
Your domain authority is 70. You’re ranking top three for your primary category keyword. Your content team has published 200 articles in the last year. Then someone types that same keyword into ChatGPT, and the response cites three sources. None of them are yours.
That gap isn’t random. Research shows only 12% of URLs cited by AI platforms appear in Google’s top 10 for the same query. The other 88% of AI-cited content is invisible to traditional SEO monitoring. What gets you ranked on Google and what gets you cited by an LLM are now two different systems, governed by two different sets of rules.
What Happens Between a Query and an LLM Citation
When a user submits a query to ChatGPT, Perplexity, or Gemini, the model doesn’t just recall an answer from memory. It faces a binary decision: rely on its internal training data, or search the live web for current information.
Researchers call these two paths Case L (learning data only) and Case L+O (learning data plus online research). In Case L mode, the model draws from its parametric knowledge, a compressed representation of patterns absorbed during pre-training. This data is typically months or years old, stored as neural weights rather than discrete documents. The model rarely provides external citations in this mode.
Case L+O is where citations happen. When a query involves real-time events, factual verification, or high-stakes topics, the model activates its Retrieval-Augmented Generation (RAG) pipeline. It searches the web, retrieves candidate sources, and selects which ones to cite. This trigger point is the essential gateway. Without it, your content is never evaluated.
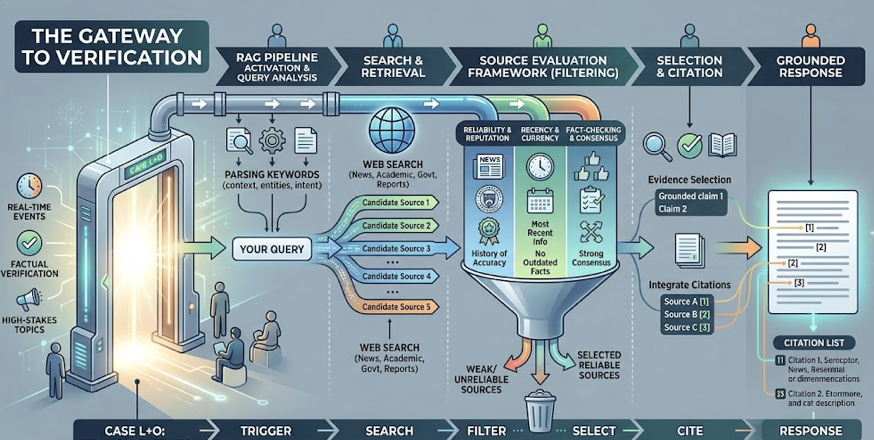
That’s the part most SEO professionals miss. The majority of AI citations come from RAG retrieval, not from the model’s “memory.” Your content doesn’t need to be in the training data. It needs to survive the retrieval pipeline.
The Four Signals LLMs Use to Select Sources
Once the RAG pipeline activates, the model evaluates candidate sources through four core signals. These aren’t the same signals that drive Google rankings.
Semantic relevance operates in vector space, not keyword space. The model converts content into numerical embeddings and measures semantic proximity to the user’s intent. Keyword stuffing, counterintuitively, hurts here. Repeating a term dilutes the “semantic signature” of a passage, pushing its vector further from the query’s meaning. Content that provides direct, unambiguous answers to specific questions scores higher.
Information gain measures the density of unique, verifiable data points. LLMs can generate generic descriptions on their own. What they can’t generate are original statistics, first-hand research findings, or specific expert insights. Passages structured into self-contained chunks of 50 to 150 words receive 2.3x more citations than long, narrative-heavy blocks. Shorter, focused sections let the model attribute a specific fact to a specific URL with higher confidence.
Entity coherence is consistency. The model cross-references your brand description against third-party platforms like Wikipedia, G2, Reddit, and LinkedIn. If your homepage says “leader in AI analytics” but Reddit describes you as a “marketing automation tool,” the model’s entity confidence drops. Brands mentioned consistently on four or more platforms are 2.8x more likely to appear in ChatGPT responses.
Freshness acts as a primary trust filter. Content updated within the last 90 days is 3x more likely to be cited than older material. Claude favors very recent content with a median citation age of 5.1 months, while ChatGPT and Gemini tolerate slightly older material at around 8 months. Replacing statistics older than 18 months is the most effective way to reset the freshness clock.
Evidence Graphs: How LLMs Resolve Conflicting Sources
When the retrieval pipeline surfaces multiple sources with conflicting claims, the model doesn’t just pick the one with the highest domain authority. It builds what researchers call an “evidence graph,” a network where nodes represent entities and facts, and edges represent corroborating relationships between documents.
The reasoning layer performs consensus validation. If three independent sources, say a news site, an industry report, and a peer-reviewed study, all state the same statistic, that data point achieves “fact status” in the graph. The model cites one or more of those sources as verification. Outlier claims that lack corroboration get omitted or flagged as unverified.
This “three-source rule” has a practical implication: brands that rely solely on self-published content to make claims will lose to competitors whose claims are echoed across independent third-party domains. Building consensus across the web matters more than publishing volume on your own site.
Once an LLM identifies reliable nodes within its evidence graph for a category, it tends to stick with them. Analysis of citation patterns reveals a 96.8% week-over-week stability rate in cited domains. Among the roughly 3% that do change, 87% are declines and only 13% are gains. Citation positions are calcifying. That creates a first-mover advantage: brands that establish themselves as citable nodes early are significantly harder to displace.
Why High-Ranking Pages Still Get Zero AI Citations
The “high-ranking, zero-citation” gap is structural, not accidental. Traditional SEO encourages long-form content that captures a variety of keywords. LLMs prefer cleanly segmented sources where facts are easy to extract. A 3,000-word guide that buries key data points inside long narrative paragraphs will get bypassed in favor of a 500-word page with clear H2 headers answering specific sub-questions directly.
The disconnect gets worse with query fan-out. When a user enters a complex prompt, the AI doesn’t run a single search. It decomposes the prompt into multiple simultaneous sub-queries. A question like “What’s the best CRM for a healthcare startup with 50 employees?” might fan out into four separate searches: HIPAA compliance features, pricing for 50 users, medical startup reviews, and Salesforce vs HubSpot comparisons.
If your content ranks #1 for the head keyword but doesn’t have specific sections addressing those sub-topics, it fails retrieval for the queries that actually build the synthesized answer. Each sub-query identifies its own set of sources, and the final citation list is a synthesis of those separate searches. You don’t need to rank for everything. You need to be extractable for something specific.
How to Track Which Sources LLMs Actually Cite
Manual citation tracking is a dead end. AI responses are probabilistic, meaning the same prompt can produce different citations in different sessions. Platform preferences vary wildly: ChatGPT overlaps with Google’s top 10 only 12% of the time, Perplexity sits around 33%, and Google AI Overviews ranges from 38% to 76%. A single spot-check tells you nothing. Only systematic monitoring across thousands of queries can establish a reliable baseline.
Topify was built to close this measurement gap. Its AI Citation Analysis identifies which specific domains and URLs AI platforms cite when they answer queries in your category. Instead of guessing which content is working, you can see the actual evidence graph the AI relies on, and spot where competitors are being cited while your brand remains absent.
The platform’s AI Visibility Checker tracks mention frequency, recommendation position, and sentiment across ChatGPT, Gemini, Perplexity, and AI Overviews. Position matters disproportionately: the first-cited brand in an AI response captures over 60% of the AI share of voice. Being mentioned fifth often leads to total exclusion from user attention.
AI Visibility Report
For teams that want a quick diagnostic before committing to ongoing monitoring, Topify’s free GEO Score Checkerevaluates your site across four dimensions: AI bot access, structured data, content signals, and overall visibility. No signup required. It’s a fast way to determine whether your technical foundation is blocking AI retrieval before investing in content optimization.
GEO Score Checker
Five Content Signals That Earn LLM Citations
Moving from “ranked” to “cited” requires optimizing for the RAG pipeline’s extraction and reasoning layers. Five signals consistently predict citation success.
Structured, modular writing. Break content into 50 to 150 word self-contained chunks. Each section should start with an H2 or H3 that asks a specific question, followed by a direct answer. This structure facilitates the passage indexing that neural retrievers depend on. Tables are particularly effective, appearing in nearly a third of all AI citations.
Statistics and original data. Embedding quantitative metrics into every article provides the information gain LLMs prioritize. Adding statistics has been shown to boost AI visibility by up to 41%. Every major claim should include a number and a date.
Entity alignment across platforms. Maintain identical positioning on Wikipedia, LinkedIn, Crunchbase, G2, and relevant subreddits. AI platforms trust third-party consensus more than self-attestation. A mention on a respected industry site carries more citation weight than ten pages of marketing copy on your own domain. Third-party sources are cited 6.5x more often than brand-owned pages.
Answer-first formatting. Place the most important facts in the first 30% of the page, where they’re most likely to be extracted. Use lists, comparison tables, and TL;DR summaries. Avoid vague language. AI models select content that gives them a clean, attributable data point, not content that makes them work to find one.
The 90-day freshness cycle. Audit and refresh competitive pages every 90 days. Update statistics, add new sections to address emerging fan-out queries, and ensure that schema markup (datePublished and dateModified) signals recency to AI crawlers. Content decay in AI citation is faster than in traditional search: 62% of citations turn over every 90 days in competitive categories.
Conclusion
LLM citation isn’t a mystery. It’s a pipeline with measurable signals at each stage: the decision to search, semantic retrieval, evidence weighting, and source attribution. The uncomfortable reality for SEO professionals is that the signals driving this pipeline, semantic relevance, information density, entity coherence, and freshness, don’t map neatly onto the metrics they’ve spent years optimizing.
The 12% overlap between AI citations and Google’s top 10 isn’t shrinking. It’s a structural feature of how generative search works. The brands that adapt, by building modular, data-rich content and tracking their citation performance across platforms, will own the discovery layer that’s replacing ten blue links. The ones that don’t will remain part of the invisible 88%.
FAQ
What is LLM citation?
An LLM citation is the attribution of a specific claim in an AI-generated response to an external source URL. Unlike traditional search results that present a list of links, AI citations ground the model’s synthesized answer in verifiable data. They’re the primary mechanism through which content gets discovered in AI search.
How does RAG affect LLM citation selection?
RAG (Retrieval-Augmented Generation) is the mechanism that triggers external search. When activated, the model retrieves content chunks from the web based on semantic proximity to the query, evaluates them for information gain and entity coherence, and selects the most attributable sources. Without the RAG trigger, no external citations occur.
Do backlinks help with LLM citations?
The correlation between backlinks and AI citations is near zero in most studies. LLMs prioritize a source’s internal factual density and the brand’s consistency across third-party platforms over the total number of incoming links. A page with 10 backlinks but strong structured data can outperform a page with 10,000 backlinks but poor extractability.
How often do LLM citation sources change?
At the domain level, citation patterns are remarkably stable: 96.8% of cited domains show zero change week-over-week. At the URL level, turnover is much faster, with 62% of citations changing every 90 days in competitive categories. This makes regular content freshness updates a practical necessity for maintaining citation position.

