
Both launched within a week of each other. Both offer a 1,000,000-token context window. Both charge $5.00 per million input tokens. On paper, the spec sheet makes the choice look like a coin flip.
It isn’t.
Beneath the pricing parity, a measurable performance gap has emerged across benchmarks, real-world coding tasks, and total cost of ownership. The difference between choosing the right model and the wrong one isn’t bragging rights — for teams running high-volume agentic workflows, it can translate to a cost variance of over 300% in production.
Here’s what the data actually shows.
The Claude 4.7 vs GPT-5.5 Spec Sheet: What Parity Looks Like (and Where It Ends)
Claude Opus 4.7 launched on April 16, 2026. GPT-5.5 followed seven days later on April 23. Both arrived with identical context windows and the same entry-level API rate.
| Specification | Claude Opus 4.7 | GPT-5.5 |
|---|---|---|
| Release Date | April 16, 2026 | April 23, 2026 |
| Context Window | 1,000,000 tokens | 1,000,000 tokens |
| Max Output | 128,000 tokens | 128,000 tokens |
| Input Modalities | Text, Image, PDF, Code | Text, Image, Audio, Code |
| Core Architecture | Adaptive Thinking | Agentic Reasoning (“Spud”) |
The surface-level similarity is intentional. Both Anthropic and OpenAI have converged on the same frontier spec as a baseline. The actual differentiation lives in architecture, and that difference shows up fast when you push either model into production.
Benchmark Scores: Where Claude 4.7 Leads and Where GPT-5.5 Pulls Ahead
The 2026 benchmark landscape reveals a pattern of “specialized dominance” rather than one clear winner across all tasks. Claude Opus 4.7 holds a consistent edge in hard scientific reasoning and precision engineering. GPT-5.5 dominates in autonomous tool use and terminal-based orchestration.
| Benchmark | Claude Opus 4.7 | GPT-5.5 | Winner |
|---|---|---|---|
| GPQA Diamond | 94.2% | 93.6% | Claude (+0.6%) |
| HLE (no tools) | 46.9% | 41.4% | Claude (+5.5%) |
| HLE (with tools) | 54.7% | 52.2% | Claude (+2.5%) |
| SWE-Bench Pro | 64.3% | 58.6% | Claude (+5.7%) |
| FinanceAgent v1.1 | 64.4% | 60.0% | Claude (+4.4%) |
| Terminal-Bench 2.0 | 69.4% | 82.7% | GPT (+13.3%) |
| τ²-Bench (Telecom) | 88.6% | 98.0% | GPT (+9.4%) |
| ARC-AGI-2 | 68.3% | 83.3% | GPT (+15.0%) |
| OSWorld-Verified | 78.0% | 78.7% | GPT (+0.7%) |
| MMMU (Vision) | 91.5% | ~92.4% | GPT (slight) |
The margin that matters most for engineering teams: SWE-Bench Pro at 64.3% for Claude vs. 58.6% for GPT-5.5 is a 5.7-point gap in real-world codebase navigation. For autonomous tool orchestration, GPT-5.5’s Terminal-Bench 2.0 score of 82.7% versus Claude’s 69.4% is a 13-point lead that compounds across every automated pipeline run.
Neither model is universally superior. The question is which benchmark reflects your actual workflow.
Claude 4.7’s “Adaptive Thinking” vs GPT-5.5’s “Spud” Architecture
Claude Opus 4.7 introduces Adaptive Thinking, a mechanism that dynamically allocates internal reasoning tokens based on prompt complexity. In practice, it pauses on ambiguous architectural decisions rather than charging forward with a potentially destructive assumption.
GPT-5.5’s “Spud” architecture is optimized for momentum. It’s designed to keep tasks moving as an autonomous agent, which makes it faster at execution but more likely to miss edge cases that require deliberate internal verification.
On ARC-AGI-2 — a test of novel out-of-distribution reasoning — GPT-5.5 scores 83.3% vs Claude’s 68.3%. That’s a meaningful lead in “cold start” logic. For multi-step architectural refactoring that requires domain knowledge already in context, Claude’s thoroughness pays off.
The Real Pricing Comparison: Why $5/MTok Tells Half the Story
Both models list at $5.00 per million input tokens. That number is accurate and also almost irrelevant for high-volume users.
| Pricing Dimension | Claude Opus 4.7 | GPT-5.5 | Impact |
|---|---|---|---|
| Input (per 1M tokens) | $5.00 | $5.00 | Parity on short context |
| Output (per 1M tokens) | $25.00 | $30.00 | GPT is 20% higher per output token |
| Long Prompt Surcharge | 2x above 200K tokens | None | Claude: $10/MTok input, $37.50/MTok output |
| Prompt Caching | 90% savings | Available (variable) | Critical for RAG/coding agents |
| Batch Discount | 50% | 50% | Standard for async workflows |
| Tokenizer Efficiency | 1.0x–1.35x baseline | ~0.6x (optimized) | GPT is ~2x more efficient per string |
Claude 4.7’s new tokenizer improves accuracy but reduces token density. For the same Python code or English text, Claude can consume between 1.0x and 1.35x more tokens than its previous generation. GPT-5.5 runs in the opposite direction: it produces 72% fewer output tokens than Claude 4.7 for identical tasks.
That efficiency gap compounds fast. A software engineering agent running 500 tasks per day hits an estimated monthly cost of ~$4,050 on Claude Opus 4.7 without caching. The same workload on GPT-5.5, factoring in token efficiency and the absence of long-prompt surcharges, comes in significantly lower.
One important offset: Claude’s 90% prompt caching discount is aggressive. For RAG workflows or agentic loops with high context reuse, that discount can partially close the efficiency gap.
Speed and Reliability: The Latency Gap That Shapes User Experience
Time-to-first-token (TTFT) has split into two separate metrics in 2026: one for interactive experiences, one for background automation. Claude and GPT-5.5 are optimized for opposite ends of that spectrum.
Claude Opus 4.7 streams its first token in approximately 0.5 seconds. For live customer support, real-time coding assistance, or chat interfaces, that speed creates a near-instant response feel. GPT-5.5’s TTFT baseline sits around 3.0 seconds — acceptable for background agents, but noticeably sluggish for interactive use cases.
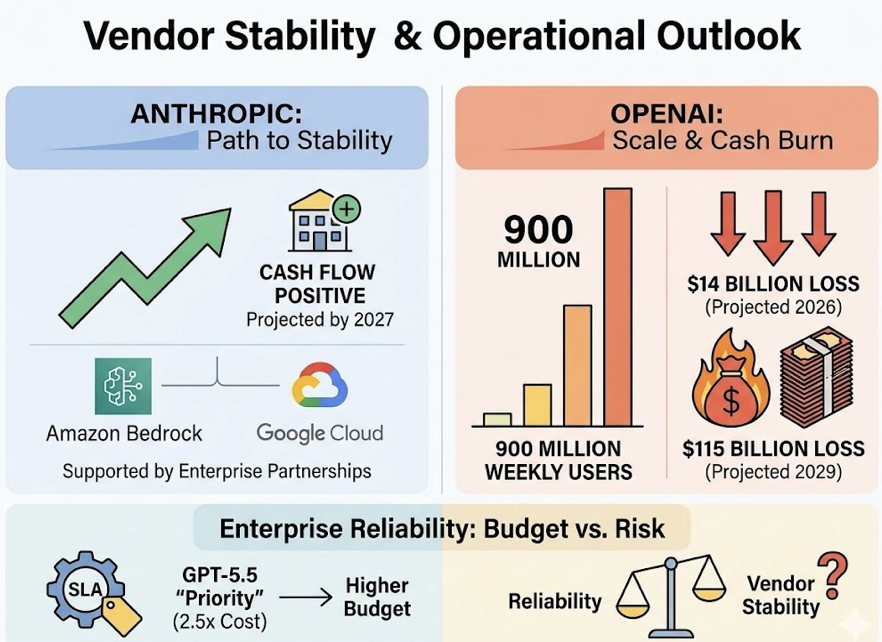
For enterprises concerned about vendor stability: Anthropic is projected to reach positive cash flow by 2027, backed by enterprise partnerships via Amazon Bedrock and Google Cloud. OpenAI serves 900 million weekly active users but is projected to burn $14 billion in 2026, with cumulative losses potentially reaching $115 billion by 2029. GPT-5.5’s “Priority” tier (at 2.5x standard cost) provides SLA-backed reliability for mission-critical workloads — but that’s an additional budget line worth factoring into enterprise procurement decisions.
Where Claude 4.7 Wins: The Case for Precision Over Speed
Claude Opus 4.7 is the better tool when the cost of a mistake is high.
Its 64.3% score on SWE-Bench Pro makes it the most reliable option for multi-file architectural changes where a single regression bug can block a release. It maintains stronger coherence for projects exceeding 10,000 lines of code, with higher retrieval accuracy for context buried in the middle of long files.
For legal and financial analysis, Claude’s self-verification mechanism — double-checking citations and logic before finalizing a response — measurably reduces hallucination rates compared to the more execution-forward GPT-5.5.
For content and marketing teams, Claude 4.7 holds an edge in long-form writing. It maintains structural integrity for documents exceeding 1,500 words and adheres more reliably to “negative constraints” — if you tell it not to use certain terms or writing styles, it sticks to those instructions with greater fidelity than GPT-5.5.
Its 3.75-megapixel vision input also makes it the stronger choice for extracting data from dense financial charts, medical diagrams, or complex architectural blueprints.
Where GPT-5.5 Wins: The Case for Velocity and Scale
GPT-5.5 is the better tool when throughput matters more than thoroughness.
Its 82.7% on Terminal-Bench 2.0 is the benchmark that defines agentic workflow performance in 2026. For data pipelines, server maintenance, and multi-step web research with browsing tools, GPT-5.5 is the safer operator. Its native integration with Google Sheets and Excel allows it to function as a junior analyst — building workbooks, linking formulas, and generating dashboards without human intervention.
The token efficiency advantage is compounding at scale. For teams running millions of tokens per day in background loops, Claude’s long-prompt surcharge and higher tokenizer density make GPT-5.5 the only economically viable option for large production pipelines. Paying 20% more per output token is manageable at low volume; it becomes a budget problem at enterprise scale.
For audio input workflows, GPT-5.5’s native audio modality support is also a structural advantage Claude 4.7 doesn’t yet match.
Which Model to Use: A Decision Guide by Team Type
The right choice depends on what you’re optimizing for: precision or throughput, interactive latency or batch efficiency, vendor stability or ecosystem depth.
For developers and technical teams: Default to GPT-5.5. Its speed, token efficiency, and tool orchestration performance make it the better general-purpose operator for coding agents and CI/CD pipelines. Switch to Claude 4.7 for architectural refactors, security audits, or any multi-file reasoning where a single mistake has downstream costs.
For marketing and content teams: Default to Claude 4.7. Its long-form writing quality, negative constraint adherence, and deep document analysis are currently ahead of GPT-5.5 for whitepaper-grade content. Use GPT-5.5 for high-volume data analysis, competitor research synthesis, or spreadsheet automation.
For enterprise IT procurement: Claude 4.7 carries lower long-term vendor risk, given Anthropic’s financial trajectory and Constitutional AI safety framework. If your organization is already deep in the OpenAI ecosystem and needs high-throughput consumer-facing access, GPT-5.5 Priority remains viable — but budget the 2.5x premium.
The optimal strategy for 2026 isn’t picking one. Leading engineering teams are implementing model routing layers: GPT-5.5 for execution and information gathering, Claude 4.7 for review and high-stakes logic verification. The two models are increasingly used as complements, not competitors.
Your Brand’s Visibility Across Both Models: The Metric You’re Not Tracking
Choosing between Claude 4.7 and GPT-5.5 is a model selection decision. But there’s a separate question most teams aren’t asking yet: which model is recommending your brand, and how?
AI engines like ChatGPT and Claude are now responsible for over 50% of B2B software research in 2026. A brand may be the default recommendation in GPT-5.5 because it has strong structured directory presence, while being ignored by Claude 4.7 because it lacks narrative clarity in long-form sources. That visibility gap is invisible to traditional SEO dashboards.
Topify tracks brand mention frequency, recommendation position, and sentiment scores across both Claude and ChatGPT in real time. Its Visibility Tracking and Competitor Monitoring features let marketing teams identify exactly which trigger prompts lead to a recommendation and which content gaps are causing Claude or GPT to surface a competitor instead.
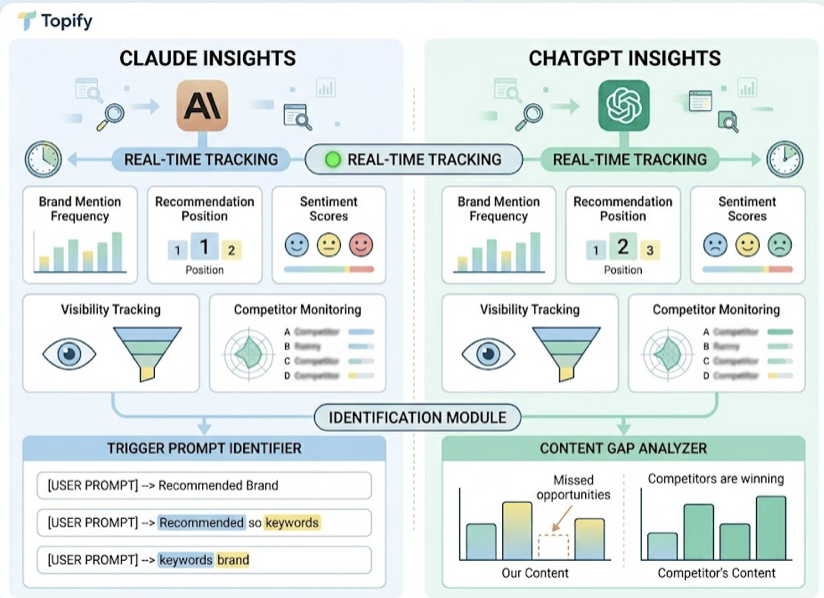
As both models continue to iterate, their recommendation maps shift. Monitoring both separately gives teams the data to close the visibility gap before it becomes a revenue gap.
Conclusion
The 2026 model decision isn’t about which system has the better MMLU score. It’s about matching architecture to workload. GPT-5.5’s token efficiency, tool orchestration, and execution speed make it the engine for automated, high-volume pipelines. Claude 4.7’s reasoning depth, self-verification, and long-form precision make it the right tool for work where a single error carries real cost.
For most teams, the answer is both: GPT-5.5 as the operator, Claude 4.7 as the reviewer. The next layer of competitive advantage isn’t choosing between them — it’s tracking how each model presents your brand to the millions of users who now start their research in AI search rather than Google.
FAQ
Q: Is Claude 4.7 better than GPT-5.5 for coding?
A: It depends on the task type. Claude 4.7 leads in code review, architectural refactoring, and catching subtle edge cases (SWE-Bench Pro: 64.3% vs 58.6%). GPT-5.5 is the stronger operator for high-velocity feature builds, tool orchestration, and automated pipelines (Terminal-Bench 2.0: 82.7% vs 69.4%). For most engineering teams, the optimal approach is using both in sequence.
Q: Which model has lower API costs in 2026?
A: Both start at $5/MTok input, but GPT-5.5 is significantly cheaper for long-context and high-volume workloads. It produces 72% fewer output tokens for identical tasks and carries no surcharge for prompts over 200K tokens. Claude 4.7 applies a 2x premium on long prompts ($10/MTok input, $37.50/MTok output), which becomes a major budget factor in large codebases or document-heavy workflows.
Q: Can I use both Claude 4.7 and GPT-5.5 in the same workflow?
A: Yes, and it’s increasingly standard practice. The 2026 best-practice pattern is model routing: GPT-5.5 handles information gathering, drafting, and execution; Claude 4.7 handles final logic verification, architectural review, and polishing. The two models’ complementary strengths make them more effective in combination than either is alone.
Q: How do I know which AI model recommends my brand more often?
A: Platforms like Topify track brand mention frequency and recommendation position across both Claude and ChatGPT separately, providing real-time visibility scores and sentiment analysis. This data is not available through traditional SEO tools, which don’t measure how generative models present your brand in their answers.

