
Your team has spent quarters building domain authority, earning backlinks, and climbing Google for the keywords that matter. Then a buyer opens ChatGPT, asks for the top options in your category, and reads back five names. Yours isn’t one of them.
The uncomfortable part isn’t that the model got it wrong. It’s that nothing in your current reporting stack would have caught it. Rank trackers measure position on a page. They say nothing about whether a model decided to mention you at all. That blind spot is what an AI response monitoring platform exists to close, and the gap is wider than most teams realize.
What an AI Response Monitoring Platform Actually Tracks
An AI response monitoring platform audits how generative engines interpret, describe, and recommend your brand inside their answers. It’s a different job from search engine optimization. SEO tracks a binary signal: do you rank, and where. AI monitoring tracks recommendation signals and entity consistency, which behave nothing like a ranked list.
The shift in buyer behavior is what makes this matter. 73% of B2B buyers now use AI tools during vendor research, and that AI-sourced traffic converts at 5.1x the rate of traditional organic. The discovery phase is moving into a layer your dashboards weren’t built to see.
Here’s the distinction in plain terms.
| Dimension | Traditional SEO | AI Response Monitoring |
|---|---|---|
| Primary metric | Keyword ranking position | Citation rate, share of voice |
| Visibility type | Position in a ranked list | Inclusion in the synthesized answer |
| Stability | Deterministic, same for everyone | Probabilistic, context and model dependent |
| Core success signal | Backlinks and domain authority | Entity authority and third-party citation |
Read that last column again. None of it shows up in a rank tracker.
How AI Response Monitoring Works Behind the Answer
AI search engines generate fresh, non-deterministic responses shaped by user context, location, and the specific model. Ask the same question twice and you can get two different brand lists. That’s why a manual spot check tells you almost nothing.
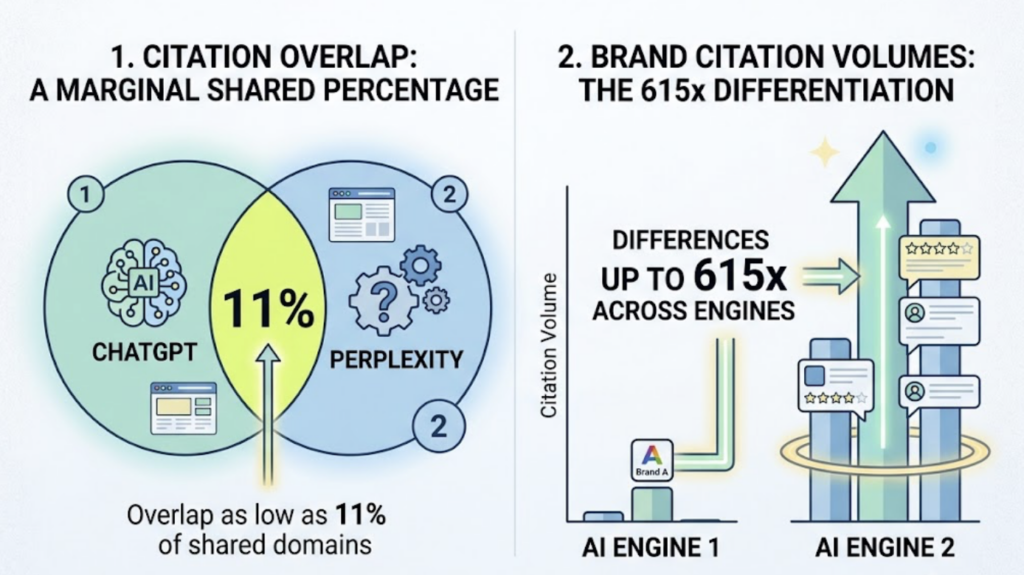
The numbers back this up. Citation overlap between platforms can be as low as 11% of domains shared between ChatGPT and Perplexity, and brand citation volumes for the same company can differ by up to 615x across engines. Checking one platform once is statistically meaningless.
A monitoring system that actually works runs a three-layer pipeline:
- Systematic prompting. Instead of single queries, it runs a fixed set of high-intent prompts, things like category comparisons and “best software for X” questions, to trigger responses at scale.
- Cross-platform synthesis. It aggregates results across ChatGPT, Gemini, Perplexity, and others to normalize for platform bias.
- Entity parsing. It uses language models to pull structured data out of unstructured answers: whether you were mentioned, how you were framed, and which competitors showed up next to you.
That third layer is where a real platform separates from a glorified search wrapper. Knowing you were mentioned is step one. Knowing you were called a “budget alternative” is the part that changes your roadmap.
The Metrics a Monitoring Dashboard Should Surface
A mention count is a vanity number. A serious AI response monitoring dashboard turns raw answers into metrics a marketing team can act on, and the analytics layer is where most of the value lives.
| Metric | What it answers |
|---|---|
| Citation rate | The share of queries where the model explicitly cites your brand |
| Share of voice | How often you appear versus competitors in the same category |
| Sentiment positioning | The language the model uses to frame your value |
| Source authority | The credibility of the third-party domains the model trusts to validate you |
| Citation volatility | Whether your presence is stable or getting pruned week to week |
Volatility deserves attention. BrightEdge tracking found that for the largest domains, roughly 5% of citation share is in play in any given week, widening to around 17% for mid-tier domains. The core holds. It’s the fringe that churns, and when changes happen they’re overwhelmingly losses. If you’re not watching that edge, you find out you’ve been dropped only after the pipeline impact shows up.
Where AI Response Monitoring Goes Wrong
Most teams that try this treat it as a one-off technical audit. That’s the root mistake. AI monitoring is an operational process, not a project you close out. Three failure patterns show up again and again.
Single-platform bias. Teams check ChatGPT, see their brand, and assume they’re covered. Given how little citation overlap exists between engines, visibility on one platform tells you very little about the others.
Ignoring sentiment. A brand described as a “deprecated option” or a “cheaper alternative” can be worse off than a brand that wasn’t mentioned at all. Counting mentions without reading framing hides the problem.
Snapshot tracking. Because engines update and prune citations often, a quarterly manual check captures drift long after it’s done damage. By the time you notice, the loss is already in your numbers.
The common thread: AI answers move faster than reporting cycles built for SEO. Monitoring has to run continuously or it isn’t monitoring.
What to Check Before You Pick a Monitoring Tool
Once you accept that this is an ongoing job, the question becomes which tool or software actually does it. Use this as a checklist when you evaluate any AI response monitoring solution.
- Platform coverage. Does it track the engines your buyers use, not just the one with the biggest logo? Multi-platform is the baseline, given how differently each engine cites.
- Metric depth. Can it report sentiment and position, or does it stop at mention counts?
- Competitor benchmarking. Does it show who the model recommends instead of you, by prompt?
- Source analysis. Can it reverse-engineer the domains the model cites, so you know where authority actually comes from?
- Action layer. Most tools stop at data. The useful question is whether the platform helps you do something with what it finds.
That last point is where many products quietly fall short. A dashboard that shows you the gap without a path to close it leaves the hard part on your desk.
How Topify Approaches AI Response Monitoring
Topify is built around that full loop, from measurement through execution. Its Comprehensive GEO Analytics layer monitors brand performance across major AI platforms through seven metrics: visibility, sentiment, position, volume, mentions, intent, and CVR. That maps closely to the dashboard standards above, rather than stopping at a single mention figure.
For teams tracking visibility across several engines, the practical value is in connecting signals. You can spot a drop in ChatGPT mentions and trace it to a specific source that stopped citing you, inside the same view. Its competitor benchmarking shows which rivals the engines recommend and how your position moves against them in real time. The citation analysis reverse-engineers the exact domains and URLs that AI platforms reference, so you can see whether you or your competitors own those references.
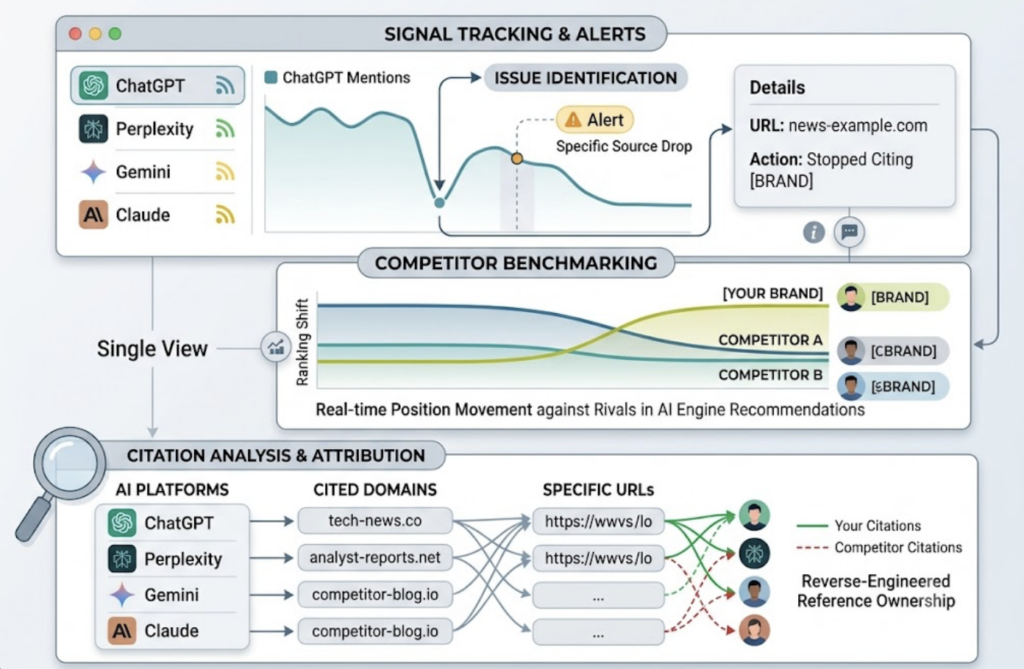
Coverage runs across ChatGPT, Gemini, Perplexity, DeepSeek, and other engines, which addresses the single-platform blind spot directly. If you want a closer look at how this fits a broader visibility program, the breakdown of AI search visibility and how to improve it is a useful next read.
Turning Monitoring Into a Repeatable Strategy
Monitoring is the diagnostic. The strategy is what you do with it. The pattern that works is a loop: monitor, find the gap, optimize, then recheck against the same prompt set.
The optimization step has a clear data anchor. AI visibility correlates far more with third-party brand mentions, a Spearman correlation of 0.664, than with backlinks, which sit near 0.218. That tells you where to spend. Earned mentions on trusted industry hubs move the number more than another link-building sprint.
Three moves tend to pay off:
- Structure content for extraction. Clear blocks, FAQs, and declarative definitions are easier for a model to parse and quote.
- Build entity authority. Get cited by high-trust platforms, since engines are tightening around fewer sources over time.
- Watch the fringe. Stable core citations matter less than the volatile edge, where a competitor is most likely to encroach on your category.
Run that loop on a schedule and AI visibility becomes a managed channel instead of a quarterly surprise. You can get started with Topify and point it at your category prompts to see where you stand today.
Conclusion
The buyer asking ChatGPT for recommendations in your category isn’t waiting for your next SEO report. They’re getting an answer right now, and that answer either includes you or it doesn’t. An AI response monitoring platform exists to make that answer visible and measurable before it costs you pipeline.
Start simple. Pick a tool that covers more than one engine, reports sentiment and position rather than raw mentions, and connects what it finds to an action you can take. Then run it continuously. The brands setting up that infrastructure now are doing it while only 22% of marketers track AI visibility at all. That window won’t stay open.
FAQ
What is AI response monitoring software?
It’s a tool that tracks how generative AI engines mention, describe, and recommend your brand inside their answers. Unlike rank trackers, it measures citation rate, sentiment, and share of voice across platforms like ChatGPT, Perplexity, and Gemini.
How much does an AI response monitoring platform cost?
Pricing varies by prompt volume, platform coverage, and seats. Entry plans tend to start around $99 per month for limited prompt tracking, with mid-tier plans near $199 per month and enterprise tiers from roughly $499 per month. Topify’s pricing follows a usage-based model, so you scale spend as value becomes clear.
What are some examples of AI response monitoring in practice?
Common uses include tracking whether your brand appears in “best tool for X” queries, catching a sentiment shift when a model starts calling you a budget option, and benchmarking which competitor an engine recommends ahead of you on a given prompt.
What should a setup checklist include?
At minimum: a defined set of high-intent prompts, multi-platform coverage, metrics beyond mention counts, competitor benchmarking, source citation analysis, and a continuous tracking cadence rather than one-off checks.

