
You’re spending more on AI than ever. But your brand is still missing from ChatGPT’s answers.
That’s not a budget problem. That’s a usage problem.
Most teams treating Claude token usage as a throughput metric — more tokens spent, more content generated, more progress made. The math looks clean until you realize none of those outputs are earning citations in AI-generated answers. You’re not buying visibility. You’re buying noise.
Here are the five token mistakes that are quietly draining your AI budget, and what to actually do about them.
Mistake #1: Prompting for Output, Not for Position
The most expensive habit in AI marketing is using Claude as a content factory.
Teams prompt Claude to “write a blog post” or “draft a product page,” consume the tokens, and call it done. But generating output is not the same as earning position. In the GEO era, what matters isn’t how much content you publish — it’s whether AI engines cite your brand when users ask relevant questions.
Research confirms the gap is real. Brands ranking in the top three organic Google results often have zero visibility in AI-generated summaries for the same queries. AI models don’t “search” — they retrieve and synthesize based on what they call Fact Units: structured, verifiable information that reduces hallucination risk.
When a Claude prompt produces purely promotional copy (“We are the best CRM for teams”), the AI treats that source as high-risk and omits it. When the same prompt produces a technical specification or a verifiable comparison stat, the model has grounding material it can cite.
Every token budget decision should start with one question: does this output earn a position, or just fill a page?
Mistake #2: Running Broad Prompts When Specific Ones Cost Less
Broad prompts are a budget multiplier — and not in a good way.
A prompt like “Analyze the CRM market for small businesses” triggers what’s known as Prompt Bloat: irrelevant context gets processed, input costs spike, and the output is too generic to drive AI citations. You’ve spent more tokens to get less value.
According to research on prompt engineering economics, specific intent-driven prompts — those that define persona, comparison target, and constraint — consume roughly 500 to 800 tokens while achieving an AI recommendation rate of 79%. Broad prompts consume 5,000-plus tokens and hit less than 15%.
The fix is Prompt Research, not keyword research. Instead of brainstorming topics, identify the specific conversational paths real users take when researching your category on ChatGPT or Perplexity.
Topify‘s High-Value Prompt Discovery is built for exactly this. It identifies Intent Clusters — the specific buying prompts where users compare vendors and seek recommendations — and estimates AI search volume across platforms. More importantly, it surfaces Invisibility Gaps: high-intent prompts where your brand ranks well on Google but is absent from the AI’s synthesized answer. That’s where your Claude token usage should be concentrated, not spread thin across generic topics.
The 80/20 rule applies here. Focus token spend on the 20% of prompts that drive 80% of AI recommendations. Everything else is overhead.
Mistake #3: Tracking Token Count Instead of Visibility Impact
This one is a governance failure, not a content failure.
Most organizations track token consumption the same way they track bandwidth: as an infrastructure cost to minimize. Cost-per-token goes down, the spreadsheet looks better, leadership signs off. But if those tokens aren’t producing AI citations, the ROI is effectively zero.
A team might consume 100 million tokens to generate 1,000 blog posts. If none of those posts earn a mention in ChatGPT or Perplexity when a user asks a relevant question, the budget was spent on a content library that the primary discovery channel of the next decade will never touch.
The KPI shift that actually matters:
| Legacy Metric | Modern GEO Metric | What It Measures |
|---|---|---|
| Token Usage | AI Visibility Score | Presence, not cost |
| Cost per 1M Tokens | Intelligence Efficiency Ratio | Value per dollar |
| Page Views / CTR | Citation Rate | Authority and trust |
| Message Volume | Conversion Visibility Rate (CVR) | AI-to-revenue pipeline |
Topify’s Visibility Tracking measures the frequency with which a brand appears in primary synthesized answers across multiple LLMs for a defined set of high-value prompts. Its CVR metric connects AI recommendations to downstream signals: branded search lift, site visits from ChatGPT-User agents, and lead flow.
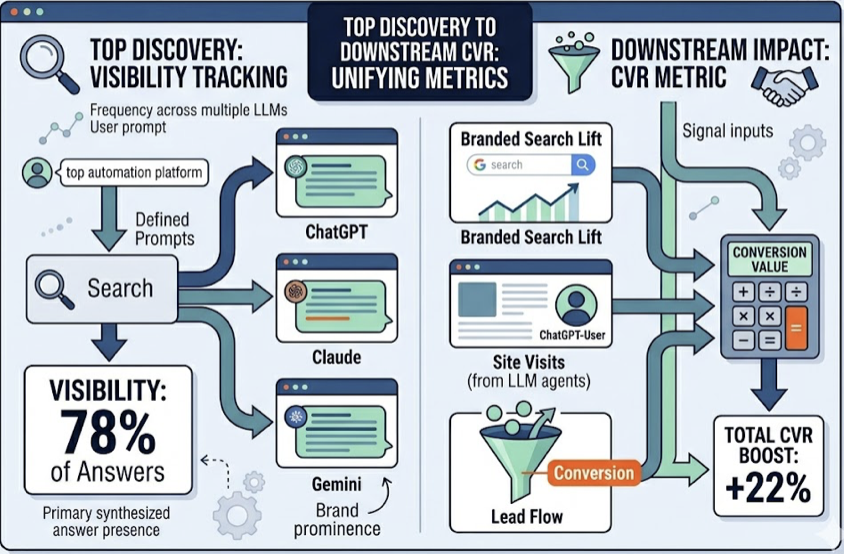
Organizations that make this shift can see 320% growth in citation rates within 90 days — not by spending more tokens, but by reallocating existing spend toward high-visibility Fact Units. That’s not a marketing claim. That’s what happens when you stop measuring consumption and start measuring position.
Mistake #4: Ignoring Which AI Platforms Actually Recommend You
Platform Monoculture is one of the most expensive blind spots in AI marketing.
Most teams optimize for one model — usually Claude or ChatGPT — and assume the visibility carries across platforms. It doesn’t. Research shows the overlap between citations in ChatGPT and Perplexity for identical queries can be as low as 11%.
Each AI engine has its own retrieval philosophy. Claude prioritizes long-form technical documents and structured content. Perplexity leans heavily on Reddit threads, niche blogs, and real-time sources, with Reddit accounting for nearly 47% of its citations. Gemini oscillates between its Knowledge Graph and traditional organic signals. DeepSeek pulls from documentation, code repositories, and academic papers.
A brand optimized only for Claude’s retrieval logic — white papers, technical FAQs, structured data — might be invisible on Perplexity because it has zero Reddit presence. A competitor with 20 community-sourced threads discussing their product will dominate there, regardless of how polished your corporate blog is.
Here’s the platform breakdown:
| Platform | Citation Rate | Source Preference |
|---|---|---|
| ChatGPT | ~60% | Bing Index, high-authority blogs |
| Perplexity | 13% | Reddit (46.7%), real-time web |
| Gemini | 6-76% | Wikipedia, YouTube, Google Graph |
| Claude | High | PDFs, technical whitepapers |
| DeepSeek | Variable | Documentation, code repos |
Without cross-platform intelligence, you can’t see that gap. Topify’s multi-model Visibility Tracking monitors brand presence simultaneously across ChatGPT, Gemini, Perplexity, and emerging players like DeepSeek and Doubao. When it reveals a competitor is dominating Perplexity via community threads while you’re only cited on ChatGPT via your corporate blog, you can reallocate budget before that visibility gap compounds.
Diversify your token strategy across platforms. One retrieval logic doesn’t fit all.
Mistake #5: No Feedback Loop from AI Citations Back to Content
This is the silent budget killer most teams never diagnose.
You use Claude tokens to produce content. You publish it. You check traffic analytics. You don’t check which of that content is actually being cited by AI engines — and which of it is being silently ignored.
Without Source Forensics, you’re optimizing blind.
Here’s the technical reality: AI retrieval systems don’t ingest entire pages. They extract Fraggles — small text fragments typically 50 to 150 words long — and evaluate them for Information Density. A 2,000-word blog post with only one extractable Fact Unit wastes the tokens spent on the other 1,850 words from a GEO perspective. You’re paying Claude to write content that AI engines mostly skip.
Topify Source Analysis reverses this. It extracts every URL cited in an AI response and classifies it as Owned, Competitor, or Third-Party Reference. When it finds that a competitor is being cited because they have a cleaner machine-readable pricing table or a more fact-dense technical FAQ, you get a direct content brief — not a vague recommendation to “improve quality.”
The execution workflow matters too. Topify’s one-click GEO execution converts that intelligence into content action: stripping superlatives and replacing them with verifiable specifications, restructuring content to increase Information Density, and syncing brand data across authoritative grounding layers like Wikipedia, LinkedIn, and G2 that AI engines use for cross-referencing.
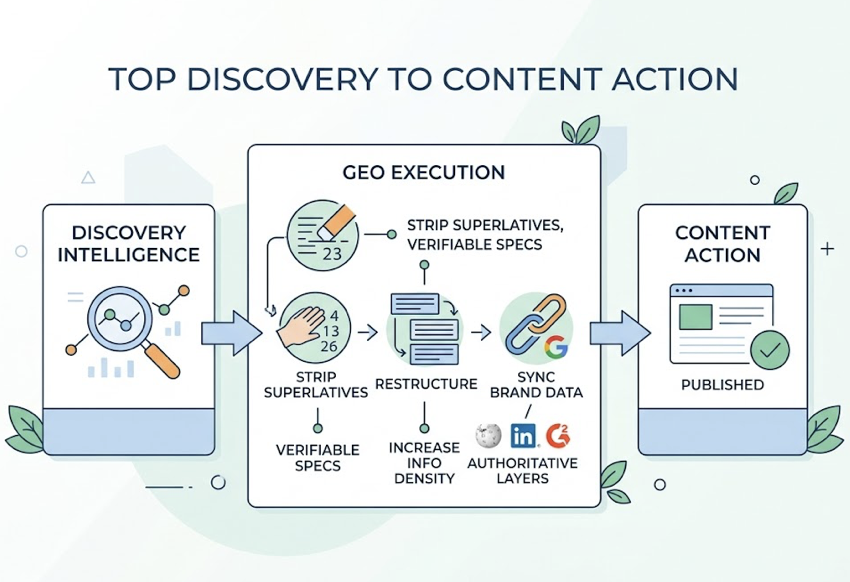
The feedback loop is what separates brands that grow AI visibility from brands that keep guessing. Without it, you’re spending tokens and hoping.
What Good Claude Token ROI Actually Looks Like
Tokens are inputs. Visibility is the output that matters.
The shift from output-centric to position-centric token strategy changes everything. It’s less about generating more content, more about ensuring each piece earns a position in the AI’s recommendation logic.
Three questions every marketing leader should ask before approving Claude token spend:
Visibility: Did this spend increase our AI Visibility Score or Share of Voice for a high-value prompt?
Authority: Did it move us from being mentioned to being cited with a verified source link?
Conversion: Did the AI recommendation result in a branded search lift or a trackable session from a ChatGPT-User agent?
The results when teams apply this framework are documented. Popl.co achieved a 1,561% ROI with an 18-day payback period after restructuring content for AI comprehension. Grüns grew Share of Voice from 2.0% to 12.6% in 60 days using a prompt-led cluster strategy.
| Metric | Unmanaged Spend | Managed GEO Spend |
|---|---|---|
| Token ROI | Less than 1:1 | 3.7:1 to 15:1 |
| Conversion Rate | 2.8% (standard organic) | 14.2% (AI-referred) |
| Visibility Gain | Stagnant / unmeasured | 320%-1,000% citation growth |
| Content Strategy | High volume / low signal | Low volume / high signal density |
The difference isn’t budget. It’s how the budget is directed.
Topify turns Claude token usage into a structured, measurable growth channel — tracking visibility across seven key metrics: visibility, sentiment, position, volume, mentions, intent, and CVR — so every dollar spent has a clear line to brand authority.
Conclusion
The enterprise AI budget isn’t being killed by the price of tokens. It’s being killed by how they’re used.
Tokens are the fundamental currency of AI work. Their value is realized only when they secure a brand’s position in the synthesized answers of generative engines. Prompting for output in a world that rewards position is a recipe for strategic invisibility.
Avoid these five mistakes — output-centrism, broad prompting, KPI misalignment, platform siloing, and missing feedback loops — and your token budget becomes a competitive asset. Keep making them, and a competitor with a smarter allocation strategy will own the AI answer instead of you.
Stop measuring what you spend on Claude. Start measuring what you own in the AI’s knowledge graph.
Start tracking your AI visibility with Topify before a competitor already has.
FAQ
How many tokens does it take to rank in AI answers?
Ranking in an AI answer isn’t a function of token volume. It’s about Information Density and Semantic Proximity. A 500-token prompt that injects high-quality Fact Units into the AI’s grounding layer is more effective than 10,000 tokens of generic copy. Brands appearing across four or more authoritative platforms — Reddit, G2, news sites, and niche blogs — are 2.8x more likely to be cited.
Is Claude better than other models for AI visibility content?
Claude (the 3.5 and 4.6 series) is well-suited for generating deeply structured content that provides the Technical Justification AI engines look for when citing sources. That said, for broad consumer discovery, ChatGPT’s market share makes it the primary visibility target. Perplexity is most accessible for niche sites due to its consistent citation behavior — and its reliance on Reddit means community presence matters as much as content quality.
What’s the difference between token optimization and GEO optimization?
Token optimization is a financial and technical discipline: reducing cost-per-request through model selection (Claude Haiku instead of Opus, for example) and context management. GEO optimization is a strategic marketing discipline: increasing how frequently and prominently your brand appears in AI-generated answers. Token optimization manages the spend. GEO optimization manages the impact. You need both — but most teams only do the first.
Can I track AI visibility across platforms like DeepSeek or Doubao?
Yes. Topify’s surveillance covers global and open-source models including DeepSeek and Doubao, in addition to the major Western platforms. As the AI ecosystem moves toward Machine-to-Machine communication — where autonomous agents query multiple models to complete tasks — multi-model visibility tracking becomes a baseline requirement, not a premium add-on.

