
Your domain authority is solid. Your keyword rankings are where they should be. But none of that tells you whether Claude Opus 4.8 is recommending your competitor when a user asks, “What’s the best tool for [your category]?”
That’s the gap most brands haven’t measured. And with Claude Opus 4.8 now handling a growing share of AI-assisted decisions, the cost of being invisible to it is no longer hypothetical.
Claude Opus 4.8 Isn’t a Search Engine. It’s a Referee.
Most marketers assume Google rankings translate directly to AI search visibility. They don’t.
Search engines index, rank, and surface links. Claude Opus 4.8 does something fundamentally different: it synthesizes patterns from its training data and reconstructs what it “knows” about your brand from memory. There’s no real-time crawl, no live index, no backlink graph to climb.
According to Anthropic’s Claude Opus 4.8 technical system card, the model was built with a strong emphasis on honesty and agentic reasoning. That means it’s designed to be more selective—and more skeptical—about which sources and brands it cites. If your brand doesn’t have a strong enough footprint in the data it was trained on, it’s not downranked. It’s simply absent.
That’s a meaningful distinction. An absent brand gets no second chance from a better meta description.
The 4 Signals Claude Opus 4.8 Uses to Decide on a Brand
Research into how Claude AI chooses brands points to four core signals that shape which names the model surfaces and how confidently it cites them.
Source Authority: The Anchor Signal
Claude Opus 4.8 shows a strong preference for brands that appear in authoritative, editorial sources—industry journals, established tech publications, credible documentation sites.
These aren’t just “high-DA” domains in the SEO sense. They’re sources that humans have historically trusted to provide accurate information, which means the model treats them as grounding anchors when forming its understanding of a category.
A brand mentioned once in a roundup post on a niche blog carries far less weight than a brand cited in a Gartner analysis, a Product Hunt discussion thread with hundreds of upvotes, or a well-referenced Wikipedia entry.
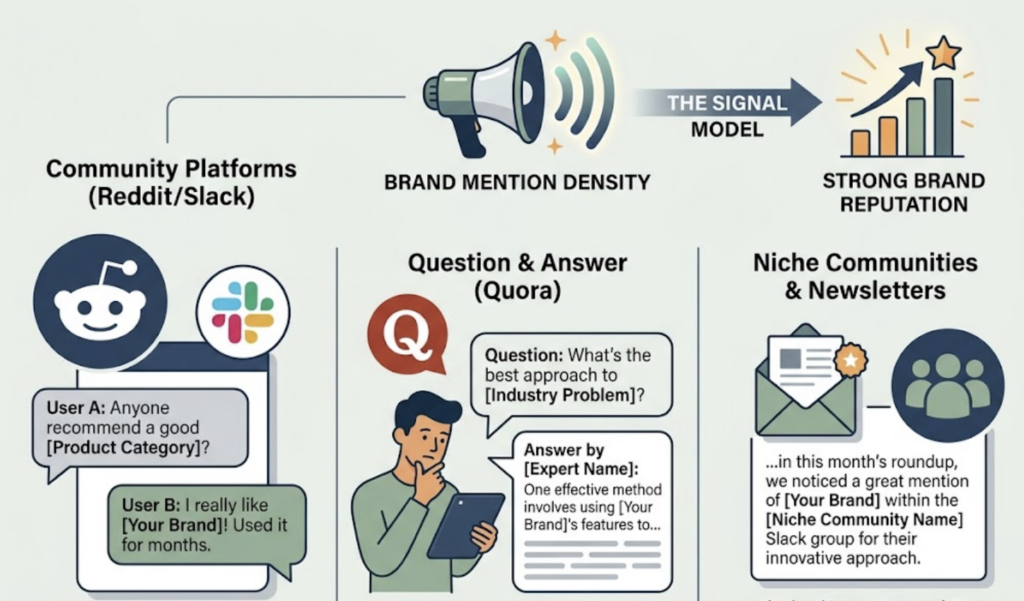
Mention Density: Statistical Weight Across the Web
Frequency acts as a proxy for relevance. If your brand appears across hundreds of independent, contextually relevant sources—Reddit threads, G2 reviews, Medium posts, industry newsletters, niche community forums—the model registers a statistical consensus.

Research on training data frequency and brand citation patterns confirms that mention density across diverse platforms is one of the most consistent predictors of LLM recall. It’s not about one high-profile placement. It’s about breadth.
Sentiment Consistency: Narrative Stability
Claude Opus 4.8 is specifically tuned for what Anthropic calls “honesty calibration.” According to analysis of Opus 4.8’s agentic capabilities, the model reports a 4x reduction in unsupported claims compared to prior versions.
In practice, that means the model is more likely to avoid citing brands that have contradictory descriptions across different sources. If your product is described as “enterprise-grade” on your site but “a budget alternative” in third-party reviews, the model may hedge—or skip your brand entirely to avoid making an unsupported claim.
Consistent messaging across all digital touchpoints isn’t just a brand strategy concern. It’s now an AI visibility concern.
Category Dominance: Semantic Association
The model must be able to map your brand clearly to a category and a problem. Not vaguely—specifically.
Think: “Brand X is a leading CRM for mid-sized teams” or “Brand Y is the go-to platform for AI search visibility tracking.” That kind of explicit category-to-brand association, repeated across multiple credible sources, is how Claude builds the semantic connection needed to recommend you by name when a user asks a category-level question.
Generic positioning kills this. If your brand is described differently depending on the channel, the model can’t establish a clean association.
Why Your Brand Might Be Invisible to Claude Right Now
Three patterns account for most of the brand invisibility cases in Claude Opus 4.8.
First: missing high-authority citations. If your brand is primarily mentioned in self-published content or low-signal platforms, the model doesn’t have enough grounding material to cite you with confidence.
Second: brand name ambiguity. If your product name is also a common word or shares a name with another product, the model may consistently resolve the ambiguity toward the more established entity.
Third: fragmented content presence. A brand that publishes strong content but only on its own domain hasn’t built the cross-source footprint that LLMs use to establish credibility.
Claude doesn’t rank you. It remembers you.
And if it can’t remember you clearly, it won’t cite you at all.
What Changed in Claude Opus 4.8 That Brands Need to Know
The upgrade from earlier Claude versions to Opus 4.8 isn’t just a capability improvement. It changes how the model evaluates the quality of information it synthesizes.
Anthropic’s release notes for Opus 4.8 introduced effort-control settings that let users configure how deeply the model reasons through a query. On default “High Effort” settings, the model is designed to think more carefully rather than pattern-match to shallow content.
The practical effect: keyword-stuffed content and generic marketing copy are increasingly filtered out by the model’s reasoning process. Content that provides specific, verifiable, actionable information gets prioritized. Content that makes unsupported claims gets deprioritized or ignored.
That’s a meaningful shift. What worked as SEO content in 2023 may now actively hurt your chances of being cited by Claude Opus 4.8—not because the content is penalized, but because it doesn’t meet the model’s threshold for credibility.
Brands that have invested in technical documentation, documented case studies, and third-party validation are better positioned in this environment than brands relying on volume-based content strategies.
The Brands Claude Opus 4.8 Tends to Recommend
The brands that appear most consistently in Claude Opus 4.8’s recommendations aren’t always the largest or most heavily funded. They share a different profile.
According to research on the psychology of brand mentions and training data signals, the common thread is what researchers call “Semantic Certainty”: the model has encountered the brand often enough, across credible enough sources, with consistent enough messaging, that it can cite the brand without risking an unsupported claim.
In practical terms, that means:
- Cited in at least a handful of authoritative sources (not just self-published)
- Mentioned across multiple independent platforms with similar descriptions
- Clearly associated with a specific problem or category in the model’s training data
- Described in a way that holds up under the model’s honesty calibration
The bar isn’t impossible. But it requires a systematic approach, not a one-off PR push.
How to Track Whether Claude Opus 4.8 Is Recommending Your Brand
Here’s the problem: Claude doesn’t provide a rank tracker. There’s no search console equivalent for LLM visibility. You can’t log into a dashboard and see “Your brand appeared in 34% of relevant Claude queries this month.”
That gap is exactly where Topify operates. Topify’s AI search visibility platform tracks how brands appear across major AI engines—ChatGPT, Gemini, Perplexity, Claude, and others—at the prompt level.
The key metrics Topify surfaces for teams trying to understand their Claude visibility:
Visibility Score: How often your brand appears in response to category-level prompts, across tracked AI platforms. A drop in this score often signals a change in how training data or citation patterns are shifting.
Share of Model: Your brand’s relative presence compared to competitors across the same set of prompts. This is the AI equivalent of share of voice—and it’s the metric that tells you whether Claude is recommending you or your competitor.
Source Analysis: Which domains Claude and other AI engines are pulling from when they cite brands in your category. If a specific forum or third-party review site consistently appears as a citation source for your competitors, that’s your next content target.
Position Rank: Where your brand appears in AI-generated recommendation lists. Being mentioned is different from being mentioned first.
Because each AI model is trained on a different corpus, cross-platform monitoring matters. A brand can have strong visibility in ChatGPT and near-zero presence in Claude Opus 4.8 if the training sets diverge. Topify’s AI search visibility tracking covers this cross-platform gap in a single view.
Three Things You Can Change This Week
Most brands can’t rewrite their entire content strategy overnight. But there are three moves that have an outsized effect on LLM brand visibility, and none of them require a full GEO overhaul.
Audit your citation sources. Use Topify’s Source Analysis to identify which domains AI engines are pulling from in your category. Then cross-reference your brand’s presence on those exact platforms. If you’re not there, that’s your gap. Getting a mention on a site the model treats as authoritative is worth far more than ten mentions on low-signal platforms.
Standardize your brand description. Pull your brand’s descriptions from your own site, G2, Capterra, Reddit, and any major review or community platform. Look for contradictions in how your product is positioned. Resolve them. Consistency across sources is a direct input into the model’s confidence when citing you.
Build a presence on independent platforms. Owned content matters, but the model’s sense of your brand comes from sources it treats as independent. Reddit threads where users recommend your product, thoughtful answers on Quora, community mentions in niche Slack groups or newsletters—these build the “mention density” signal in a way that your own blog cannot.
Get started with Topify to run a baseline visibility check across AI platforms before you make changes. You can’t optimize what you haven’t measured.
Conclusion
Claude Opus 4.8’s brand recommendation logic isn’t opaque—it follows a consistent pattern of source authority, mention density, sentiment consistency, and category association. What’s changed with the Opus 4.8 release is that the model’s honesty calibration now makes it more demanding. Generic content and thin citation footprints get filtered out. Brands with documented credibility across independent sources get surfaced.
The monitoring infrastructure to track this didn’t exist a few years ago. It does now. The teams that build a baseline understanding of their Claude visibility in 2026 will have a significant head start on the ones still measuring success purely through Google Search Console in 2027.
FAQ
Q: Does Claude Opus 4.8 update its brand knowledge in real time?
A: No. Claude Opus 4.8 generates responses based on patterns from its training data, which has a fixed cutoff date. It doesn’t crawl the web or update citations in real time. This means brand visibility in Claude is a function of what was present in training data—and why monitoring your current presence across AI platforms requires dedicated tooling, not a one-time check.
Q: Can I “optimize” my brand for Claude the way I optimize for Google?
A: Not in the same way. There’s no equivalent of on-page SEO for LLMs. What you can influence is the footprint your brand has across sources the model weights as credible: authoritative publications, independent review platforms, community discussions, and technical documentation. That’s the GEO equivalent of link building—it takes time, but it compounds.
Q: How is Claude Opus 4.8 different from ChatGPT in recommending brands?
A: The core mechanism is similar—both models synthesize brand knowledge from training data—but they’re trained on different corpora and have different calibration priorities. Claude Opus 4.8’s emphasis on honesty and reduced unsupported claims means it’s generally more conservative in its brand citations than GPT-based models. A brand that appears frequently in ChatGPT responses may have lower visibility in Claude if the underlying sources differ.
Q: What’s the fastest signal I can improve to get picked by Claude?
A: Sentiment consistency tends to have the highest leverage for most brands in the short term. Auditing and aligning how your brand is described across third-party platforms—especially high-authority review and community sites—removes a key reason Claude might avoid citing you. It doesn’t require new content creation, just cleanup and coordination across existing touchpoints.

