
Your content team has been publishing consistently. Your SEO authority is solid. Then a potential buyer opens Claude, types “best tool for [your category],” and gets a confident, well-structured answer — featuring three of your competitors and zero mention of you.
That’s not a fluke. It’s a structural problem, and it predates your last content sprint by months.
Claude Opus 4.8 Isn’t Just a Better Chatbot
Most coverage of Claude Opus 4.8 focuses on benchmark scores and reasoning improvements. Those upgrades matter, but not in the way most marketers think.
What changed isn’t just capability. It’s selectivity. Opus 4.8 introduced enhanced multi-step reasoning, scoring significantly higher on GPQA Diamond and agentic benchmarks than its predecessors. That sounds like a good thing until you realize it means the model is now a stricter filter on what it considers worth including in an answer.
On “High Effort” settings — which more sophisticated users are increasingly applying — Opus 4.8 spends additional compute to synthesize a definitive, authoritative response. That environment heavily favors brands with deep, structured, verifiable documentation over those with polished marketing copy.
If your brand’s digital presence is mostly promotional, Opus 4.8 is less likely to trust it.
The Gap Between SEO Visibility and Claude Opus 4.8 Visibility
Here’s the core problem: Google and Claude don’t read the web the same way.
Google rewards pages that match keyword intent, earn backlinks, and load fast. Claude builds answers by synthesizing statistical associations from its training data and grounding those answers against live sources it considers authoritative. Your Google rank doesn’t transfer.
AI search visibility differs from traditional SEO in a specific, measurable way: what matters isn’t whether a page ranks, but whether the content on that page is the kind that AI systems cite and encode. A brand can dominate page one and remain completely invisible in Claude’s outputs.
This isn’t a gap most teams are set up to see. Their analytics track clicks, rankings, and traffic. None of those metrics capture what Claude is saying about them.
Why Claude Opus 4.8 Skips Your Brand Specifically
Three structural factors typically explain brand invisibility in AI answers.
Low citation authority on AI-trusted domains. Claude’s underlying corpus weights specific types of sources more heavily than generic web content: analyst reports, practitioner forums, G2-style review platforms, trade publications, and technical documentation. If your brand lacks a presence on these nodes, it fails an implicit authority check, regardless of your domain rating.
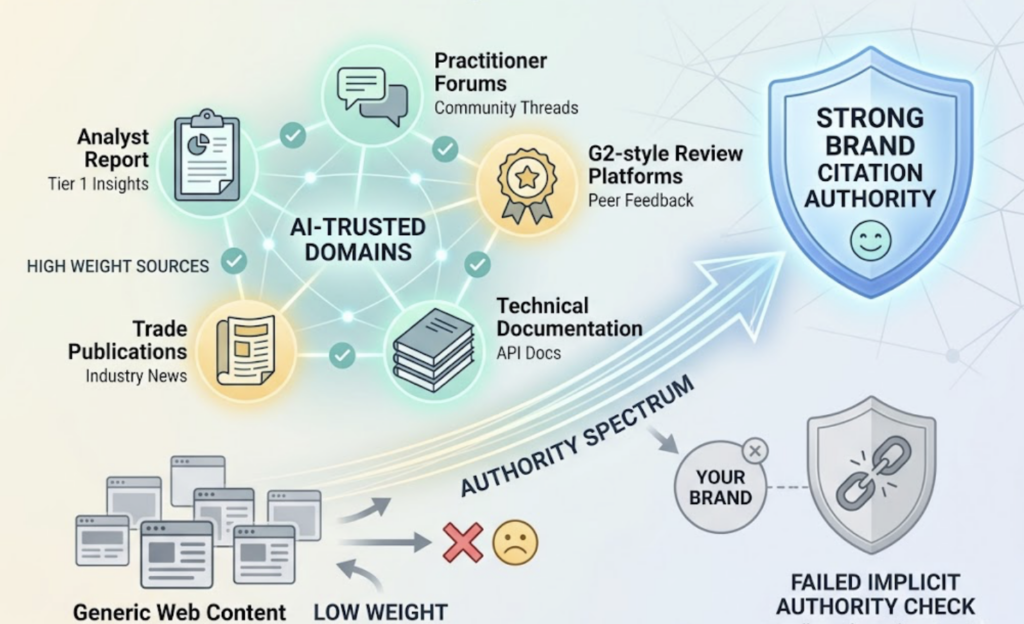
Semantic ambiguity in how your brand is defined. Claude identifies brands as entities. If your homepage describes you as a “CRM platform,” your press releases call you an “automation tool,” and your blog categories suggest you’re an “analytics solution,” the model can’t cleanly map your brand to a specific problem or outcome. Inconsistent self-description gets resolved as exclusion. The model prefers to omit rather than hallucinate.
Lack of AI-readable structure. According to research on how LLMs choose which brands to recommend, models process information best when it’s structured in extraction-friendly formats: tables, clearly bounded FAQ sections, schema-marked entity definitions. Narrative-heavy content that works well for human readers is harder for the model to parse and trust under reasoning pressure.
These three factors compound. A brand with inconsistent positioning, no third-party citations on authoritative domains, and unstructured content is effectively invisible to Claude Opus 4.8, even if it publishes excellent material daily.
What Claude Actually Uses to Build Its Answers
Understanding the mechanism matters more than chasing workarounds.
Claude Opus 4.8 draws on two knowledge sources simultaneously. The first is internalized training data: massive historical snapshots of the public web that have been compressed into statistical associations within the model’s weights. If your brand was consistently mentioned alongside a specific problem or outcome across diverse, credible sources, that association is now encoded in the model. If it wasn’t, the baseline is zero.
The second source is Retrieval-Augmented Generation (RAG): live grounding that retrieves current content at query time. When a user asks Claude about a category, the model may pull fresh content from domains it treats as high-authority. Whether your domain makes that shortlist depends on the same citation-authority logic above.
The practical implication: AI citation tracking isn’t just about knowing if your brand appears. It’s about understanding which sources Claude is citing instead of you, and why those sources rank higher in the model’s internal trust hierarchy.
That’s information most brands don’t have.
You Can’t Fix What You Can’t See
Brand managers often discover the Claude Opus 4.8 problem the wrong way: a sales rep gets asked about an AI recommendation that didn’t include them, or a prospect mentions they heard about a competitor “from AI research.” By that point, the visibility gap has been open for months.
The reason it goes undetected is simple. Standard analytics don’t capture AI answer data. Traffic reports, keyword rankings, and backlink audits measure what happened on your website. They don’t measure what Claude says when your product category comes up.
This is where Topify directly addresses the measurement gap. It tracks brand visibility across ChatGPT, Perplexity, Google AI Overviews, and other major AI platforms at the prompt level — returning seven key metrics: Visibility Score, Sentiment, Position Rank, Volume, Mentions, Intent, and CVR (Conversion Visibility Rate).
What makes this actionable is the Source Analysis layer. Topify’s platform identifies exactly which domains AI systems are citing when they answer prompts in your category. If Claude is consistently pulling from three competitor-adjacent publications and ignoring your domain, you can see that pattern in the dashboard and respond with a targeted content or PR strategy.
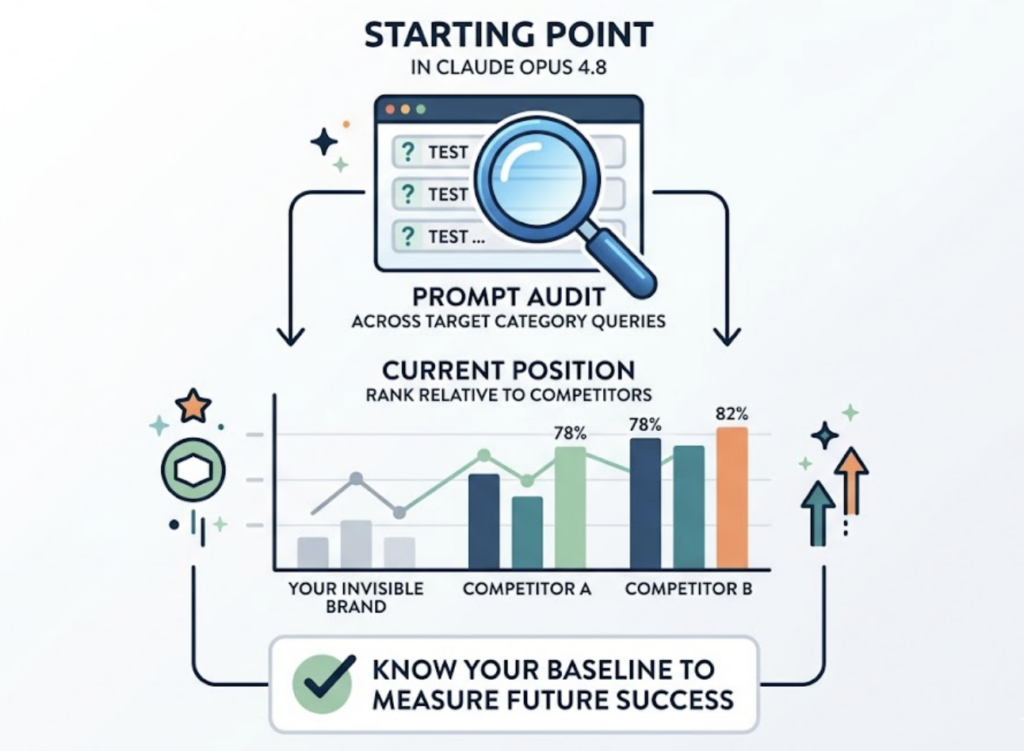
For brands currently invisible in Claude Opus 4.8, the starting point is always the same: run a prompt audit across your target category queries to establish a baseline. You need to know your current Position Rank relative to competitors before you can measure whether any change you make is working.
Three Moves That Actually Get Brands Into Claude Opus 4.8’s Answers
These aren’t shortcuts. They’re structural changes that alter how Claude encodes your brand.
Audit which prompts trigger your category. High-intent prompts in your vertical are generating answers right now, and you need to know where you stand in each of them. Tools like Topify’s prompt discovery feature surface high-volume AI prompts critical to your brand, including queries you might not be monitoring. This is the foundation for everything else.
Build content that AI platforms cite. The research on GEO tactics for Claude visibility points to a consistent pattern: original data, practitioner-authored content, and structured documentation earn third-party citations more reliably than SEO-optimized blog posts. A single original study cited by four industry publications is worth more to your AI visibility than forty keyword-targeted articles. Also consider your llms.txt file configuration, an emerging standard that helps Claude identify which sections of your site are most authoritative and AI-relevant.
Implement entity grounding across your site. Use structured data markup (Organization, Product, and Person schema) to give the model an unambiguous digital identifier for your brand. This directly addresses the semantic ambiguity problem. When Claude encounters consistent, schema-marked entity definitions, it can map your brand to a specific category with confidence, rather than excluding you to avoid a hallucination risk.
Claude Opus 4.8 Will Keep Updating. So Will the Rankings.
The competitive calculus here is different from traditional SEO because AI models aren’t static.
As Anthropic releases updates and Opus 4.8 continues to evolve, the model will re-process its internal associations and recalibrate which brands it trusts. What gets your brand into Claude’s answers this quarter is not a permanent solution. Brands that treat AI visibility as a one-time optimization project will lose ground every time the model updates.
What actually works long-term is what the research on AI visibility continuity describes: systematic presence across diverse, high-trust digital channels, maintained continuously. Not single-platform dominance. Not a quarterly content sprint. A structured process for monitoring where you stand, identifying which sources Claude is prioritizing, and updating your strategy accordingly.
The brands that will consistently appear in Claude Opus 4.8’s answers are the ones tracking it as a live channel, not treating it as a fixed result.
Conclusion
The core issue isn’t that Claude Opus 4.8 is unfair to your brand. It’s that the model is working exactly as designed — synthesizing answers from the most coherent, credible, citation-supported signals available. If your brand isn’t generating those signals, the model’s silence is accurate feedback, not an error.
The fix starts with visibility into where you actually stand. Audit your AI answer presence, identify which sources Claude is citing in your category, and build a content strategy that earns authority on those specific nodes. Get started with Topifyto run a prompt audit across your target queries and get a baseline before the next model update shifts the rankings again.
FAQ
Q: Does Claude Opus 4.8 use real-time web search to generate answers?
A: It depends on the user’s setup. Claude Opus 4.8 can operate in two modes: relying on internalized training data, or performing live RAG grounding against current web sources. Enterprise users and API deployments often enable real-time retrieval. In both cases, the authority of the sources being cited matters more than recency alone.
Q: How is AI visibility different from SEO rankings?
A: SEO rankings measure where a page appears in a results list. AI visibility measures whether a model includes your brand in a synthesized answer. A page can rank highly in Google and be completely absent from Claude’s outputs — because the two systems prioritize different signals. SEO rewards keyword relevance and backlink authority. Claude rewards citation authority on AI-trusted domain types, entity clarity, and structured content.
Q: How do I check if my brand appears in Claude Opus 4.8’s answers?
A: The manual approach is to run a series of prompts in your product category directly in Claude and record the results. The systematic approach is to use an AI visibility monitoring platform like Topify, which tracks brand mentions, Position Rank, and Source data across multiple AI platforms automatically, so you’re not relying on manual spot checks.
Q: Can I optimize for Claude specifically, or do I need a general AI strategy?
A: The underlying factors that drive visibility in Claude — citation authority, entity coherence, structured documentation — are largely the same factors that drive visibility across ChatGPT, Perplexity, and Gemini. A platform-specific tactic (like llms.txt configuration) can help with Claude directly, but most high-impact GEO work improves your standing across AI platforms simultaneously. Start with a cross-platform audit to identify where your gaps are largest before prioritizing.

