
Most marketers track Google rankings. A few track ChatGPT mentions. Almost none are watching what Claude does with their brand, even as Claude Opus 4.8 quietly becomes the engine behind more AI-generated answers across the platforms their customers actually use.
That gap is getting expensive.
What Claude Opus 4.8 Actually Is (and Where It Sits in the AI Landscape)
Claude is Anthropic’s flagship AI model family, and it runs on a three-tier architecture. Haiku handles speed and low-cost tasks. Sonnet balances performance and efficiency. Opus is the top tier, designed for deep reasoning, nuanced judgment, and complex multi-step tasks.
Claude Opus 4.8, released May 28, 2026, is the most capable model in that tier to date. It’s not a speed upgrade or a cost cut. The defining changes are behavioral: the model is better at knowing when it’s wrong, better at executing long autonomous workflows, and more precise when calling external data sources.
For the average marketer, the translation is simple. Opus 4.8 is the AI version of a senior analyst who won’t bluff through uncertainty and won’t cut corners on complex research.
The 4.8 Upgrades That Change How AI Reads Your Brand
Five changes in 4.8 have direct implications for brand visibility. Not all of them are obvious.
Honesty calibration. According to Anthropic’s launch announcement, Opus 4.8 is approximately 4x less likely than 4.7 to let errors in its own output go unremarked. It flags uncertainty rather than filling gaps with confident-sounding guesses. In practice, this means your brand content either holds up under factual scrutiny or gets quietly omitted from AI-generated answers.
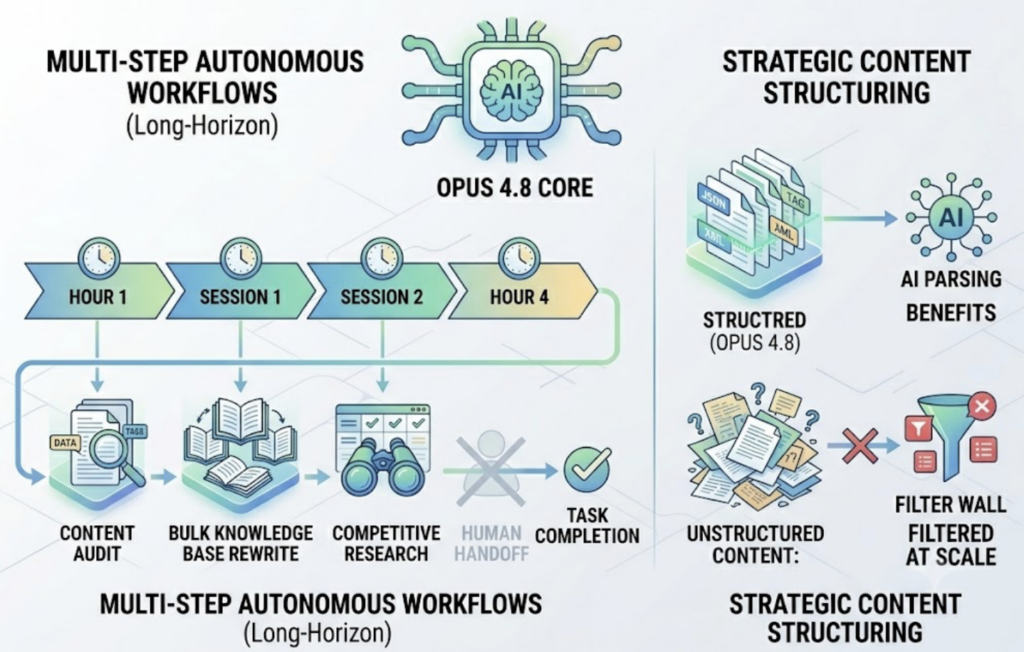
Agentic reliability. Opus 4.8 is built for “long-horizon” tasks: multi-step autonomous workflows that can run across hours or multiple sessions. Content audits, bulk knowledge base rewrites, and competitive research are now tasks the model can complete end-to-end without human handoffs. Brands that structure their content for AI parsing will benefit; those that don’t will get filtered out at scale.
Effort dial on claude.ai. Users now have explicit control over how much “thinking” the model applies to a task. High effort is the default. This means Opus 4.8 will spend more tokens evaluating a query before answering, which translates to more selective citation behavior and fewer hallucinated brand facts.
Fast mode efficiency. A new fast mode is 2.5x faster and roughly 3x cheaper than previous versions. This lowers the barrier for customer-facing AI applications powered by Claude, which means more consumer touchpoints where brand recommendations get generated.
Tool-calling precision. Opus 4.8 is more accurate at retrieving external data in real time. Brands with structured, API-accessible content have a new advantage: the model can pull and cite their data directly, rather than relying solely on training-time knowledge.
Where Claude Opus 4.8 Shows Up in the Real World
Claude isn’t just Claude.ai. The model powers a growing stack of products and integrations that your potential customers use daily: Perplexity’s Pro mode, enterprise AI deployments via Amazon Web Services, developer tools built on Anthropic’s API, and third-party AI assistants across B2B SaaS.
Every time a user asks one of these products for a vendor recommendation, a product comparison, or a solution to a business problem, Opus 4.8 is potentially generating that answer. And generating it with less tolerance for ambiguity than its predecessors.
That’s the part most marketing teams haven’t fully internalized yet.
Why a More “Honest” Claude Changes What Gets Cited
The relationship between AI model quality and brand visibility isn’t linear. Better models don’t just cite more brands. They cite more selectively.
Opus 4.8’s honesty calibration creates a higher bar for what counts as a citable source. Content that is structured clearly, factually consistent, and backed by third-party validation tends to survive this filter. Content that is vague, marketing-heavy, or contradicted by external sources tends to get dropped.
AIWiz UK’s analysis of the 4.8 release describes this shift as AI models becoming increasingly sensitive to “conflicting or unsupported information.” The implication for content strategy: keyword density matters far less than factual scaffolding. If your product page says one thing and your support docs say another, Opus 4.8 will notice.
Clear HTML structure also plays a role. The model performs best when content is organized into distinct sections, whether that’s benefit grids, feature lists, or structured product statements. Unstructured marketing prose is harder for the model to extract, summarize, and cite accurately.
3 Things Marketers Should Do Before the Next Model Update
Model updates happen faster than most content calendars move. Waiting for the dust to settle is no longer a viable strategy. Here’s where to start.
Audit how AI currently describes your brand. Pull up Claude, Perplexity, and ChatGPT. Ask each one to describe your product, compare it to competitors, and recommend it for a specific use case. Document what you find. If the descriptions are inaccurate, generic, or missing key differentiators, your web presence likely lacks the structured documentation AI models need to generate accurate answers.
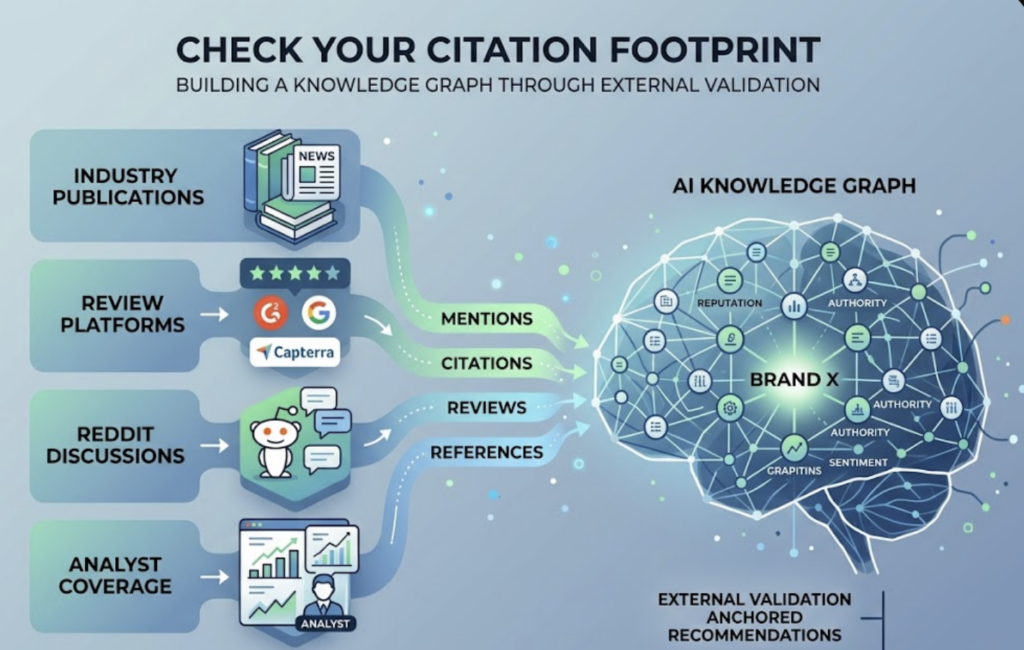
Check your citation footprint. AI models build their “knowledge graph” of a brand through third-party references: industry publications, review platforms like G2 and Capterra, Reddit discussions, and analyst coverage. If your domain isn’t appearing in these high-authority contexts, the model has little external validation to anchor its recommendations. One of the most practical first steps is running a source analysis to see which domains AI platforms are citing in your category and whether yours is on the list.
Build a monitoring system, not a one-time audit. Opus 4.8 is not the last version. Anthropic will ship 4.9, or 5.0, and each update will recalibrate citation behavior. Static audits give you a snapshot. What you need is a live view of how AI models are representing your brand week over week.
How to Track Brand Visibility Across Claude and Other AI Platforms
Manual testing across Claude, ChatGPT, Perplexity, and Google AI Overviews doesn’t scale. Running the same prompts across four platforms, logging the outputs, and tracking changes over time is a full-time job for a team, not a monthly checklist item.
Topify is built specifically for this problem. It monitors brand performance across major AI platforms using seven metrics: Visibility Score, Sentiment Score, Position Rank, AI Volume, Mentions, Intent alignment, and CVR (Conversion Visibility Rate). Rather than showing you raw AI outputs, it surfaces what changed, what caused the change, and what to do about it.
The Source Analysis feature is directly relevant to the Opus 4.8 shift. It tracks which domains AI platforms are citing in your category, giving you a clear signal about where your citation footprint is strong and where it’s missing. That data feeds directly into content strategy decisions: which third-party sites to target for coverage, which product pages need structural cleanup, and which competitor sources are being cited instead of yours.
For marketing teams already stretched across SEO, paid, and social, Topify’s one-click agent execution means you can deploy a GEO optimization strategy without building a manual workflow from scratch. Define your goals, review the proposed strategy, and let the system handle execution.
Basic plans start at $99 per month, covering 100 prompts and 9,000 AI answer analyses across ChatGPT, Perplexity, and AI Overviews. For teams managing multiple brands or clients, the Pro tier at $199 per month expands to 250 prompts and 22,500 analyses.
Conclusion
Claude Opus 4.8 isn’t just a better AI. It’s a stricter one. It hallucinates less, cites more carefully, and runs longer autonomous workflows that touch more of the customer journey than any previous version.
For marketing teams, that means the window for passive brand visibility is closing. AI models are getting better at ignoring content that doesn’t hold up to scrutiny, and better at surfacing brands that have built real citation authority across the web. The brands that understand this now, and build monitoring and optimization into their regular workflow, will have a structural advantage that compounds with every model update. The ones that wait will keep asking why they’re not showing up in AI answers and keep not finding the answer in their SEO dashboards.
Get started with Topify to see where your brand stands across the AI platforms your customers are already using.
FAQ
Q: Is Claude Opus 4.8 available to the public?
A: Yes. Claude Opus 4.8 is accessible via claude.ai for Claude Pro subscribers and through Anthropic’s API for developers and enterprise customers. It’s also available through cloud providers including Amazon Web Services.
Q: Does Claude Opus 4.8 affect traditional SEO rankings?
A: Not directly. Opus 4.8 doesn’t change how Google indexes or ranks web pages. What it does affect is how your brand appears in AI-generated answers on Claude, Perplexity, and any application built on Anthropic’s API. Those are separate from SERP rankings and require different tracking and optimization approaches.
Q: How is Claude Opus 4.8 different from ChatGPT for marketers?
A: Both generate brand recommendations, but their citation behavior and training data differ. Claude Opus 4.8’s emphasis on honesty calibration makes it particularly sensitive to content accuracy and source quality. ChatGPT and Claude will often surface different brands for the same query, which is why monitoring both matters. Relying on one platform’s behavior to predict the other is a common mistake.
Q: Should I create separate content optimized specifically for Claude?
A: Not exactly. The content signals Claude Opus 4.8 responds to, clear structure, factual accuracy, third-party citation authority, are the same signals that improve performance across all major AI platforms. A GEO strategy optimized for these fundamentals tends to lift visibility across ChatGPT, Perplexity, and Claude simultaneously rather than requiring platform-specific content.

