credible Third-Party References About You
When AI models lack external validation for a brand, they become “cautious” by design. The model defaults to recommending established competitors instead. The mechanism behind this is what researchers call the “Consensus Mechanism”: if multiple unrelated sites describe a brand in similar terms for the same use case, the AI treats this as established consensus and cites accordingly.
Fix: Shift from link-building to entity seeding. Identify the trade publications, news outlets, and niche forums that AI platforms use as grounding sources, and secure genuine placements there. A single mention in a Tier 1 outlet carries more signal than dozens of low-authority blog links, because AI models apply “epistemic rigor” when evaluating source quality. Start with 5–10 unlinked mentions in industry-specific publications to establish a Trust Neighborhood.
Problem 2: Your Brand Isn’t Present in High-Authority Training Sources
Wikipedia accounts for roughly 16–48% of ChatGPT’s citation weight, depending on the query type. It isn’t just a search result for LLMs. It functions as the instruction manual that AI systems use to categorize and verify entities. Brands that are absent from Wikipedia and Wikidata carry structural ambiguity that suppresses citation rates.
Fix: Build a proactive presence management strategy. This includes ensuring your brand or methodology has a Wikidata entry with proper “semantic triples” (Subject → Predicate → Object) that eliminate entity ambiguity. Podcast appearances also matter here. Transcripts are increasingly indexed for RAG retrieval, and a guest appearance on a recognized industry podcast creates a verifiable, structured mention that AI systems can extract and attribute.
Problem 3: All Your Citations Point Back to Your Own Domain
Research from AirOps found that top-performing brands in ChatGPT average 4–6 citations from third-party sources versus only 1–2 from their own domain. Brands that rely primarily on self-published content to define their value proposition fail what’s called the “Consensus Check.” If you’re the only source making a claim about yourself, AI confidence scores stay low.
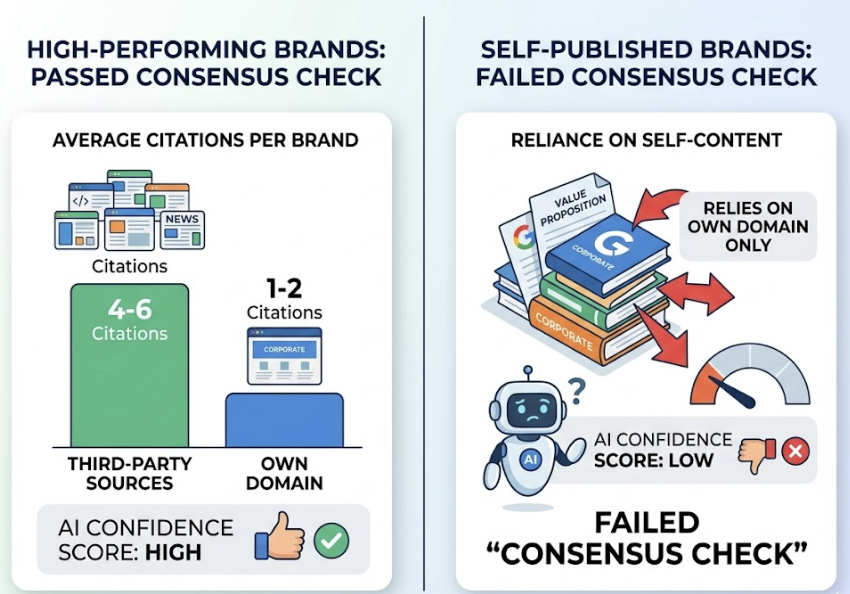
Fix: Audit your current citation footprint. If the majority of your brand’s AI-visible content originates from your own domain, that’s the problem to solve first. Diversify through guest contributions, PR placements, co-authored reports, and genuine Reddit participation. Domain diversity is the strongest predictor of ChatGPT citation rate.
Dimension #2 — GEO Content Relevance: The Fastest Win Available
Once AI systems can resolve your entity, content relevance becomes the highest-leverage dimension for quick scoring gains. Structural changes here, such as reformatting existing pages and adding direct answer blocks, can show measurable improvement in 30–45 days. Authority compounds slowly. Content relevance moves fast.
The core insight: AI systems don’t read pages the way humans do. They “chunk” content into discrete units and retrieve the chunk most likely to answer a specific sub-query. Long-form narrative with a delayed payoff fails at retrieval.
Problem 1: Your Content Answers the Wrong Questions
Most content teams still build around keyword volume. AI search is intent-driven, not keyword-driven. The conversational prompts being sent to AI systems today average 23–60 words, not the 3–4 word queries that defined traditional search strategy. That’s a fundamentally different type of question, and it requires different content to answer.
Fix: Run a prompt mapping exercise against your category. Identify 500–1,000 natural-language questions that buyers ask at different funnel stages: problem discovery, solution comparison, and risk evaluation. Tools like Topify’s AI Volume Analytics can surface high-volume prompts specific to your brand and category, so you’re building content around questions AI is actually being asked, not keyword variants no one is typing anymore.
Problem 2: Your Pages Use SEO Language, Not AI Answer Language
Traditional SEO content is built for dwell time. The payoff often comes after several paragraphs of context-setting. In GEO, that’s a liability. AI engines favor what researchers call “Atomic Knowledge Blocks”: short, self-contained paragraphs of 40–60 words that deliver a complete idea in retrievable form.
Research from Princeton and IIT Delhi found that adding a direct 1–2 sentence answer capsule at the top of a content section correlates with up to a 40% lift in citation frequency. Statistics embedded at roughly one data point per 150–200 words can add 31–37% visibility improvement. Expert quotes with clear attribution carry a 37–41% lift.
Fix: Retrofit your highest-traffic pages first. Rewrite the opening 50 words of each major section as a direct “bottom-line-up-front” answer. Add a relevant statistic or expert citation. Use H2/H3 headers phrased as literal user questions. These are structural changes, not content rewrites. They can be executed at scale without a large content team.
Problem 3: You Have Category Gaps That Competitors Are Filling
Topical authority is the strongest predictor of AI citation, with a correlation coefficient of r=0.41, significantly outperforming domain authority (r²=0.032). Pages in positions 6–10 with strong topical coverage are cited 2.3x more than pages in position 1 with thin or scattered content. Ranking high doesn’t protect you if a competitor owns the semantic depth.
Fix: Run a discrepancy audit. Identify high-intent prompts in your category where competitors are being cited and you’re absent. Priority targets are “Best [category] for [use case]” and “Compare X vs Y” style queries. Use Topify’s Source Analysis to see exactly which domains AI platforms are citing in your category, and map your content coverage against those gaps.
Dimension #3 — GEO Sentiment: The Silent Score Killer
Sentiment is where GEO diverges most sharply from traditional SEO. A search engine ranks a technically sound, high-backlinked page without reading it for tone. A language model does read it, and it makes a judgment about favorability before deciding whether to recommend.
If your brand is associated with negative signals in training data or in actively crawled sources, the model may exclude you from “Best” recommendations entirely, or include you with cautionary framing. That’s not a ranking issue. It’s a sentiment issue, and it won’t respond to on-site optimization.
Problem 1: Negative Third-Party Content Is Being Surfaced Repeatedly
Roughly 85% of AI brand narrative is constructed from third-party domains, not your own website. If critical forum threads, outdated crisis reports, or negative review patterns are being repeatedly surfaced by AI engines, you have an input problem. AI systems don’t fabricate sentiment. They resolve conflicting inputs, and if the majority of external sources frame your brand in negative terms, that becomes the stated consensus.
Fix: Signal dilution, not suppression. You can’t optimize away negative sentiment. The fix is making meaningful, verifiable changes and then generating fresh, positive third-party coverage at volume to shift the overall signal. Reddit is worth specific attention here. It’s the most-cited UGC platform in most AI environments, and authentic participation in relevant subreddits can build authoritative, positive context that dilutes older negative threads.
Problem 2: AI Describes Your Brand in Neutral or Vague Terms
Neutral isn’t safe. If an AI describes you as “one option to consider” or uses vague generic framing, it means the model can’t confidently assign your brand to a specific audience or differentiated use case. This is called Brand Drift, and it typically results from inconsistent positioning across your digital touchpoints.
Fix: Entity hygiene. Audit your brand’s name, category, and primary differentiator across your website, LinkedIn, Crunchbase, G2, social profiles, and any other indexed properties. These descriptors should be identical, not just similar. When multiple sources use the same language to describe your brand, the model’s confidence score rises and the framing becomes consistent and specific rather than vague.
Use Topify’s Sentiment Analysis feature to monitor the exact adjectives and descriptors AI platforms are currently associating with your brand. You can’t fix drift you can’t measure.
Dimension #4 — GEO Visibility: Present, But Not Prominent
Visibility is the output dimension, not an input. It measures “Share of Model” (SoM): how often and how prominently your brand appears across a test set of high-intent prompts. Teams that try to optimize Visibility directly, without fixing the upstream dimensions, tend to see marginal gains at best.
That said, once the foundation is in place, two problems account for most of the gap between brands that appear and brands that get recommended.
Problem 1: You Show Up in AI Answers, But Not in First Position
First-position mentions in AI responses aren’t just more visible. Research shows they capture up to 74% of user attention in Perplexity-style roundups, and they set the framing context for every other recommendation in the response. Being mentioned fifth in a list is functionally different from being mentioned first.
Fix: Analyze the content characteristics of the brands holding first position in your category. AI models preferentially recommend brands they can describe with the highest density of verifiable data: specific pricing, documented outcomes, concrete comparison points. If a competitor owns a label like “best for enterprise teams,” displacing them requires a deliberate comparison matrix strategy that introduces specific, AI-verifiable attributes they don’t have.
Topify’s Competitor Monitoring shows you exactly which brands are holding first-position recommendations in your target prompts, and what signals they’re carrying that you currently aren’t.
Problem 2: You’re Strong on One Platform, Invisible on Others
Only 11% of domains are cited by both ChatGPT and Perplexity, because the platforms rely on different underlying indices. ChatGPT Search favors Wikipedia and news sites through the Bing index. Perplexity leans toward Reddit and real-time content with a strong 30-day recency bias. Google AI Mode correlates most strongly with top-10 organic rankings. Claude applies a high bar for academic and research-grade sources.
A brand can have strong Perplexity visibility through fresh, Reddit-corroborated content and near-zero ChatGPT visibility due to weak foundational authority signals.
Fix: Cross-platform visibility testing. Run your core prompts across multiple AI platforms and map where you appear and where you don’t. That pattern tells you what’s missing: recency signals, foundational authority, or organic ranking health. Topify’s Visibility Tracking covers ChatGPT, Gemini, Perplexity, DeepSeek, and others, so you can see your cross-platform Share of Model in a single view instead of testing manually.
Conclusion
The dimension breakdown exists for a reason. Total GEO score is a lagging indicator. It tells you where you ended up, not where to push. The four dimensions tell you what to fix, and the sequence tells you what to fix first.
Start with Authority. Build entity confidence through third-party corroboration before anything else. Once the model recognizes your brand as a verifiable entity, Content Relevance changes move fast: retrofit your pages with direct answer blocks, close your topical gaps, and embed data density. Sentiment runs in the background as a filter, and Neutral isn’t safe enough. Visibility is what you monitor as the upstream work compounds.
Every one of these fixes is measurable. Use Topify to track your dimension scores as you move through the sequence, so you know when each lever has done its work and it’s time to move to the next.
FAQ
How long does it take to improve a GEO score after making changes?
Structural content changes, like adding statistics, direct answer blocks, and schema markup, can show initial results within 30 to 45 days. Building entity authority through Wikipedia, Tier 1 media mentions, and Wikipedia/Wikidata entries is a longer-term effort that typically compounds over 6 to 12 months.
Which GEO score dimension has the highest weight?
Authority and Entity Clarity carry the highest weight because they’re the prerequisite for retrieval. Without a verified entity signal, content optimization has minimal impact. Research indicates that topical authority and unlinked brand mentions on high-authority sites are the strongest predictors of AI citation rate.
Can I improve my GEO score without a large content team?
Yes. GEO improvement is more about content structure and factual density than content volume. Small teams should focus on retrofitting existing high-traffic pages with atomic knowledge blocks, adding one statistic per 200 words, and ensuring schema and bot-accessibility signals are clean. Those changes don’t require new content, just structural editing of what already exists.

