
You did everything right. Your domain authority is solid, your content ranks, and your SEO team has the keyword coverage locked down. Then someone on your executive team opens Claude Opus 4.8, types “What are the top tools for [your category]?” and your brand isn’t in the answer.
That’s not a fluke. And it can’t be fixed with another backlink.
Why Claude Opus 4.8 Brand Visibility Works Differently
Claude Opus 4.8, launched on May 28, 2026, isn’t another chatbot upgrade. It’s Anthropic’s most capable model yet, with enhanced agentic reasoning, improved citation precision, and what Anthropic describes as “effort-control” capabilities. More enterprises and professional buyers are using it daily for vendor research, category discovery, and product comparison.
The visibility problem here is structural. Claude doesn’t index websites in real time the way Google does. According to research on GEO vs. SEO dynamics, traditional search engines measure clicks and rankings, while AI models operate on something closer to “probabilistic knowledge graphs.” Your brand is “visible” only if the model has built a strong statistical association between your name and the user’s intent during training and retrieval.
That’s a fundamentally different game.
Opus 4.8’s superior reasoning capability makes this even more pronounced. It’s more selective about citations than previous models, less likely to surface brands backed by shallow or ambiguous content. If your brand presence across the web is thin, inconsistent, or hard to parse, Opus 4.8 is more likely to skip you than earlier Claude versions would have.
The Manual Check: How to Query Claude Opus 4.8 for Your Brand
The fastest starting point is direct. Open Claude Opus 4.8 and test a few prompts yourself. But the query structure matters more than most teams realize.
Generic queries like “tell me about [Brand X]” bypass the actual decision context where brand citations happen. Instead, test these three prompt categories:
Comparative queries — “Compare the top platforms for [your category]. What are the tradeoffs?”
Intent-based queries — “What’s the best tool for [specific use case] for a mid-size marketing team?”
Expert-opinion queries — “If I were advising a B2B SaaS company on [your problem space], what would you recommend?”
Run each prompt two to three times. LLM responses are non-deterministic, so a single result tells you almost nothing. What you’re looking for across multiple runs: Does your brand appear at all? Where does it appear relative to competitors? What language does Claude use to describe you?
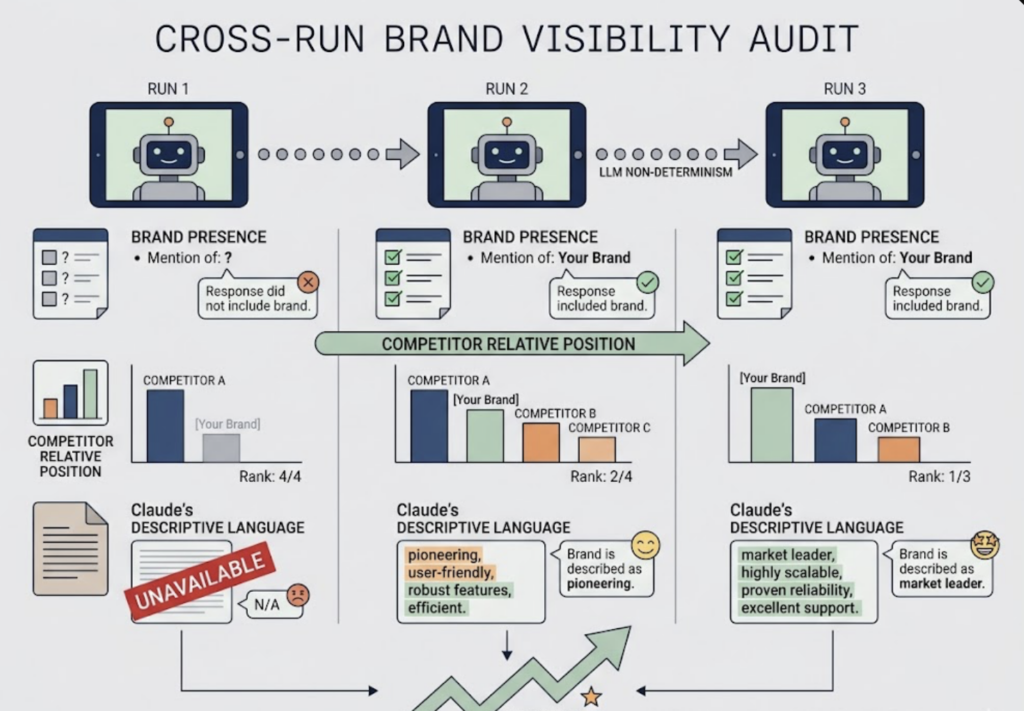
That last point matters more than the mention itself.
What Claude’s Answer Actually Tells You About Your Brand
Getting mentioned isn’t the same as getting recommended.
Claude Opus 4.8’s enhanced reasoning means it often contextualizes citations with nuance. Watch for three distinct patterns:
Top-level mentions — Your brand appears in the lead recommendations without qualifiers. This is where you want to be.
Qualified mentions — Claude includes your brand but attaches limitations: “good for smaller teams,” “better for budget-conscious buyers,” “newer to the market.” If this doesn’t match your positioning, you have a narrative problem.
Competitive context only — Your brand appears solely as a comparison point for a competitor. “Unlike Brand X, Brand Y offers…” This is the lowest-value visibility position.
Research on LLM citation decay describes how brands can drop from AI answers entirely despite stable Google rankings. One common cause is what researchers call “semantic ambiguity.” If your messaging is inconsistent across platforms, Claude may fail to map your brand to a specific category confidently, and choose a more clearly-defined competitor instead.
The sentiment and position data you gather from manual testing forms a baseline. The problem is keeping it current at any useful scale.
Why Manual Testing Breaks Down Fast
Here’s what manual testing can’t tell you.
Claude’s responses aren’t stable. The same prompt tested today versus next week may produce different results as Anthropic updates the model or adjusts retrieval mechanisms. A single round of manual testing gives you a snapshot, not a trend.
Coverage is the bigger issue. Your brand isn’t discovered through one or two query types. Real users ask questions in hundreds of different ways. “Best tool for X” generates different results than “X for enterprise” or “alternatives to [competitor].” Testing even 10 prompt variants manually takes significant time. Testing 100 is practically impossible.
And Claude Opus 4.8 is one platform. Your buyers are also using Perplexity, ChatGPT, Gemini, and increasingly AI-powered agents that pull from multiple sources. A brand that shows up well in Claude but is invisible in Perplexity has a coverage problem you’d never detect from Claude testing alone.
This is why professional GEO strategy requires a systematic prompt matrix approach, not periodic spot-checks.
How to Track Claude Opus 4.8 Brand Visibility at Scale
Systematic Claude Opus 4.8 brand monitoring starts with building a prompt matrix that mirrors how real users discover brands in your category.
Topify is built specifically for this. The platform monitors brand visibility across Claude, ChatGPT, Perplexity, Gemini, and other major AI engines simultaneously, tracking seven metrics across each: Visibility Score, Sentiment Score, Position Rank, mention frequency, source citations, intent alignment, and CVR (Conversion Visibility Rate).
The Prompt Discovery feature is particularly useful for Claude Opus 4.8 monitoring. It continuously surfaces high-volume AI prompts relevant to your category, including query variations you wouldn’t have thought to test manually. This means your monitoring coverage expands over time rather than staying locked to the 10 or 20 prompts you set up at launch.
For brand managers tracking Claude Opus 4.8 specifically, Topify’s Competitor Monitoring module shows where your brand lands relative to competitors across each query type. You’re not just seeing “did we appear,” but “did we appear before or after Brand X, and in what context.”
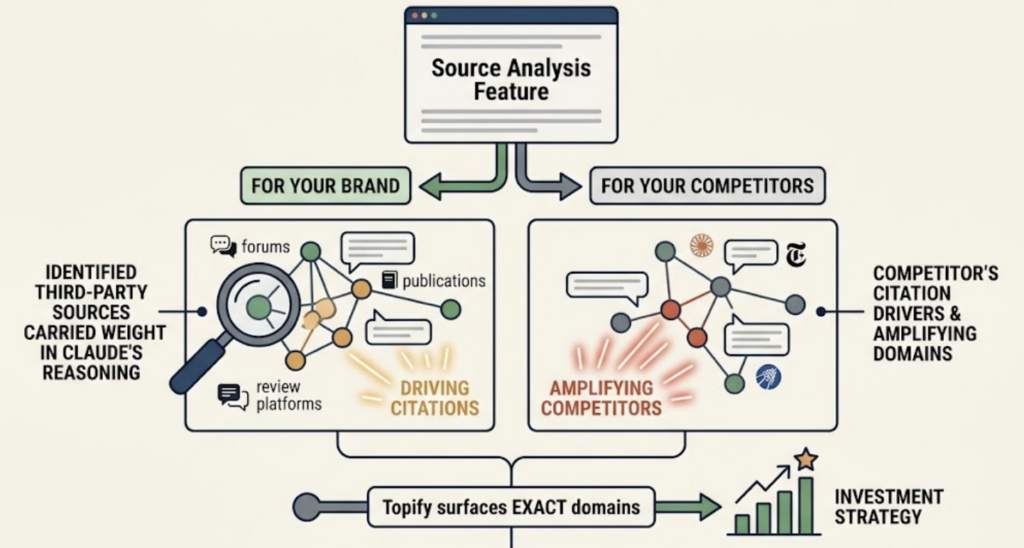
The Source Analysis feature closes the loop. When Claude cites your brand, it’s drawing on specific third-party sources — forums, publications, review platforms — that carry weight in its reasoning. Topify surfaces exactly which domains are driving those citations, and which domains are currently amplifying your competitors. That’s where your PR and content strategy investments should go next.
Interpreting Your Claude Opus 4.8 Visibility Data
Once you have consistent monitoring in place, the data starts to tell a clearer story.
A high Visibility Score — the percentage of AI responses where your brand appears — with a low Position Rank means Claude knows you exist but isn’t leading with you. That’s typically a content authority problem. The model has weak statistical association between your brand and high-confidence recommendation, often because you’re underrepresented in the third-party sources it trusts most.
A Visibility Score drop after a model update (Opus 4.7 to 4.8, for example) is a signal worth investigating immediately. As the Anthropic documentation on Opus 4.8 notes, the model has improved citation precision. Brands that were coasting on shallow presence in earlier versions often see a visibility decline when the model upgrades its standards.
Negative sentiment in Claude’s responses — even while your brand is still mentioned — is the most underreported issue. Topify’s Sentiment Score (0-100 scale) quantifies this. A brand scoring 40 on sentiment while a competitor scores 75 is losing buyer consideration in a way that traditional analytics will never surface.
Three Moves If Your Brand Isn’t Showing Up
If your Claude Opus 4.8 visibility is low, the fix isn’t more blog posts.
Build authority anchors in sources Claude trusts. According to guidance from Jasper’s GEO research, AI models prioritize information validated by reliable third-party sources. For most B2B categories, this means Reddit, G2, industry journals, and recognized analyst publications. A brand consistently cited across diverse, high-authority domains builds the “consensus presence” Claude uses to confidently recommend.
Restructure your content for AI parsing. Claude Opus 4.8 prefers what researchers describe as “extraction-friendly” content. Structured formats — organized FAQs, clear comparison tables, intent-based headings — make it easier for the model to synthesize your brand’s value proposition into a direct answer. Unstructured long-form content often gets passed over in favor of competitors who’ve made their positioning explicit and parseable.
Treat each major model release as a monitoring trigger. GEO isn’t a set-it-and-forget-it discipline. Opus 4.8’s reasoning changes how it evaluates sources relative to Opus 4.7. The brands that maintain Claude Opus 4.8 visibility are the ones continuously monitoring their position after each update, not the ones who checked six months ago and assumed nothing changed.
Conclusion
Claude Opus 4.8 is where an increasing share of professional buying decisions start. If your brand isn’t in its answers, or is appearing with the wrong context, you’re losing consideration before a competitor even gets mentioned.
Manual testing gets you a starting point. It won’t keep you there. Building a systematic approach to Claude Opus 4.8 brand visibility — tracking the right prompts, measuring sentiment and position, and connecting citations back to specific sources — is what separates teams that react to AI search from teams that shape it. Get started with Topify to set up your baseline and see where your brand stands across every major AI engine today.
FAQ
Q: Does Claude Opus 4.8 use real-time data to decide which brands to mention?
A: Not entirely. Claude Opus 4.8 combines patterns from its training data with Retrieval-Augmented Generation (RAG) in certain configurations. This means your brand’s presence in high-authority third-party sources — both historical and recent — influences whether it gets cited. Real-time indexing isn’t how the model works, which is why consistent presence across trusted domains matters more than any single piece of recent content.
Q: Can you directly optimize for Claude Opus 4.8 specifically?
A: There’s no Claude-specific SEO playbook the way there’s a Google-specific one. What you can do is optimize for the behaviors Claude’s reasoning rewards: authoritative third-party coverage, structured and parseable content, and consistent brand messaging across diverse platforms. These signals tend to improve visibility across multiple AI engines, not just Claude.
Q: How often should I check my brand’s Claude Opus 4.8 visibility?
A: Spot-checking once a month won’t catch the drift. AI model behavior shifts with updates, and prompt volumes in your category fluctuate. A systematic approach — automated monitoring across a defined prompt matrix with weekly or bi-weekly reporting — gives you the trend data needed to act before a visibility drop becomes entrenched.
Q: What’s the most common reason brands disappear from Claude’s answers?
A: Researchers call it LLM citation decay. A brand can hold steady Google rankings while gradually losing AI citations because its coverage across diverse, high-authority domains hasn’t grown. Claude Opus 4.8’s improved reasoning makes it more selective, so brands that relied on thin presence in earlier models often see sharper drops. Source Analysis tools help pinpoint exactly which citation gaps to close first.

