
You just ran a brand audit. Your SEO metrics look solid. Then you ask ChatGPT, “What’s the best tool for [your category]?” and read through the response. Your brand isn’t mentioned. You switch to Claude and ask the same question. Different answer, different brands, same problem: you’re invisible on both.
The real question isn’t which AI model is smarter. It’s which one your buyers actually use when they’re deciding, and whether your content is doing anything to show up in either.
Two Models, Two Ways of Recommending Brands
Claude Opus 4.8 and GPT-5.5 don’t just process queries differently. They have fundamentally different recommendation logics, and that gap matters for any brand trying to optimize its AI search visibility.
Anthropic’s Opus 4.8 is built for high-effort, multi-step reasoning. Internally, it’s been called a “deliberate researcher.” It prioritizes dense, technical content: whitepapers, detailed documentation, decision-making frameworks. If your content explains why something works, not just what it does, Claude Opus 4.8 is more likely to surface it.
GPT-5.5 operates differently. It’s designed for speed and decisiveness. It weights historical conversation context heavily and tends to favor brands with established “top-of-mind” digital authority. If you’re a well-known brand with broad presence across mainstream publications and forums, GPT-5.5 will find you more readily.
That’s the core asymmetry: Claude rewards depth, GPT rewards reach.
Where Each Model’s Users Actually Live
Market share matters for GEO decisions. According to Brand24’s 2026 market usage report, ChatGPT holds over 70% of the AI assistant market. That number alone makes GPT-5.5 the default priority for most consumer-facing brands.
But user demographics tell a more nuanced story.
| Dimension | Claude (Claude.ai) | ChatGPT (ChatGPT.com) |
|---|---|---|
| Primary Audience | Developers, researchers, enterprise (deep work) | General consumers, creatives, mass-market B2B |
| Where They Congregate | GitHub, technical forums, Slack | News outlets, social media, general web |
| Decision-Making Style | Deliberate, research-heavy | Faster, outcome-first |
| Market Share | Niche but highly engaged | Mainstream (~70%+ share) |
If your buyer’s journey involves technical evaluation, RFP processes, or high-stakes B2B purchasing, Claude’s audience skews heavily toward that segment. If your category depends on mass-market awareness or fast consumer decisions, GPT-5.5 is where the volume is.
Neither model’s audience is wrong for you. The question is which one matches where your buyers currently spend their AI research time.
What GEO Actually Means for Model-Specific Optimization
Generative Engine Optimization is not SEO with a new name. Evertune and SearchEngineLand’s 2026 GEO industry reports make the distinction clear: SEO targets click-through rates, GEO targets citation frequency and inclusion rates.
That shift in measurement changes what good content looks like.
Three factors drive citation frequency across both models:
Content Extractability. AI models reassemble information, not pages. Clean HTML structure with clear headings and lists makes it easier for both Claude and GPT to identify the “answer” within your content. Buried insights in walls of text rarely get cited.
Entity Clarity. Explicitly define your brand, product category, and target use case. Both models perform better when they can map a brand to a specific entity in their knowledge graph. Vague positioning hurts visibility on both platforms.
Attribution Authority. Unlike traditional SEO, where any backlink helps, GEO favors authoritative sourcing. Mentions in industry-specific publications, Reddit threads, and G2 or Capterra reviews act as validation signals. Both models weight these, though Claude tends to favor technical and academic citations more heavily.
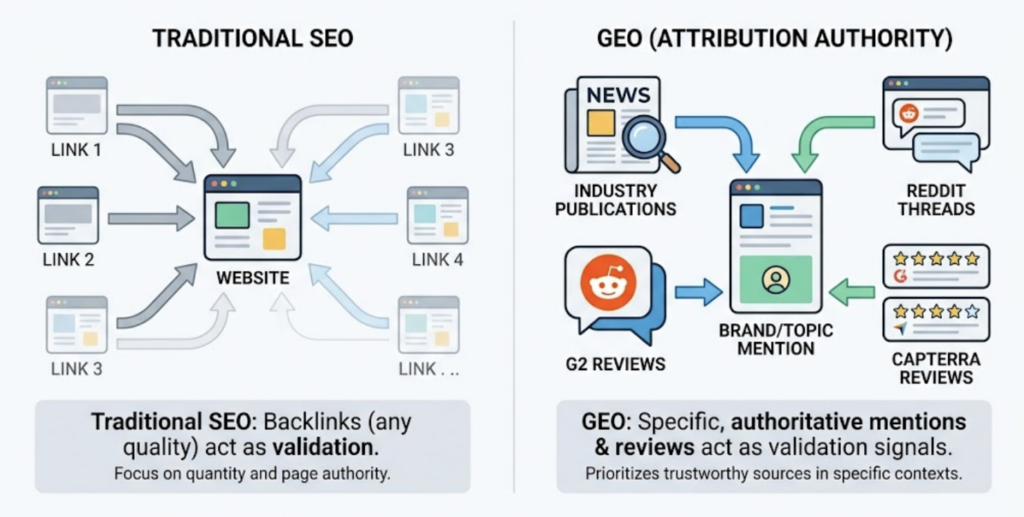
The execution, though, diverges significantly by platform.
5 Signals That Tell You Which Engine to Prioritize
Before you allocate resources, run through these five signals. They’re faster than intuition and more reliable than guessing.
Signal 1: Your natural mention baseline. Use an AI monitoring tool to check which engine already mentions your brand in organic queries. The platform where you already have traction is worth reinforcing before building from scratch on the other.
Signal 2: Competitor dominance. If your main competitors have locked down GPT-5.5 recommendations through years of content investment, the cost of entry is higher. Claude may offer a lower-competition path to authority, especially in technical verticals. Tools like Topify‘s Competitor Monitoring track where rivals rank across platforms, giving you a clearer picture of where the territory is still open.
Signal 3: Content format alignment. Your existing content signals which platform you’re naturally suited for. Long-form technical content, whitepapers, and in-depth how-to guides align with Claude’s citation preferences. Short, outcome-focused FAQs and conversational copy align with GPT’s. Don’t force a mismatch.
Signal 4: Industry vertical. Does your industry live on developer platforms, technical forums, or GitHub? Claude’s user base concentrates there. Is your audience on mainstream news outlets, Instagram, or general search? That’s GPT territory.
Signal 5: Keyword “ask” frequency. The phrasing of queries tells you a lot. “How to build…” and “Why does X work…” skew toward Claude’s user behavior. “Best tool for…” and “Top [category] recommendations” skew toward GPT’s conversational style. Match your content strategy to the question format your audience is actually using.
The Case for Starting With Claude Opus 4.8
Some brands should go Claude-first. Not because it has more users, but because its audience is more aligned with how those brands get evaluated.
According to Anthropic’s positioning for Opus 4.8, the model is tuned for high-effort tasks and “proactive error-flagging.” That means it actively evaluates the quality and nuance of the content it cites. If your brand sells a complex product with long sales cycles, technical documentation that explains decision-making frameworks will consistently outperform generic marketing copy in Claude’s recommendation outputs.
The practical implication: invest in content that provides decision support, not just awareness. Technical whitepapers, integration guides, and deep-dive comparison articles give Claude Opus 4.8 something to work with. For teams that want to monitor how their technical content is being cited, Topify’s Source Analysis tracks the exact domains Claude and other AI platforms reference, making it easier to identify which content is being picked up and which isn’t.
Claude-first makes sense for: B2B SaaS, developer tools, enterprise software, professional services, and any category where the buyer conducts research before engaging sales.
The Case for Starting With GPT-5.5
For most consumer brands and general B2B companies, GPT-5.5 is the right starting point. The user volume is simply too large to ignore.
OpenAI’s framing for GPT-5.5 Instant emphasizes personalization and prompt guidance. The model is designed to be decisive, favoring content that mirrors natural conversational queries. That creates a specific optimization target: your FAQ architecture.
A brand that builds a robust FAQ section reflecting exactly how buyers phrase their purchase-stage questions (“What’s the best [category] for small teams?”, “How does [your brand] compare to [competitor]?”) creates more citation surface area for GPT-5.5 than a brand that publishes polished brand journalism nobody is actually asking about.
Brand salience also matters more here than on Claude. Consistent presence in mainstream industry newsletters and news publications builds the kind of broad digital authority that GPT-5.5 uses as a relevance signal. It’s less about depth, more about distributed presence.
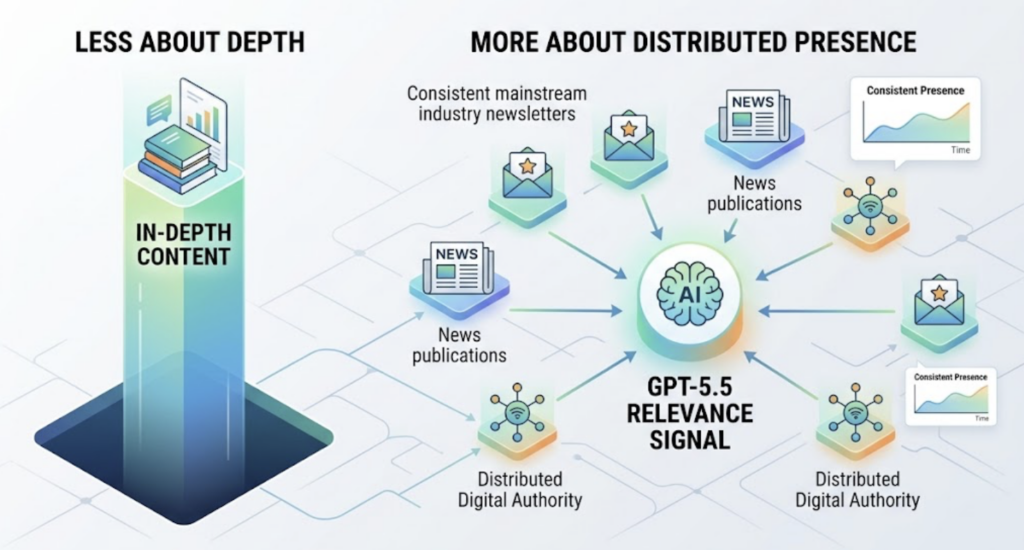
GPT-first makes sense for: ecommerce, consumer tech, SMB-focused SaaS, content media brands, and any category where buyers make faster decisions with less technical evaluation.
You Don’t Have to Guess: Track Both, Prioritize One
The five signals above give you a starting point. But AI recommendation patterns shift faster than most content strategies can react to. What Claude Opus 4.8 cites this quarter may look different from what it prioritizes after a model update. GPT-5.5’s weighting on brand authority isn’t static.
That’s why the practical answer isn’t “optimize for one and ignore the other.” It’s “pick your primary platform based on where your audience is, then monitor both so you know when that changes.”
Topify’s cross-platform visibility tracking covers ChatGPT, Claude, Perplexity, Gemini, and other major AI platforms simultaneously. Its AI search monitoring dashboard maps your Visibility Score, Sentiment, and Position Rank across platforms, so you can see at a glance whether your GEO efforts are moving the needle on the engine you’re targeting, without losing visibility into the one you’re not. If you want to benchmark where you currently stand across both platforms before deciding, Topify offers a free GEO score check that doesn’t require a signup.
The brands that will win in AI search over the next two years won’t be the ones that picked the right model. They’ll be the ones that measured fast enough to respond when the models changed.
Conclusion
Claude Opus 4.8 rewards depth, technical authority, and content that helps users make complex decisions. GPT-5.5 rewards reach, brand salience, and content that mirrors how buyers talk when they’re close to choosing. Both matter. Your buyer’s behavior tells you which one to build first.
Start with the platform where your audience already researches. Build content that matches how that platform cites information. Then measure the results before you expand to the other. That’s not a hedge. That’s how you avoid spending six months optimizing for an audience that isn’t yours.
FAQ
Q: Is Claude Opus 4.8 better than GPT-5.5 for brand visibility?
A: Neither is universally better. Claude Opus 4.8 tends to favor technical, in-depth content and serves a more engaged enterprise and developer audience. GPT-5.5 has broader reach and weights brand salience and conversational content more heavily. Which performs better for your brand depends on your audience, content format, and industry vertical.
Q: Can I optimize for both Claude and GPT-5.5 at the same time?
A: Yes, but the strategies diverge enough that splitting focus too early often produces mediocre results on both platforms. A better approach is to prioritize the platform where your audience is most active, build a clear GEO footprint there first, then expand. Monitor both from the start so you have baseline data when you’re ready to scale.
Q: How do I know which AI engine my target audience uses most?
A: Start with your buyer persona’s professional context. Technical buyers, developers, and enterprise researchers skew toward Claude. General consumers and SMB buyers skew toward ChatGPT. Beyond persona assumptions, AI visibility monitoring tools can show you which platform already generates natural mentions for your brand or your competitors, giving you concrete data rather than educated guesses.
Q: Does GEO strategy differ between Claude and GPT-5.5?
A: Significantly. For Claude Opus 4.8, GEO strategy centers on content depth: whitepapers, technical documentation, decision-making frameworks, and authoritative citations in industry publications and forums. For GPT-5.5, strategy focuses on conversational FAQ architecture, broad brand presence across mainstream channels, and short-form content that mirrors how buyers phrase purchase-stage questions. The underlying GEO principles (entity clarity, content extractability, attribution authority) apply to both, but the content format and distribution channel priorities are different.

