
You set up AI brand monitoring. You ran 100 prompts across ChatGPT, Gemini, and Perplexity. Then the bill came in.
It wasn’t what you expected.
That’s the experience most marketing teams have in their first month of serious AI visibility tracking. Not because the tools don’t work, but because token pricing is structurally designed to grow faster than your insights. And if you’re using a model like Claude Sonnet or GPT-5.2, the math turns against you faster than anyone tells you upfront.
Here’s how to read the economics clearly, and what to do about it.
What “Token-Based Pricing” Actually Means for Brand Tracking
A token is roughly 0.75 words. It sounds small. In isolation, it is.
The problem isn’t the per-token price. It’s the volume. Every brand monitoring query consumes tokens in two places: the input (your prompt, plus any context or persona instructions) and the output (the AI’s generated analysis). Output tokens are typically three to five times more expensive than input tokens, which changes the math considerably.
On Claude 4.6 Sonnet, input runs $3.00 per million tokens. Output runs $15.00 per million. On Claude 4.6 Opus, those numbers jump to $5.00 and $25.00. For occasional queries, those figures are manageable. For systematic brand monitoring, they’re a different conversation entirely.
The formula is straightforward:
Total query cost = (input tokens × input price) + (output tokens × output price)
What’s not obvious is how fast the inputs grow. A typical monitoring prompt isn’t just a question. It includes a system prompt defining how the AI should behave (500–3,000 tokens), plus context like recent news or forum mentions of your brand (another 2,000–10,000 tokens via RAG). Before the model writes a single word back to you, you’re already in the thousands of tokens.
Why Monitoring 5 Platforms Doesn’t Cost 5x. It Costs More.
Consumer AI behavior is fragmented. Your audience uses ChatGPT for research, Gemini for Google-integrated searches, Perplexity for sourced answers, and Claude for longer reasoning tasks. If you’re only tracking one of these, you’re seeing a fraction of how your brand is actually represented in AI-generated answers.
Cross-platform monitoring is non-negotiable. But the cost structure isn’t linear.
Each platform has its own retrieval logic and “cultural encoding.” Research has found that Chinese-origin models like Qwen and DeepSeek mention brands in 88.9% of English-language queries, compared to 58.3% for international models. That gap requires custom prompt logic per engine, which means more input tokens per platform, not just more queries.
Some platforms layer in additional fees on top of token costs. Perplexity’s enterprise search-grounding option, for example, can add up to $35 per 1,000 queries in certain configurations.
Run the math on a realistic scale: 100 prompts daily across five platforms equals 15,000 interactions per month. At Claude Sonnet’s pricing, with an average of 2,000 input tokens and 500 output tokens per query, that’s roughly $202.50 per month under ideal conditions. In production, the actual cost runs 40–60% higher.
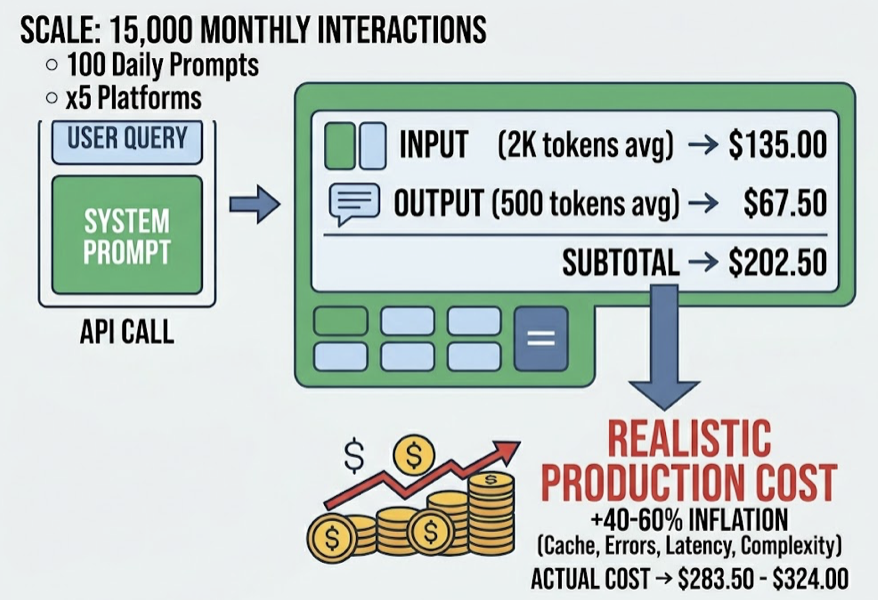
That gap is where the budget problems live.
The 3 Token Drains Nobody Warns You About
1. Long-form answers cost 20x more than simple classifications
Early AI monitoring often used sentiment classification: “Is this review positive? Answer yes or no.” That’s cheap. Output is minimal.
But real brand monitoring requires synthesis: why is this competitor outranking us on this specific query, and what’s the narrative shift happening in AI responses to questions in our category? That kind of reasoning generates long outputs and hidden “chain-of-thought” tokens that are still billed even when they’re not visible in the final response. A detailed competitive breakdown can consume 1,000+ output tokens where a yes/no answer costs 5.
2. Accuracy requires retries, and retries multiply your costs
LLMs hallucinate. They occasionally ignore output schemas or produce malformed JSON that your pipeline can’t parse. To hit enterprise-grade accuracy (around 95% reliability), monitoring systems need self-correction loops, where the model is asked to review and fix its own output.
That second pass consumes the original prompt, the first response, and a new critique instruction. You’re now spending three times the tokens for one usable data point. Analysis of agentic workflows puts the cost at $5–$8 per complex reasoning task. Separately, 43% of AI-assisted workflows experience at least one context reset that forces the model to reprocess the full history from scratch.
That’s not a bug. It’s just how probabilistic systems work at scale. But it’s a cost most monitoring budgets don’t account for.
3. Competitor tracking isn’t passive observation anymore
In keyword-based SEO, tracking a competitor’s ranking was a lookup. In generative monitoring, it’s an active inference task.
When you ask “how does my product compare to Competitor A, B, and C?” the response is structurally longer than a single-brand query. Your system prompt also grows, because the model needs context on each competitor to recognize and evaluate them. Add “query fan-out,” where a single strategic prompt gets broken into 5–10 sub-queries to test different retrieval paths, and the volume multiplies across your entire competitive set.
Tracking three competitors doesn’t add 30% to your monitoring cost. It can double it.
Token-Based vs. Fixed Pricing: The Budget Comparison
| Metric | Token-Based (Raw API) | Fixed Pricing (e.g., Topify) |
|---|---|---|
| Monthly Cost | Volatile: $150–$1,200+ | Predictable: $99–$499 |
| Budget Predictability | Low: spikes with volume | High: locked subscription |
| Monitoring Depth | Capped by current balance | Full tier within plan |
| Technical Overhead | High: keys, retries, normalization | Low: unified dashboard |
| Retry Costs | You absorb every hallucination | Vendor absorbs unreliability |
| Agency Attribution | Complex: token spend by client | Simple: analyses per project |
The raw API approach has a real use case: experimentation. If your engineering team is prototyping a custom internal tool, pay-per-token lets you swap between models freely and discover what works before committing. For that phase, it’s the right call.
The trap is leaving production monitoring on raw API pricing. Brand monitoring is a repetitive, standardized workflow. Running the same 100 prompts every day across five engines is a factory operation. Token volatility is all downside in that context: a model update that makes outputs longer overnight can balloon your monthly bill with no change in the value you’re receiving.
There’s also a business communication problem. A CFO doesn’t want to approve a budget for “50 million tokens.” They want to approve a budget for “competitive intelligence on AI search.” When AI spend is decoupled from business KPIs, it creates what the industry is starting to call LLMflation: spending more every year just to maintain the same level of insight.
What Scalable AI Brand Monitoring Actually Costs
A professional monitoring setup in 2026 typically covers 150–300 prompts tracked weekly across the top AI platforms. That’s the baseline for meaningful visibility data.
Topify structures its pricing around this reality. The Basic plan ($99/mo) provides 9,000 AI answer analyses across 4 projects. That’s enough to monitor 100 high-intent prompts across ChatGPT, Gemini, and Perplexity three times a week, without tracking token consumption on the backend.
The key difference is how the “unreliability tax” gets handled. Unlike static SEO scraping, AI monitoring requires multiple query passes to determine the statistical probability of a brand mention. Topify’s infrastructure runs multi-shot verification internally and delivers a Visibility Score that’s statistically grounded, not just a single data point. The cost of those verification loops doesn’t appear on your bill.
The agency math, made simple
Consider a mid-market agency managing 8 client brands. On raw API pricing, billing becomes a shared-credit nightmare: one client’s PR crisis triples their monitoring volume and burns through the agency’s token budget. A client requesting deep sentiment analysis subsidizes one that only needs basic tracking. Attributing actual costs per client is nearly impossible.
On Topify Pro ($199/mo, 22,500 analyses), the numbers work cleanly:
- 22,500 ÷ 8 clients = 2,812 analyses per client per month
- $199 ÷ 8 clients = $24.88 per client per month
Even if Client A’s situation turns negative and the AI generates longer responses, the agency’s cost stays at $24.88. The token drain is absorbed by the platform. The agency can focus on strategy and client value instead of margin erosion.
6 Questions to Ask Before Signing Any AI Monitoring Contract
Before committing to a monitoring vendor, run through this checklist:
1. Does pricing scale by tokens, prompts, or analyses? Prompt- or analysis-based pricing is predictable. Token-based pricing isn’t.
2. Which models are actually running? The difference between Claude 4.6 Sonnet and Claude 4.6 Opus isn’t just quality. It’s $22 per million output tokens. Make sure you know which tier you’re getting.
3. Does the base plan include multi-platform coverage? Monitoring ChatGPT only tells you part of the story. Confirm whether Gemini, Perplexity, and others are included or add-on costs.
4. Is there built-in hallucination detection? Without a verification loop, your data quality is unreliable. Ask whether the vendor handles retry logic internally or passes that cost (and complexity) to you.
5. Can you attribute usage by client or project? For agencies especially, this is non-negotiable. Cost visibility per client is what makes the model billable.
6. Are real-time search grounding fees included? Some platforms charge separately for grounded search queries. That $35 per 1,000 queries adds up faster than the token cost itself.
Conclusion
Token pricing isn’t inherently bad. It’s the right model for exploration, for custom tooling, for one-off deep analysis that needs a flagship model’s reasoning. That use case is real and it matters.
But brand monitoring isn’t exploration. It’s a factory. The same prompts, the same platforms, the same competitive set, run on a weekly or daily cadence. In that context, token volatility is pure operational risk with no corresponding upside.
The organizations getting this right in 2026 are treating token-based access as a prototyping layer and production monitoring as a fixed-cost intelligence subscription. That split isn’t about cutting corners. It’s about building a measurement system that actually scales without the economics working against you.
When your CFO asks what you spent on AI visibility last quarter, “it depends on how many tokens the model used” is not a defensible answer.
Frequently Asked Questions
How many tokens does it take to monitor a brand on ChatGPT?
A single monitoring query typically uses 2,000–13,000 input tokens (prompt plus context) and 500–1,500 output tokens depending on the complexity of the analysis. For a basic mention check the lower end applies; for competitive sentiment breakdowns, expect the higher end. At Claude Sonnet 4.6 pricing, that’s roughly $0.01–$0.06 per query before any retry costs.
Is there an AI brand monitoring tool that doesn’t charge by token?
Yes. Platforms like Topify use a prompt/analysis-based pricing model, where you pay for a monthly volume of analyses rather than the underlying token consumption. This means the vendor absorbs retry costs and verification overhead, and your monthly spend stays predictable regardless of output length or model behavior.
How does Claude’s token pricing compare to other AI models for brand monitoring?
Claude 4.6 Sonnet sits at $3.00/1M input and $15.00/1M output, making it a mid-tier option suited for general visibility tracking. Claude 4.6 Opus ($5.00/$25.00) is better for high-stakes reputation or legal risk analysis where reasoning depth matters. For high-volume, lower-complexity tasks, budget models like GPT-5.2 Nano ($0.05/$0.40) can significantly cut costs, but at the expense of analytical depth.

