
Your team got the directive: start monitoring AI search. So you pulled up a few options, and that’s where it got murky. One tool claims to track ChatGPT mentions. Another counts citations. A third shows a “visibility score” with no explanation of how it’s calculated. Each one measures something different, and none of them agrees on what an AI search monitoring platform should even do. The result is a report you can’t defend in a meeting, because you’re not sure the number reflects whether AI is actually recommending your brand.
What an AI Search Monitoring Platform Actually Is
An AI search monitoring platform is a system that tracks how your brand shows up inside the answers large language models generate. That’s the core distinction. It doesn’t watch URLs or SERP positions the way a traditional SEO rank tracker does. It reads what ChatGPT, Perplexity, Gemini, and Google AI Overviews actually say when someone asks a question in your category.
The shift is from keyword-centric tracking to prompt-centric observation. Traditional rank tracking measures fixed positions in a static results page. AI search is probabilistic. A brand can rank #1 on Google and still be invisible in the synthesized answer an LLM hands a buyer.
So the question an AI search monitoring tool answers isn’t “where do I rank.” It’s whether the model mentions you, cites you with a link, and recommends you over a competitor. Some teams call this Share of Answer rather than share of rankings.
That reframing is the whole point.
How an AI Search Monitoring System Works
Most platforms run a three-stage pipeline built to handle the non-deterministic behavior of AI answers.
First, prompt sampling. Instead of monitoring thousands of static keywords, the system works from a curated prompt portfolio, typically 50 to 100 high-intent questions that map to the buyer’s journey. These are the questions real users actually type, not head terms.
Second, cross-platform polling. ChatGPT, Gemini, Claude, and Perplexity each run different retrieval pipelines and weight sources differently. A monitoring system polls them concurrently, because a brand that’s well-cited in Perplexity can be missing entirely from AI Overviews.
Third, parsing and scoring. Raw responses get parsed for brand mentions, source citations, answer position, and sentiment, then aggregated into time-series trends. That last part matters more than it sounds. Citation patterns in AI search can shift by up to 70% in a single week as engines update their RAG logic. Without trend data, you can’t separate temporary noise from a real visibility drop.
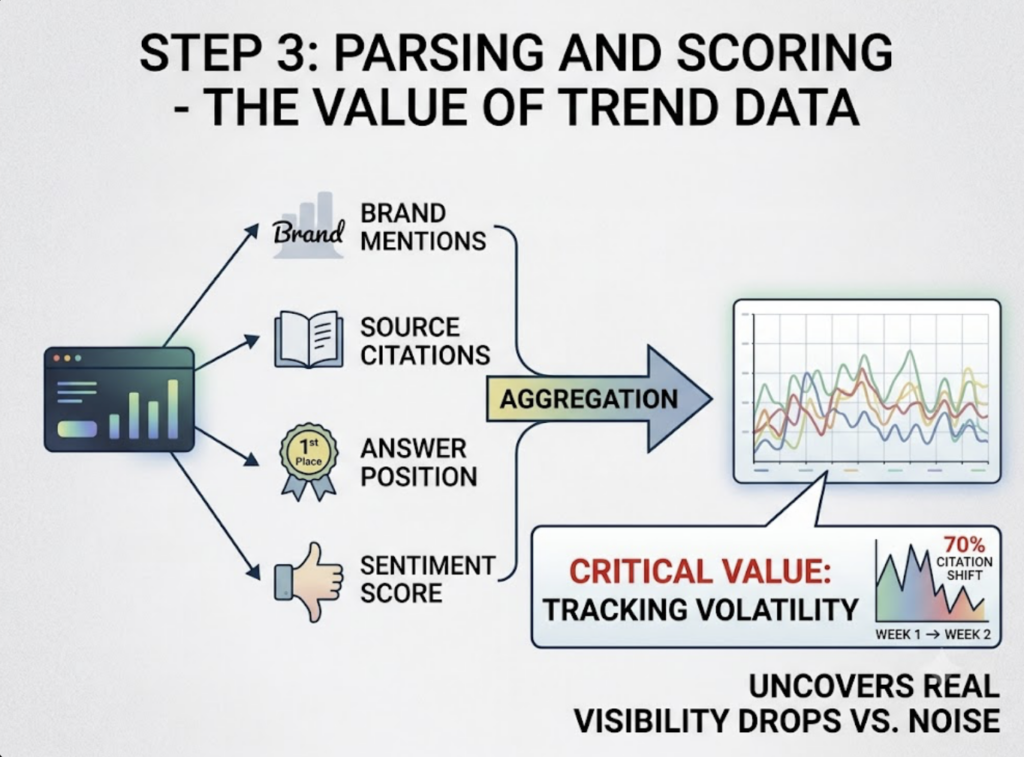
A snapshot tells you where you stood on Tuesday. A monitoring system tells you whether you’re drifting.
What an AI Search Monitoring Dashboard Should Measure
Here’s where a lot of dashboards go soft. They show you volume and raw mention counts because those numbers are easy to display, not because they tell you anything useful.
A worthwhile AI search monitoring dashboard shifts focus from traffic volume to entity authority. The metrics that matter map to specific business questions:
| Metric | The question it answers |
|---|---|
| Visibility Rate | Is the brand present in the conversation at all? |
| Citation Share | Does the AI trust the brand enough to link to it? |
| Positioning | Does the brand land in the main summary or a buried footnote? |
| Sentiment | How does the model frame the brand’s authority? |
| Share of Voice | How does the brand compare to competitors in AI answers? |
One metric sits above the rest for proving ROI: AI referral traffic, tracked through utm_source tagging. Visibility is the leading indicator. Referral traffic is the bottom line. Good AI search monitoring analytics connect the two, so you can show that a rise in citation share actually moved real visits.
Common Mistakes in AI Search Monitoring
Four mistakes show up over and over, and most of them come from importing old SEO habits into a new channel.
Single-platform bias. Monitoring only ChatGPT ignores the sourcing logic of Perplexity and Google AI Overviews, which pull from different places. You end up optimizing for one model’s quirks and calling it coverage.
Vanity metric obsession. Counting raw mentions without checking whether they’re linked gives a false sense of security. An unlinked mention rarely sends traffic, and it rarely signals the kind of trust that gets you recommended again.
Ignoring citation drift. As RAG pipelines update, brands cycle in and out of the authoritative source list. Teams that treat AI visibility as a one-time snapshot miss the moment a model quietly drops them.
Static keyword reliance. Forcing traditional keyword lists onto AI search, instead of optimizing for natural-language questions and entity authority, produces content the models don’t retrieve.
That’s the gap most dashboards quietly skip.
How to Choose the Best AI Search Monitoring Solution
Pick a tool by what it measures, not by how its dashboard looks. Measurement methodology is where these solutions actually diverge.
Run any AI search monitoring solution through five questions before you commit:
| Evaluation dimension | Why it matters |
|---|---|
| Engine coverage | Does it include ChatGPT, Perplexity, Gemini, and AI Overviews, not just one? |
| Citation layer | Can it separate a passing mention from a trusted, linked source? |
| Drift tracking | Will it flag when an AI drops your brand from its answers? |
| Competitor benchmarking | Can it show your relative authority inside the category? |
| Actionable insights | Does the data map to specific fixes like schema, FAQ structure, or entity authority? |
Use it as a literal checklist. A platform that nails coverage but can’t tell you why a competitor got cited will leave you monitoring a problem you can’t act on.
Where Topify Fits as an AI Search Monitoring Platform
Map those five criteria onto an actual product and you get a sense of what an integrated system looks like.
Topify is built as a GEO platform rather than a standalone monitor, which mostly shows up in how it closes the gap between a signal and a fix.
Its Comprehensive GEO Analytics tracks seven dimensions of AI visibility in one view: visibility, sentiment, position, volume, mentions, intent, and CVR. That covers the metrics worth measuring and adds a conversion-oriented layer most monitoring tools skip.
Competitor benchmarking runs in real time, so you can see exactly where a rival is winning citations you’re not. Source analysis goes a step further and reverse-engineers why an AI chose that competitor, building an authority map you can point content at.
Then there’s the part that separates monitoring from optimization. Topify’s one-click execution turns a visibility gap into a content brief, so the same platform that spots the problem helps you act on it. For teams tracking visibility across four engines at once, having detection and action in one place tends to cut the lag between noticing a drop and fixing it.
Detection without action is just a prettier report.
Turning Monitoring into a GEO Strategy
Monitoring is the starting line, not the finish. The teams that improve their AI search results treat every visibility gap as a content opportunity rather than a status update.
The strategy is a loop. Define a prompt portfolio around real buyer intent. Monitor across all major engines at once. When a gap shows up, trace it to its cause through source analysis, ship the content or schema fix, then re-test to confirm the model picked it up.
The brands that pull ahead are the ones optimizing for consistency over snapshots. Citation authority compounds. A source an AI trusts this month tends to get pulled again next month, which is how a brand moves from occasional mention to default recommendation.
Conclusion
Choosing between AI search monitoring tools feels hard because they don’t measure the same things. The fix is to decide what you need to track before you shop. Stop chasing rankings and start tracking citations.
Define a prompt portfolio based on buyer intent. Monitor every major engine at once, not just the one you use personally. Treat each visibility gap as a chance to strengthen your entity authority, and watch trends instead of snapshots. Do that, and the report you bring to the next meeting stops being a guess. It becomes evidence of whether AI is recommending your brand, plus a clear plan for the spots where it isn’t.
FAQ
Q: How much does an AI search monitoring platform cost?
A: Pricing varies widely by coverage and depth. Entry-level monitoring tools start low, while integrated GEO platforms that include execution sit higher. Topify’s self-serve plans begin at $99/month for the Basic tier, which covers ChatGPT, Perplexity, and AI Overviews tracking with 100 prompts, then scale through Pro and Enterprise. The right number depends less on sticker price and more on how many engines and prompts you need to track. Current tiers are on the Topify pricing page.
Q: What are some examples of what these platforms track?
A: Common examples include visibility rate (whether you appear), citation share (whether the AI links to you), answer position, sentiment, and share of voice against competitors. More advanced systems also track AI referral traffic through utm_source tagging to tie visibility back to real visits.
Q: How is an AI search monitoring tool different from an SEO rank tracker?
A: A rank tracker measures fixed positions in a static results page. An AI search monitoring tool reads the natural-language answers LLMs generate, which are probabilistic and change week to week. One tells you where a URL ranks. The other tells you whether AI mentions and recommends your brand at all.
Q: How do I improve my AI search monitoring platform results once I’m tracking them?
A: Start with the gaps the data surfaces. Find the prompts where competitors get cited and you don’t, then optimize for natural-language questions, entity authority, and structured formats like FAQ and schema. Re-test after each change to confirm the engines picked it up, since improvement here is iterative, not one-and-done.

