
Your rankings are stable. Your traffic alerts are quiet. Every widget on your search monitoring dashboard is green. Then a prospect asks ChatGPT to compare the top tools in your category, gets a five-brand shortlist, and makes a decision without ever loading a SERP. Your stack recorded none of it. The problem isn’t that your tools are broken. It’s that a growing share of high-intent research now happens in a place your tools were never built to measure.
Your Search Monitoring Stack Was Built for Blue Links
Traditional search monitoring assumes a stable index: ten blue links, fixed positions, and a click as the unit of success. Rank trackers, CTR reports, and GA4 sessions all inherit that assumption.
AI engines like ChatGPT, Perplexity, and Gemini work differently. They synthesize answers, name a handful of brands, and often resolve the query with zero clicks. A question like “compare top CRM software for startups” can end entirely inside the response, which makes session data a lagging, incomplete signal of brand health.
That’s the visibility gap: tools that only track Google rankings are measuring a shrinking slice of the search pie.
Closing it doesn’t mean throwing out your SEO stack. It means adding seven metrics that describe how AI systems see, describe, and recommend your brand.
Metric 1: AI Visibility Rate
AI visibility is stochastic, not binary. Ask the same prompt five times and you’ll often get five slightly different answers, with different brands appearing in each. A single spot check tells you almost nothing.
Visibility rate fixes that by measuring frequency: the percentage of responses that mention your brand across a fixed prompt set, sampled repeatedly over time. Tracking 100 prompts across ChatGPT, Perplexity, and Google AI Overviews for 30 days gives you a trend line. Testing one prompt once gives you an anecdote.
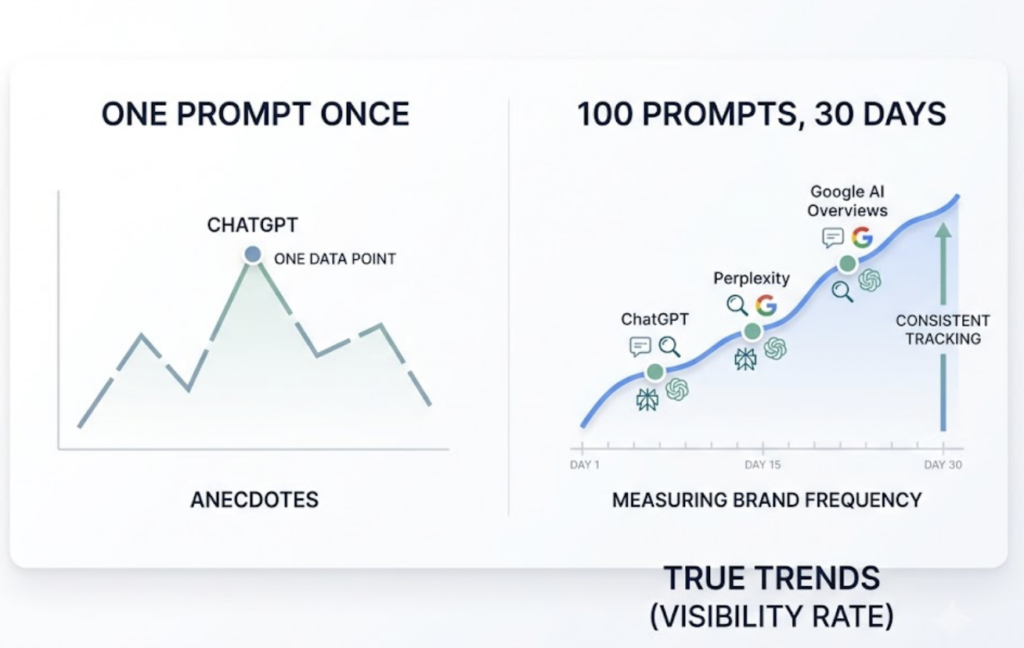
If you adopt only one metric from this list, make it this one. It’s the AI-era equivalent of a rank report, except it’s a probability, not a position.
Metric 2: Share of Voice Across AI Engines
Each AI engine runs its own recommendation logic. Perplexity tends to favor brands with strong, citable sources. ChatGPT leans more heavily on patterns in its training data. A brand can dominate one engine and barely register on another.
Share of voice measures your slice of category mentions relative to competitors, engine by engine. That breakdown matters more than any aggregate number, because it shows exactly where a rival is winning ground you can’t see from a blended average.
Single-engine monitoring hides exactly the vulnerabilities you need to find.
Metric 3: Position in AI Answers
When an AI lists “the top 3 providers,” that ordering carries at least as much cognitive weight as the top 3 spots on a Google SERP. Users anchor on the first name they read.
Unlike SERP rank, answer position is unstable and context-dependent, so it has to be tracked statistically: how often you appear first, how often you trail a competitor, and how that distribution shifts month over month. Pair it with visibility rate and you know not just whether you show up, but whether you show up where it counts.
Metric 4: AI Sentiment Score
Being mentioned often but described badly is its own kind of invisibility. An LLM that consistently frames your product as “known for high costs” or “complex to set up” is actively steering buyers away, even while your mention counts look healthy.
Sentiment tracking scores how AI describes your brand, typically on a 0 to 100 scale, and flags when the narrative drifts from your positioning. For PR and brand teams, this tends to be the first AI metric that earns a permanent slot in reporting, because misaligned AI descriptions are a messaging problem you can actually fix.
Metric 5: Citation Sources
This is the root cause metric. Every other number on this list tells you what happened. Citation analysis tells you why.
AI answers draw on a specific set of domains the engine treats as authoritative for your industry. When a competitor gets cited and you don’t, the source list shows you which review sites, comparison pages, or community threads are doing the recommending. That turns a vague visibility problem into a concrete content gap with a URL attached.
In practice, teams that skip this metric end up guessing at optimization. Teams that track it know which third-party page to win next.
Metric 6: AI Prompt Volume
Keyword volume is a metric of the past. People don’t type “CRM software” into ChatGPT. They ask long, context-heavy questions: budget constraints, team size, integrations, all in one prompt.
Prompt volume measures which of these conversational queries are actually trending in your category and at what scale. It’s how you decide which prompts deserve a place in your monitoring set and which content gaps are worth filling first. Without it, you’re optimizing for questions nobody asks.
Metric 7: Conversion Visibility Rate
Visibility without business impact is a vanity metric. Conversion visibility rate, or CVR, tracks the correlation between brand appearances in AI answers and subsequent direct or organic traffic to high-intent landing pages.
It’s the bridge between “AI mentions us more” and “AI search is driving pipeline.” When leadership asks why AI search monitoring deserves budget, this is the number that answers the question.
How to Track All Seven Without Building It Yourself
Manually sampling seven metrics across four AI platforms doesn’t scale. Each prompt needs repeated runs to be statistically meaningful, each engine answers differently, and citation patterns shift every few weeks. A 100-prompt library sampled properly across ChatGPT, Perplexity, Gemini, and DeepSeek generates thousands of answers a month, which is well past what a spreadsheet workflow can absorb.
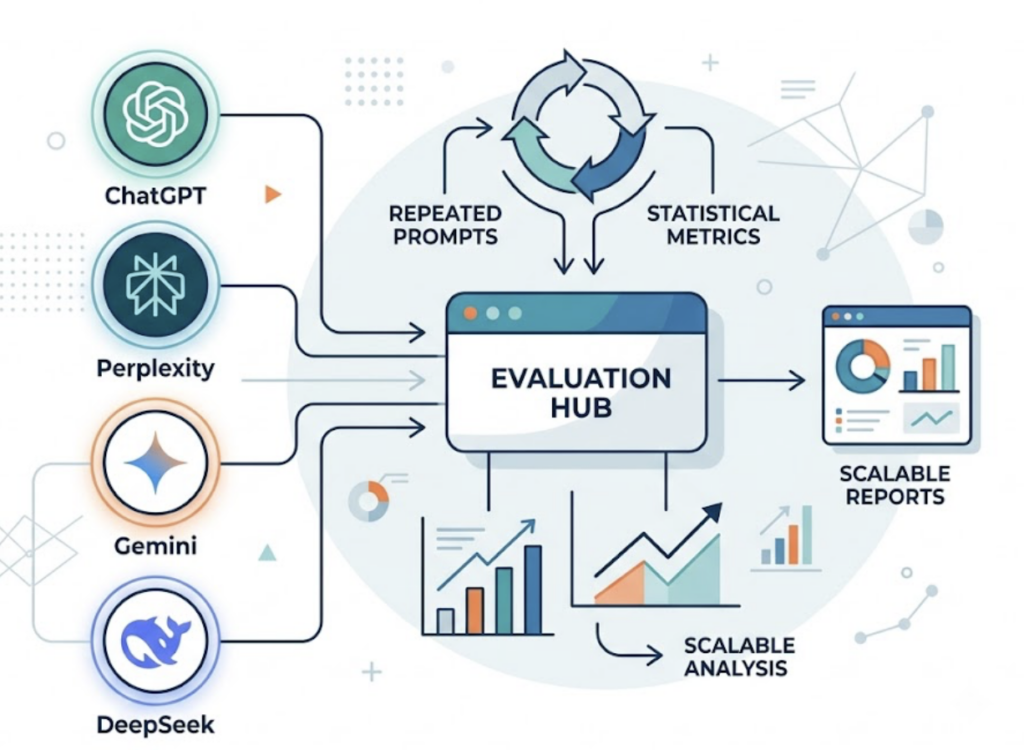
This is the problem Topify was built around. Its analytics matrix maps directly to the seven metrics in this article: visibility, share of voice, position, sentiment, volume, mentions, and CVR, all in a single AI search monitoring dashboard. The platform automates prompt sampling across the major AI engines, so visibility rate and position data come from repeated runs rather than one-off checks. Its Source Analysis feature handles Metric 5, letting you reverse-engineer which domains AI engines cite for competitors and adjust your content strategy accordingly. In practice, that means you can spot a drop in ChatGPT mentions and trace it back to a specific source that stopped citing your brand, inside the same view.
Pricing starts at $99 per month for the Basic plan, which covers 100 tracked prompts, 9,000 AI answer analyses, and tracking across ChatGPT, Perplexity, and AI Overviews, with a 30-day trial to validate the data before committing.
Bottom line: the tooling cost is low compared to the cost of staying blind in the channel where your buyers are already asking questions.
Conclusion
An all-green dashboard built on rankings and pageviews isn’t proof that your brand is healthy. It’s proof that you’re measuring the old ecosystem while decisions migrate to the new one.
Start small this week. Define a prompt library of the top 20 questions a prospect asks before buying your product. Test them manually on ChatGPT and Perplexity to establish a baseline, even if it’s rough. Then automate the sampling so visibility rate, sentiment, and citation data flow into your monthly reporting alongside your SEO numbers. The brands that close the visibility gap first get recommended first.
FAQ
Q: What is search monitoring in the AI era?
A: It’s the practice of tracking how your brand appears across both traditional search engines and AI answer engines like ChatGPT and Perplexity. Beyond rankings and traffic, it covers AI search monitoring metrics such as visibility rate, sentiment, answer position, and citation sources.
Q: How is AI search monitoring different from rank tracking?
A: Rank tracking measures a fixed position in a stable index. AI answers are generated fresh each time, so the same prompt can produce different brand mentions. That’s why AI monitoring measures frequency and distribution across repeated samples instead of a single position.
Q: How many prompts should you track to get reliable visibility data?
A: Most teams start with 20 high-intent prompts for a manual baseline, then scale to around 100 tracked prompts with automated, repeated sampling. The repetition matters more than the raw count, since one-off checks can’t capture how often you actually appear.
Q: Can Google Search Console track AI search visibility?
A: No. Search Console reports on Google Search impressions and clicks, but it can’t show whether ChatGPT or Perplexity mentions your brand, how AI describes you, or which sources AI engines cite. Those require dedicated AI visibility tracking.

