
You’re building a GEO monitoring pipeline. You’ve priced out Claude’s API, and the math is starting to look uncomfortable. Sonnet’s reasoning is sharp, but at $3.00 per million input tokens, running it across thousands of daily brand mentions burns budget fast. Haiku is five times cheaper, but you’re not sure where it’ll break down.
The answer isn’t “use one or the other.” It’s knowing exactly which tasks justify the premium, and which ones don’t.
The Price Gap Is Real. The Performance Gap Depends on the Task.
Here’s the actual pricing spread you’re working with:
| Model | Input (per 1M tokens) | Output (per 1M tokens) | Cache Read |
|---|---|---|---|
| Claude 3.5 Sonnet | $3.00 | $15.00 | $0.30 |
| Claude 3.5 Haiku | $0.80 | $4.00 | $0.08 |
| Claude 3.5 Haiku (Batch API) | $0.40 | $2.00 | N/A |
The Batch API discount pushes Haiku’s blended cost to roughly $2.40 per million tokens for non-time-sensitive workloads, compared to Sonnet’s $18.00. That’s an 86% gap. For a monitoring system processing 100,000 articles per day, that difference compounds to roughly $190,000 annually.
But the price gap only matters if the performance gap is narrow enough for your use case. On most structured tasks, it is. On a small but important subset of tasks, it isn’t.
What “Brand Monitoring” Actually Asks of a Claude Model
Brand monitoring isn’t a single task. It’s a stack of operations with very different cognitive demands. Lumping them together and picking one model is where most teams overspend or under-deliver.
Mention Extraction: Low-Complexity, High-Volume
Mention extraction is pattern recognition with a schema requirement: find entity names, format as JSON, move on. There’s no ambiguity to resolve, no irony to detect. The model needs to be fast, accurate on structure, and cheap per call.
Haiku handles this at 98.2% extraction accuracy compared to Sonnet’s 99.5%. That 1.3-point gap is negligible at scale, especially when the alternative is spending 4x more per task. For real-time feeds like Reddit threads or news aggregators, Haiku’s lower latency (roughly 1.5 seconds per 100 tokens vs. Sonnet’s 2.5 seconds) is an additional advantage.
Sentiment Classification: Where Context Starts to Matter
Standard sentiment (positive/neutral/negative) is Haiku territory. But “standard” doesn’t cover much of what brand monitoring actually involves.
The hard cases are industry jargon, sarcasm, and contextual framing. A financial analyst calling a brand “a legacy choice” isn’t giving a compliment. A developer saying a product “gets the job done” might be damning with faint praise. Haiku handles mass-market consumer sentiment well. For executive interviews, analyst commentary, or technical forums where tone is layered, Sonnet’s deeper contextual reasoning starts to justify the cost.
Competitive Narrative Analysis: Sonnet’s Domain
This is where the benchmark data diverges sharply. On GPQA (graduate-level reasoning), Haiku scores 41.6% vs. Sonnet’s 65.0%. That gap isn’t about raw intelligence — it’s about multi-step inference under ambiguity.
In a GEO context, this matters when you need to know whether an AI assistant is recommending your brand enthusiastically, mentioning it with caveats, or positioning it as a “less-desirable alternative.” A phrase like “While Brand A has the established track record, Brand B is increasingly preferred by teams building for scale” requires a model to decode the “legacy” implication, identify the emerging-threat framing, and classify both simultaneously. Haiku tends to classify this as neutral. Sonnet flags the subtle negative framing.
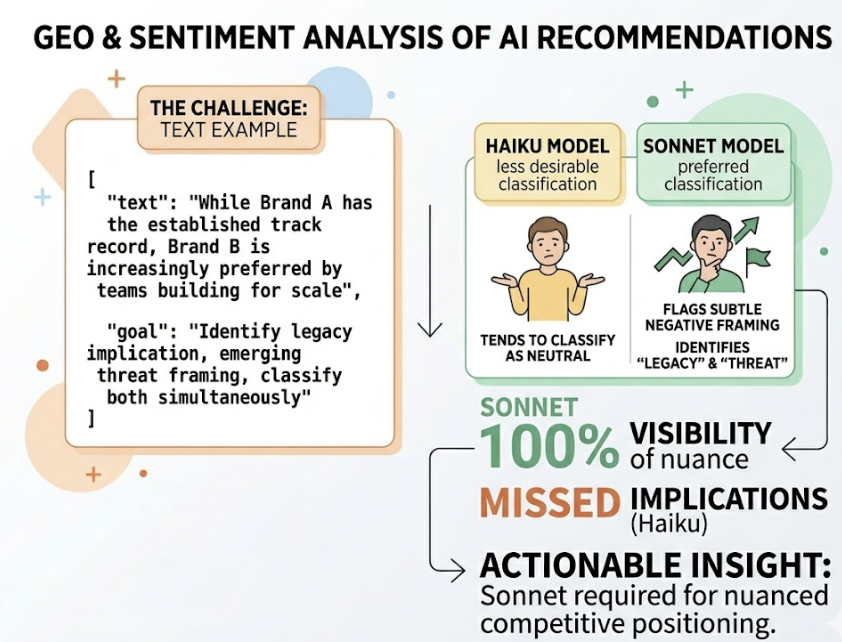
Report Synthesis: Variable by Audience
A daily digest of mentions? Haiku. A weekly brief for a CMO that synthesizes visibility shifts, identifies emerging competitor narratives, and maintains a consistent strategic voice? Sonnet. The distinction isn’t length, it’s the synthesis layer: connecting disparate signals into a coherent argument requires the writing quality Sonnet is specifically tuned for.
Where Haiku Handles the Load: The 80% Case
The majority of claude flash token usage in a brand monitoring pipeline falls into structured, mechanical operations. Haiku is not a compromise here — it’s the right call.
Consider the unit economics for a typical extraction task: 1,000 input tokens (a news article) and 200 output tokens (structured JSON with entities and sentiment score):
| Model | Input Cost (1k tasks) | Output Cost (1k tasks) | Total |
|---|---|---|---|
| Claude 3.5 Sonnet | $3.00 | $3.00 | $6.00 |
| Claude 3.5 Haiku | $0.80 | $0.80 | $1.60 |
| Claude 3.5 Haiku (Batch) | $0.40 | $0.40 | $0.80 |
Haiku via Batch API costs $0.80 per thousand tasks. Sonnet costs $6.00 for the same workload. At 100,000 tasks per day, you’re looking at $520 in daily savings by routing extraction to Haiku — capital that can fund the Sonnet calls that actually need Sonnet-level reasoning.
The tasks that belong in Haiku’s lane: raw data triage, entity extraction, standard sentiment classification, citation frequency checks, and basic mention detection. These account for roughly 80% of GEO monitoring volume in production systems.
When Sonnet’s Extra Capacity Pays Off
The phrase that captures this well: “You don’t want to miss a subtle negative framing just to save $0.003.”
Haiku’s reasoning ceiling becomes visible in three specific scenarios:
Competitive framing analysis. When an AI overview positions two brands comparatively, detecting the subtext requires multi-step inference. Sonnet can identify entity salience — the degree to which a model treats a brand as the definitive answer for a query versus a secondary mention. Haiku often misses this distinction.
Agentic troubleshooting. When a monitoring agent needs to trace a reputation shift back to a source — finding the original Reddit thread or technical blog that seeded a narrative — Sonnet’s agentic capability (64% task completion on internal evaluations vs. 38% for prior models) handles the autonomous browsing and source synthesis. Haiku hallucinates when reasoning chains exceed 150 lines of logic.
Executive synthesis. Reports that need to hold together as a strategic argument, not just a data summary, require Sonnet’s writing quality and ability to maintain consistent voice across a long context window.
A Token Routing Framework for GEO Teams
The highest-ROI architecture isn’t “use Haiku” or “use Sonnet.” It’s routing each task to the right tier automatically. Here’s how the task split should look in practice:
| Task Type | Recommended Model | Avg. Token Load | Routing Trigger |
|---|---|---|---|
| Raw data triage | Haiku (Batch API) | In: 1k, Out: 50 | Volume flag |
| Entity extraction | Haiku | In: 2k, Out: 300 | Schema task |
| Standard sentiment | Haiku | In: 1k, Out: 100 | Consumer content |
| Narrative / framing analysis | Sonnet | In: 5k, Out: 1k | Comparative content |
| Crisis detection | Sonnet | In: 10k, Out: 2k | Risk flag |
| Executive reports | Sonnet | In: 50k, Out: 5k | Synthesis output |
The router classification itself adds roughly 430ms of latency and costs approximately $0.001 per request — negligible against the savings it generates.
To put concrete numbers on the hybrid approach: a 50-prompt session averaging 2,000 input and 1,000 output tokens costs roughly $1.05 routing everything to Sonnet. Routing 30 simpler tasks to Haiku and 20 complex tasks to Sonnet brings total cost to approximately $0.58 — a 45% reduction without quality degradation on the outputs that matter.
Why Most Teams Still Overspend on Model Selection
The default pattern in most organizations is to use Sonnet for everything. It feels safer. The reasoning: if the model is more capable, the output will be better. In practice, this conflates capability with appropriateness.
For structured tasks — extraction, filtering, schema validation — Sonnet’s additional reasoning capacity is dormant. You’re paying for horsepower the task doesn’t use. The extra parameters don’t make JSON formatting more accurate. They just make it more expensive.
There’s a second hidden cost that compounds this: KV cache inefficiency in agentic workloads. Multi-agent monitoring systems often involve recursive calls that multiply token consumption through what’s called a token multiplier effect. A single brand monitoring task might consume between 200,000 and 1,000,000 tokens across its agent chain. Routing all of those calls to Sonnet depletes budget before the high-value strategic insights even get generated.
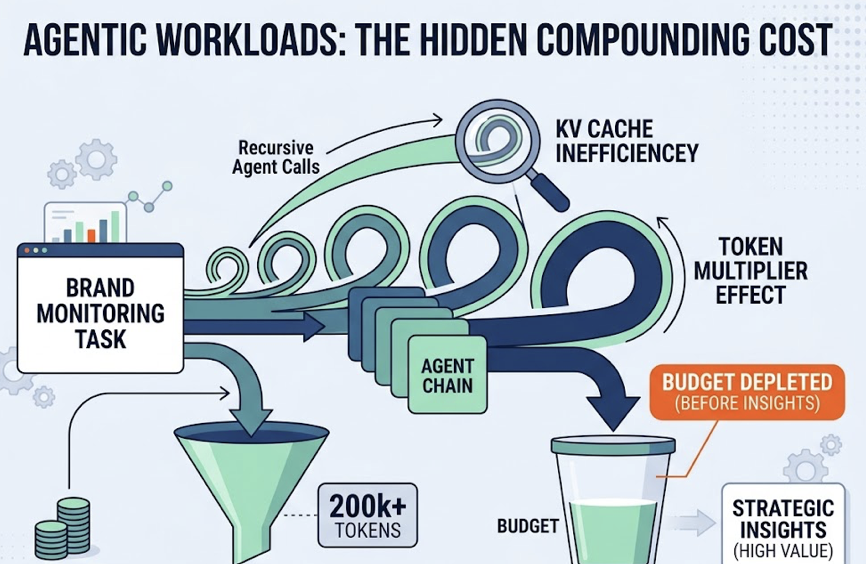
The fix isn’t switching to all-Haiku. It’s building the routing layer that makes the decision automatically, at task classification time.
Topify: For Teams That Don’t Want to Build the Router
If you’re not building your own monitoring stack, you don’t need to solve this problem manually. Topify handles the model routing internally, using efficient models for high-volume visibility checks and reserving higher-reasoning capacity for strategic analysis.
The platform tracks brand performance across ChatGPT, Gemini, Perplexity, and other major AI engines across seven metrics: visibility, sentiment, position, volume, mentions, intent, and CVR. Its Source Analysis feature identifies which domains AI platforms are citing, which surfaces the content gaps that explain why a competitor is getting recommended instead of you.
For teams managing multiple brands or clients, the One-Click Execution feature deploys GEO optimizations — content restructuring, authority signal improvements, citation targeting on high-value domains like Reddit or G2 — without requiring manual model management or infrastructure work.
The practical upside: you get the tiered routing benefit without the engineering overhead. Topify’s pricing starts at $99/month for the Basic plan, which includes 9,000 AI answer analyses across 100 prompts and 4 projects. That’s a meaningfully lower barrier than building and maintaining a custom Haiku/Sonnet router.
Conclusion
Claude flash token usage for brand monitoring isn’t a single dial. It’s a task taxonomy problem.
Haiku is the right model for roughly 80% of monitoring volume — the extraction, classification, and triage work that happens before any insight is generated. Sonnet earns its premium on the 20% that requires nuanced reasoning: competitive framing, agentic troubleshooting, and synthesis for decision-makers.
Teams that build the routing layer once — or use a platform that’s already built it — capture the cost efficiency of Haiku without accepting the quality tradeoffs on the tasks that actually drive brand decisions. The price gap is real. Whether it becomes a savings or a penalty depends on whether you’ve mapped your tasks to the right tier.
FAQ
Q: Is Claude Haiku accurate enough for sentiment analysis in brand monitoring?
A: For standard consumer sentiment (positive/neutral/negative classification), Haiku performs well and is the cost-appropriate choice. Where it falls short is nuanced analysis of layered language — sarcasm, industry-specific framing, financial disclosures, and executive communications where tone is subtle. For those cases, Sonnet’s deeper contextual reasoning reduces misclassification risk.
Q: How do I calculate token usage for a brand monitoring workflow?
A: A typical extraction task runs roughly 1,000 input tokens (a news article) and 200 output tokens (structured JSON). A narrative analysis task with competitive framing can run 5,000 input and 1,000 output tokens. Multiply each task type by its daily volume and apply the per-token pricing to get your model budget. The Batch API adds a 50% discount for non-time-sensitive workloads, which significantly changes the Haiku math at scale.
Q: What’s the cost difference between Haiku and Sonnet for 1,000 prompts?
A: For a typical extraction task (1,000 input + 200 output tokens per prompt), Sonnet costs approximately $6.00 per thousand prompts. Haiku costs $1.60, or $0.80 via the Batch API. For a narrative analysis task (5,000 input + 1,000 output tokens per prompt), Sonnet runs $30.00 per thousand prompts vs. Haiku’s $8.00.
Q: Can I mix Haiku and Sonnet in the same GEO pipeline?
A: Yes, and this is the recommended architecture. A classifier routes each incoming task to the appropriate model based on predicted complexity. The classifier call itself costs roughly $0.001 per request and adds ~430ms of latency — a negligible overhead against the 45% average cost reduction the routing generates. Most production monitoring systems benefit from this hybrid approach.

