
On March 31, 2026, a packaging error in Anthropic’s npm release pushed 512,000 lines of TypeScript source code into the public domain. A single 59.8MB source map file, left in the production build by a Bun bundler bug, reconstructed nearly 1,900 internal files within hours.
The first wave of headlines treated it like a breach. It wasn’t.
Here’s what the Claude Code leak actually was: an accidental stress test of the argument that AI transparency is worth more than AI secrecy. And the results aren’t what most people expected.
The System Prompt Architecture Wasn’t What Anyone Expected to Find
Most people assumed “leaked AI code” would mean exploitable vulnerabilities or stolen model weights. What developers actually found was a detailed blueprint of how Anthropic builds the reasoning layer that sits around the model.
Claude Code is not a chat wrapper. It’s a full agentic harness that decouples reasoning from input/output through an asynchronous buffer called H2A, manages context through a three-layer memory system anchored by a lightweight MEMORY.md index, and integrates over 40 built-in tools with structured XML-style prompt segmentation.
That’s a system architecture paper, not a security incident.
The model itself is instructed to prioritize “technical accuracy over validating user beliefs” and to “keep solutions simple” without adding unsolicited features. Those aren’t vulnerabilities. They’re design decisions that the broader AI community has been debating in theory for years, now visible in production.
Secrecy Was Already a Fragile Strategy
The most revealing part of the disclosure wasn’t the code quality or the feature flags. It was a directive called “Undercover Mode,” which instructed the model to strip internal codenames and hide AI attribution from public commits.
That’s a bet on secrecy as a security mechanism.
It failed in one afternoon.
The EU AI Act, which reaches full enforcement on August 2, 2026, has Article 50 mandating that AI outputs be machine-readable and detectable as AI-generated. California’s SB 942 mirrors this at the state level. Undercover Mode doesn’t just look ethically questionable in that context. It looks like a compliance liability that was one packaging error away from becoming a public record.
The lesson isn’t that Anthropic made a mistake. It’s that any architecture built around “they’ll never see this” has already lost the argument.
What the Leaked Prompt Structure Tells You About How AI Makes Decisions
This is where it gets practically useful.
Anthropic’s prompt architecture uses XML-style semantic separators, tags like <instructions>, <context>, and <task>, to create clear boundaries within the context window. The reasoning for this isn’t stylistic. It’s functional: structured segmentation reduces injection risk, isolates task constraints, and takes advantage of how transformer attention prioritizes earlier tokens.
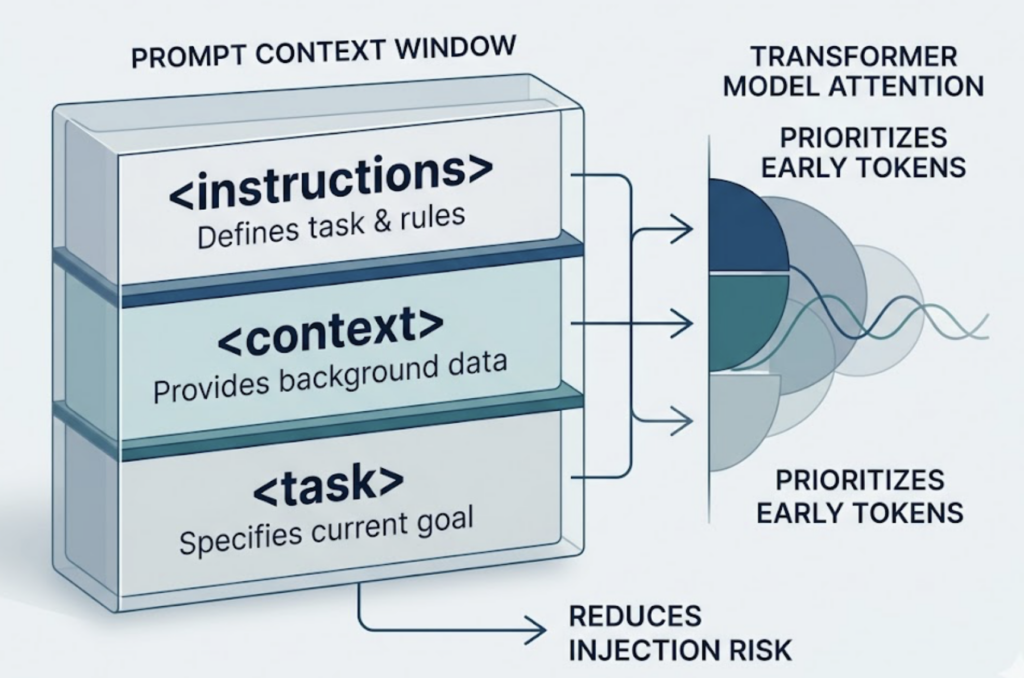
The model explicitly favors content with “concrete implementation steps” and “technical accuracy.” It’s calibrated to treat authoritative, structured information as higher-signal than vague or qualitative claims.
That calibration isn’t unique to Claude Code. Research from Princeton, Georgia Tech, and IIT Delhi found that adding specific statistics boosts AI citation probability by 30-40%. Authoritative references lift visibility by up to 40%. Direct quotations add another 15-30%. These aren’t SEO tricks. They match the exact decision logic the leaked prompts confirmed.
The “black box” just told you what it’s looking for.
Developers Now Have a Real Benchmark, Not a Marketing Deck
Before this, the only public information about how leading AI labs structure agentic systems came from blog posts and conference talks, usually six months after the decisions were made.
The leaked codebase showed something more useful and more honest.
The main.tsx entry point was nearly 1MB with 68 state hooks and over 460 eslint-disable comments. The project contained 50 deprecated functions still actively running in production. Internal codenames were hex-encoded to avoid build-time security scanners.
The developer community’s reaction wasn’t “how embarrassing.” It was “this is exactly what our codebase looks like.”
That matters. It resets the benchmark from “clean, modular, perfectly documented” to “functional under commercial velocity.” For teams building agentic systems, this disclosure removed the implicit assumption that the gap between their architecture and a frontier lab’s architecture was primarily technical. Often, it’s just time and budget.
The autoDream Architecture Points to Where Agent Reliability Is Actually Going
One of the more significant findings in the leak was an unreleased feature called KAIROS, containing a background process codenamed autoDream.
The concept: while the user is idle, a forked sub-agent merges observations, resolves contradictions, and converts uncertain inferences into verified facts, without corrupting the main reasoning thread. The system also enforces “Strict Write Discipline,” prohibiting memory updates until file writes are confirmed, and instructs the model to treat its own recollections as hints to be verified, not facts to act on.
This is a specific, testable architecture for solving context entropy in long-running agents. It’s also almost entirely absent from public literature.
Before March 31, building a reliable multi-session agent meant guessing at this problem from first principles. Now there’s a reference design. That’s not a competitive threat for Anthropic. It’s a contribution to the field, whether intentional or not.
What This Means If You’re Trying to Get Your Brand Recommended by AI
The leaked system prompts confirm a structural shift in how AI assistants build answers. They don’t rank pages. They retrieve fragments from a multi-stage pipeline and assemble responses, prioritizing sources that signal domain authority, structured clarity, and factual density.
For brands, that changes the optimization target entirely.
Traditional SEO rewarded keyword matching. AI recommendation rewards what the Princeton study calls “Entity Authority”: a stable, independently verified identity across sources like Wikipedia, authoritative trade publications, and community platforms. The Claude Code prompts confirm this operationally. The model is calibrated against adversarial verbosity and trained to prefer precision.
Monitoring where your brand stands in that system isn’t optional anymore. It’s not enough to publish content and assume distribution. You need to track whether your brand appears in AI answers for the prompts that matter to your category, how your sentiment scores compare to competitors, and which sources AI platforms are actually citing.
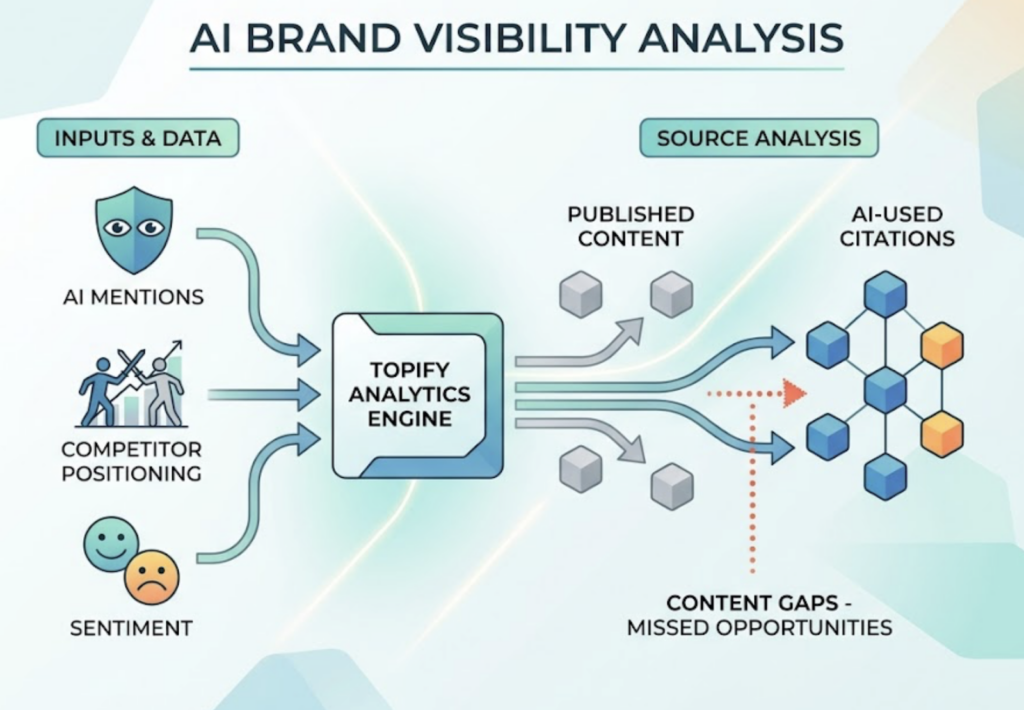
Topify tracks brand visibility across ChatGPT, Gemini, Perplexity, and other major AI platforms, mapping not just whether you appear, but your position relative to competitors and the sentiment attached to those mentions. Its Source Analysis feature shows exactly which domains AI is pulling citations from, so you can identify gaps between what you’re publishing and what AI is using. That’s the operational version of what the leaked prompts confirmed theoretically.
The Claude Code leak essentially handed GEO practitioners a primary source. Using it to audit your content strategy is a no-brainer.
Conclusion
The instinct to treat this as a crisis was understandable. A $19 billion AI lab’s internal architecture sitting on a public npm registry is a legitimate governance failure. The security implications, particularly around parser differentials and YOLO permission classifiers, are real and being addressed.
But the net effect on the industry is positive.
The disclosure confirmed what the research already suggested: AI systems reward transparency, structured clarity, and verifiable authority. It showed that agentic reliability depends on skeptical memory and offline consolidation, not just raw model capability. It proved that secrecy-as-security collapses on contact with a packaging bug.
The “glass box” was always coming. The EU AI Act and California’s transparency regulations were already drawing that line. What the Claude Code leak did was accelerate the reckoning by about 18 months, and do it with a concrete reference architecture instead of a policy document.
That’s a contribution, even if no one asked for it.
FAQ
Q: What exactly was leaked in the Claude Code incident?
A: A packaging error in version 2.1.88 of the @anthropic-ai/claude-code npm package accidentally included a 59.8MB JavaScript source map file. That file allowed developers to reconstruct approximately 512,000 lines of TypeScript source code across 1,906 files, including internal system prompts, memory architecture, tool definitions, and unreleased feature flags like KAIROS and autoDream.
Q: Was this a cyberattack or a hack?
A: No. It was a build process failure caused by a known bug in the Bun bundler, which included source maps in production despite explicit exclusion settings. No external party compromised Anthropic’s systems. The exposure happened through the public npm registry, not a breach.
Q: How does the Claude Code leak opinion connect to GEO and brand visibility?
A: The leaked system prompts confirmed that Claude models are calibrated to favor structured, factually dense, and authoritative content when generating answers. This directly validates the core mechanics of Generative Engine Optimization: brands that publish precise, well-cited content are more likely to be recommended by AI assistants than those relying on keyword density alone.
Q: What should marketers actually take away from this Claude Code leak?
A: Three things. First, audit your content against the signal types the leaked prompts favor: specific statistics, authoritative citations, and structural clarity. Second, build your brand’s Entity Authority across independent sources. Third, start tracking your AI visibility across platforms so you have a baseline before the August 2026 regulatory changes reshape how AI systems handle attribution.
Read More

