
Your team can describe exactly where you rank on Google. Ask where you stand when a buyer types your category into ChatGPT or Perplexity, and the answer is usually a shrug. AI assistants now summarize, compare, and recommend brands inside a single response, and most marketing teams keep no record of what those answers say. The gap matters more than it looks. Buyers are reading AI answers instead of clicking through to your site, which means a model can shape a purchase decision about your product before you ever know the conversation happened. That blind spot is what AI response monitoring software exists to close.
What Is AI Response Monitoring Software
AI response monitoring software is the system that audits how AI models describe, position, and recommend your brand inside synthesized answers. It tracks recommendation signals, not link rankings.
Traditional SEO answers one question: where do I appear on the list? AI monitoring answers a different one: how does the AI define my brand, and who does it mention next to me?
That distinction is the whole point. A keyword tool tells you that you rank third for a term. An AI response monitoring tool tells you that when a buyer asks “what’s the best platform for X,” ChatGPT names three competitors and skips you entirely. One measures position on a page nobody clicks. The other measures the answer your buyer actually reads.
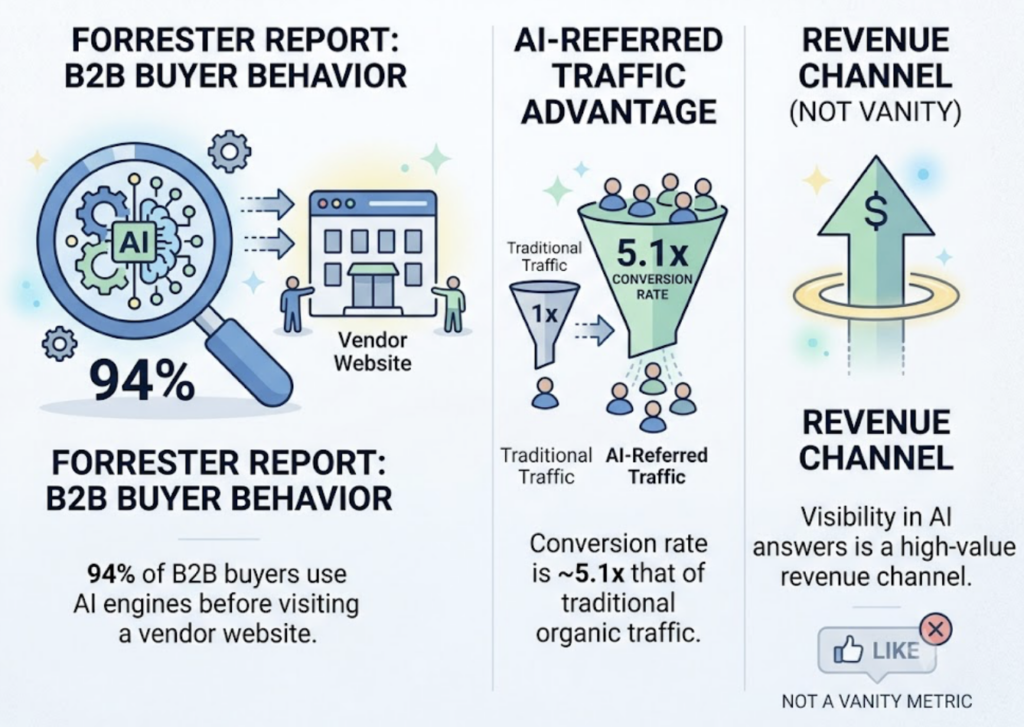
The stakes are concrete. Forrester reports that 94% of B2B buyers now use AI answer engines before visiting a vendor website, and AI-referred traffic tends to convert at roughly 5.1 times the rate of traditional organic traffic. Visibility in these answers isn’t a vanity metric. It’s a revenue channel most teams aren’t watching.
How AI Response Monitoring Software Works
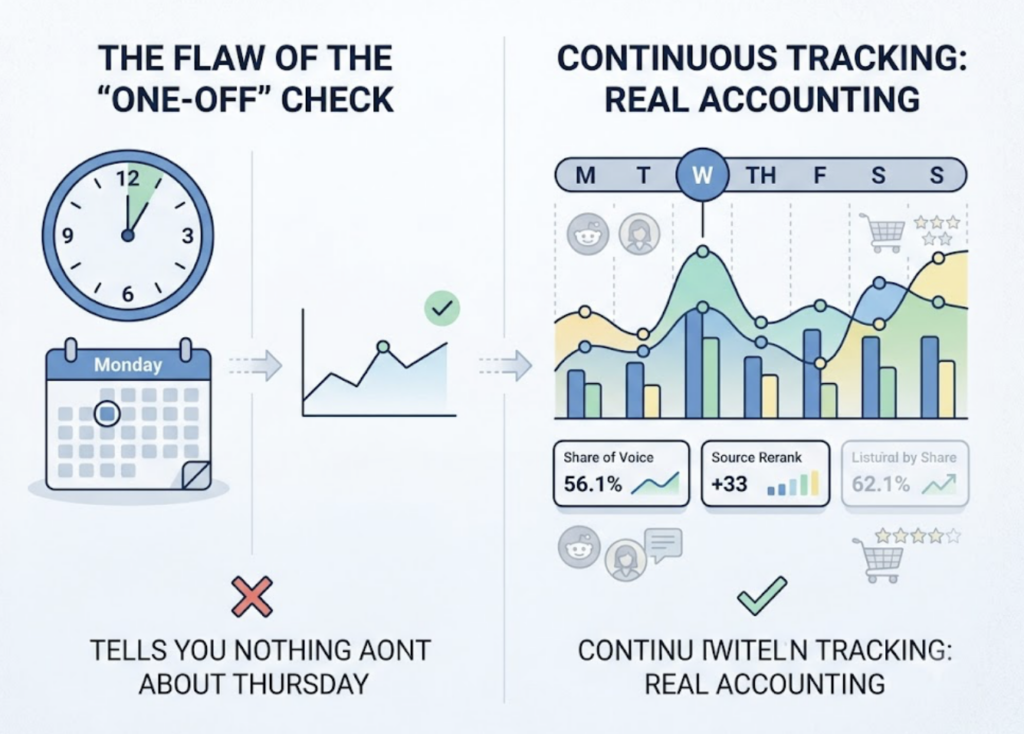
Manual spot checks don’t work here, and the reason is statistical. AI outputs churn constantly, and citation source overlap between platforms can run as low as 12%. Checking ChatGPT once on a Tuesday tells you almost nothing about what Perplexity said on Monday or what either says next week.
A real AI response monitoring system runs a repeatable pipeline instead. It usually breaks into three stages.
First, prompt definition. The software ingests a fixed set of high-intent buyer queries: problem queries, comparison queries, and category queries. This “golden set” is what gets measured over time, so results stay comparable week to week.
Second, cross-platform sampling. The system fires those prompts across multiple engines, including ChatGPT, Perplexity, Gemini, and Google AI Overviews. Each model carries its own bias. Perplexity leans on community sources like Reddit, while other engines favor institutional or editorial domains. Sampling one engine misses most of the picture.
Third, extraction. The platform parses each unstructured answer into structured data: how often you’re mentioned, how the model frames you, and which third-party domains it cited to back the recommendation. That last layer matters. Averi’s analysis of roughly 680 million citations found that the sources an AI trusts are often the real lever behind who gets recommended.
The Metrics an AI Response Monitoring Dashboard Should Show
Most teams measure presence. The useful metrics measure influence. A good AI response monitoring dashboard moves the focus from “did we appear” to “did we win the recommendation.”
| Metric | What it tells you |
|---|---|
| Mention inclusion rate | How often your brand shows up in high-intent buyer prompts |
| Share of citation | Your portion of supporting evidence versus competitors |
| Competitor displacement | How often rivals appear in the space you should own |
| Positioning sentiment | How the AI summarizes your value, like “high trust” or “slow to deploy” |
| Source authority | The credibility of the domains the AI uses to cite you |
Here’s the part teams skip. A mention isn’t automatically a win. If a model includes you but frames you as “the most expensive option,” that’s a failed mention for a mid-market product. Strong AI response monitoring analytics surface sentiment and positioning alongside raw frequency, so you can tell the difference between being recommended and being mentioned as the one to avoid.
That’s the gap most dashboards still can’t see.
What to Look for in an AI Response Monitoring Tool
The market splits into two groups, and the difference shows up the moment you try to act on the data.
| Capability | Data-only tools | Actionable platforms |
|---|---|---|
| Platform coverage | Often single engine | ChatGPT, Perplexity, AI Overviews, and more |
| Tracking precision | Basic mention counts | Prompt-level category and comparison queries |
| Competitor view | Limited or absent | Side-by-side positioning |
| Output | Raw numbers | Next-step actions to influence citations |
A data-only tool hands you a number and leaves the interpretation to you. An actionable platform tells you which source stopped citing your brand and what to publish to win it back. For a marketing team that has to report progress and then change it, that second layer is the whole job.
Use this short checklist when you evaluate any AI response monitoring solution:
- Multi-model coverage across ChatGPT, Perplexity, and Google AI Overviews
- Prompt-level precision that tracks specific category and comparison queries
- Competitor benchmarking with direct positioning comparisons
- Actionability, meaning concrete next steps like schema, FAQ, or PR moves that shift AI citations
If a tool checks the first two boxes but not the last two, you’ve bought a reporting system, not a growth one.
Common Mistakes Teams Make
Three patterns trip up most teams new to AI response monitoring.
The first is the ChatGPT-only bias. Tracking a single model feels efficient, but citation patterns differ wildly across engines. The brand winning in ChatGPT can be invisible in Perplexity. Single-platform monitoring gives you confident, incomplete answers.
The second is ignoring sentiment. Counting mentions without reading how the AI positions you produces a dashboard that looks healthy while your category framing quietly works against you.
The third is the one-off audit. AI answers drift. The correlation between traditional SEO rank and AI citation probability is near zero, around 0.034 in some studies, and 88% of Google AI Overviews citations come from outside the top 10 organic results. Last month’s snapshot is already stale. Weekly or continuous tracking is what catches citation drift before it reaches your sales pipeline.
Turning Monitoring Into a Strategy
Monitoring is the diagnosis. Strategy is the treatment. The point of all this tracking is to change what the AI says next, and that takes three coordinated moves.
Build authority first. AI models lean on trust hubs, so placements in credible publications carry more weight than another self-published post. Then fix entity resolution: make your brand consistent across the entity graph that models read, including LinkedIn, Wikipedia, and Crunchbase. Finally, structure your content for extraction. Answer-first formatting, clear headings, declarative stats, and tight lists make your pages easy for a model to lift and cite.
This is where the diagnostic and the action layer need to live in one place. Topify approaches AI response monitoring as a closed loop rather than a report. Its Comprehensive GEO Analytics view tracks brand performance across major AI platforms through seven metrics: visibility, sentiment, position, volume, mentions, intent, and conversion visibility rate. Instead of leaving you to guess at next steps, it surfaces the specific prompts you’re losing, shows which competitor is taking the slot, and maps the citation sources behind the answer.
In practice, that means you can spot a drop in ChatGPT mentions, trace it to a source that stopped citing you, and deploy a GEO strategy from the same dashboard. The platform also reverse-engineers the domains and URLs AI engines reference, so you can see whether your brand or a rival dominates the references that drive recommendations. For teams comparing options, a deeper breakdown of how AI search marketing works and how to measure it covers the measurement side in more detail.
On cost, plans start at $99 per month, which is a reasonable entry point against the revenue tied up in a higher-converting channel. You can start with Topify and see your prompt-level standing across engines before committing, with full pricing on the Topify pricing page.
Conclusion
The blind spot is real: buyers read AI answers about your category every day, and without monitoring you have no idea what those answers say. The fix isn’t complicated. Define a golden set of buyer prompts, choose a tool that covers multiple engines and explains the data instead of just displaying it, and run the monitoring continuously rather than as a one-time audit. Then close the loop by acting on what you find. Track it, understand why it’s happening, and change it. That’s the difference between watching your AI visibility and shaping it.
FAQ
Q: What is AI response monitoring software?
A: It’s software that tracks how AI models like ChatGPT, Perplexity, and Google AI Overviews describe and recommend your brand inside their answers. It measures mention frequency, sentiment, positioning, and the sources the AI cites, rather than traditional link rankings.
Q: How does AI response monitoring software work?
A: It runs a fixed set of buyer prompts across multiple AI engines on a schedule, then uses language processing to extract structured data from each answer: whether you’re mentioned, how you’re framed, and which third-party domains backed the recommendation.
Q: How do you measure AI response monitoring performance?
A: Focus on influence metrics, not just presence. Track mention inclusion rate, share of citation versus competitors, positioning sentiment, competitor displacement, and the authority of the sources citing you.
Q: How much does AI response monitoring software cost?
A: Pricing varies by coverage and prompt volume. Platforms like Topify start around $99 per month for multi-platform tracking, with higher tiers adding more prompts, projects, and seats.

