
Your team spent months building domain authority, earning backlinks, and climbing Google rankings. Then a prospective buyer asked ChatGPT, “What’s the best tool for [your category]?” and got a list of five recommendations. Your brand wasn’t on it.
The frustrating part isn’t the omission. It’s that nothing in your analytics dashboard flagged it. Traditional SEO metrics still show green across the board, keyword positions look stable, and traffic from Google hasn’t changed much. But somewhere between 60% and 93% of informational queries now resolve inside an AI-generated answer, without a single click to any website. The buyers are still researching. They’re just not visiting your site to do it.
That’s the gap an AI response monitoring tracker is built to close.
What an AI Response Monitoring Tracker Actually Measures (and Why SEO Dashboards Can’t)
An AI response monitoring tracker is a system that continuously monitors how large language models and AI search engines represent your brand when users ask natural-language questions. It’s not tracking keyword rankings or URL positions. It’s tracking whether the AI mentions you at all, how it describes you, where it places you relative to competitors, and which sources it cites to justify its answer.
The core shift here is from “Keyword-to-URL” mapping to “Prompt-to-Entity” association. In traditional search, a keyword triggers a list of links ranked by relevance. In AI search, a prompt triggers a synthesis process where the model evaluates your brand’s presence across its training data and real-time retrieval window. You’re no longer competing for a spot on a page. You’re competing for space in the model’s recommendation logic.
That distinction matters commercially. Click-through rates for informational queries dropped by 61% in 2025, even as search volume kept growing. Brands are still being searched for, but they’re being discovered inside the AI’s synthesized response. And the data shows that 92.36% of AI Overview citations pull from domains already ranking in the top 10 of traditional search, with cited brands seeing a 35% to 91% lift in CTR over non-cited brands appearing in the same result.
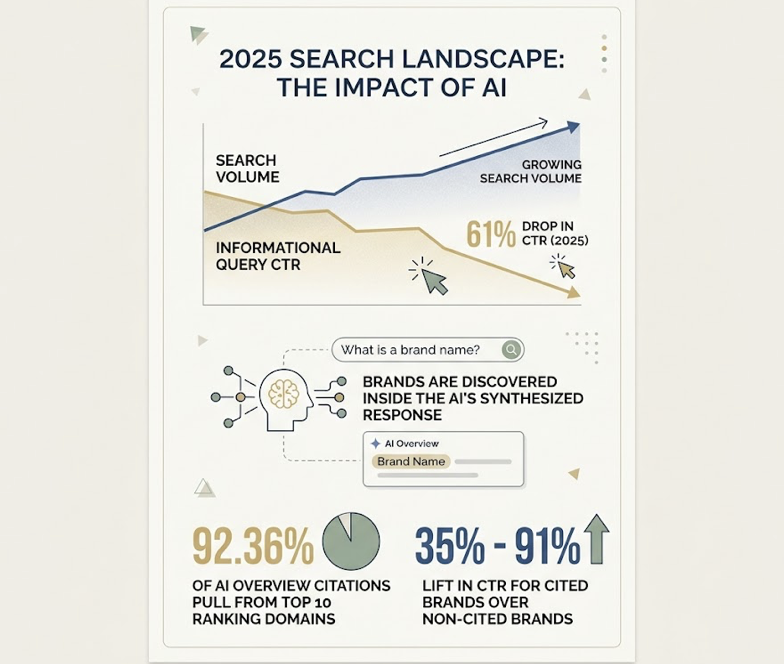
Without a tracker, all of that influence stays invisible.
How AI Response Monitoring Trackers Work Behind the Scenes
The technical backbone of an AI response monitoring tracker is prompt-level simulation. The system programmatically sends real-world user queries to AI engines, captures the full response, and analyzes the content for brand mentions, sentiment, positioning, and citations.
Most professional trackers use a hybrid approach. API-level tracking provides clean, structured data from the model’s backend, establishing what the model “knows” from core training. Browser-level scraping mimics an actual user session, capturing live elements like Google AI Overviews or Perplexity’s real-time web citations that shift based on geography, device, and user history.
The complexity increases because each AI platform operates differently. ChatGPT combines pre-trained knowledge with SearchGPT for real-time retrieval. Perplexity functions primarily as an answer engine, pulling heavily from the most recently published authoritative content. Google AI Overviews integrate directly into the traditional search index, favoring domains with strong E-E-A-T signals. A single-platform tracker misses the full picture.
One technical challenge worth noting: non-determinism. The same prompt can produce slightly different outputs depending on model temperature settings or updated training weights. Advanced trackers handle this through “Query Fan Out,” running the same prompt multiple times and flagging response drift or accuracy drops. If a third-party review site lists your price as $79 but your site says $99, the AI might hallucinate a figure in between. Detecting that inconsistency before your customers do is exactly what a monitoring tracker is for.
The 7 Metrics That Separate Useful AI Monitoring from Vanity Dashboards
Not all AI visibility data is created equal. The difference between a useful monitoring setup and a vanity dashboard comes down to which metrics you’re tracking and whether they connect to revenue.
Here’s what a professional-grade system measures:
Visibility Score. The percentage of responses where your brand appears across a set of high-intent prompts. A score of 40% means in 4 out of 10 relevant AI conversations, you’re named as a solution.
Sentiment Score. An NLP-driven rating (0 to 100) that evaluates how the AI frames your brand. Being mentioned is one thing. Being described as “legacy” or “overpriced” is another.
Position Weighting. In a conversational response, the first-named brand carries disproportionate influence. Being listed in an “also consider” section at the end of a long answer is not the same as being the opening recommendation.
Mention Frequency. The raw count of brand occurrences across platforms. This measures your “Entity Density” in the model’s output.
Share of Citation. How often the AI links to your domain compared to competitors. High citation share is the primary driver of referral traffic from AI platforms.
Conversational Volume. The AI equivalent of search volume. Panel data estimates how many users are engaging with AI on specific topics, helping teams prioritize the prompts that represent the largest market opportunity.
Conversion Efficiency (CVR). The bottom-line metric. By integrating with Google Analytics 4 or Shopify, trackers can attribute revenue directly to AI citations. This matters because visitors arriving from an AI recommendation convert at 4.4x the rate of traditional organic search visitors.
Different roles need different slices of this data. A CMO focuses on Share of Model Voice and Sentiment for long-term competitive positioning. Brand managers prioritize mention accuracy and hallucination detection. SEO and content teams zero in on citation share and source attribution to figure out which content pieces are actually feeding the models.
5 Mistakes That Tank Your AI Response Monitoring Strategy
Implementing a tracker without understanding how LLMs actually behave leads to misleading data and wasted budget. These are the five most common failure modes.
Tracking only one AI platform. Many teams default to ChatGPT because of its market share. But brand representation is highly fragmented across models. A brand can hold 24% Share of Model on Meta’s Llama while sitting below 1% on Google’s Gemini. Perplexity users skew toward senior enterprise leadership, while ChatGPT has broader general adoption. One platform gives you one slice, not the full picture.
Filling your prompt library with branded searches. Queries like “What is [Brand]?” or “How do I use [Product]?” are useful for accuracy checks, but they don’t reflect how buyers discover new solutions. The high-value prompts are unbranded: “What’s the best project management tool for remote engineering teams?” If you’re only monitoring your own name, you’re missing the entire discovery phase.
Counting mentions without checking framing. Traditional SEO treated any Page 1 result as a win. In AI search, visibility is binary but also qualitative. An AI might mention your brand and then add: “While [Brand] is a popular choice, users frequently report issues with integration speed.” Without sentiment and position tracking, you might think you’re winning while actively losing customers.
No competitive benchmarking. AI visibility within a single response is zero-sum. If your visibility rises 10% but a competitor’s rises 50% across the same high-intent prompts, you’re losing recommendation share. Without a competitive framework, you can’t spot the “Entity Neighborhoods” where rivals are winning and you’re absent.
Ignoring source attribution. This is the most consequential mistake. AI models rely on a narrow set of authoritative domains to verify answers. If you don’t know which third-party sites (Reddit, industry publications, review platforms) the AI is citing, you can’t optimize your PR, content, or outreach strategy to influence those sources.
| Strategic Mistake | Consequence | Corrective Action |
|---|---|---|
| Single-engine focus | Missing up to 80% of buyer discovery paths | Track ChatGPT, Gemini, Perplexity, and AI Overviews |
| Branded-only prompts | Invisible during the research phase | Use 75% unbranded, intent-based prompts |
| Ignoring sentiment | Brand damage at the point of recommendation | Implement NLP-driven sentiment analysis |
| No competitor framework | Can’t measure relative market share | Baseline against 3 to 5 key rivals |
| Ignoring citations | Wasted content on untrusted sources | Reverse-engineer the AI’s trust neighborhood |
A Step-by-Step Strategy for Setting Up Your AI Response Monitoring Tracker
Moving from traditional SEO reporting to AI-first monitoring doesn’t require scrapping everything you’ve built. It requires adding a new measurement layer. Here’s a five-step framework.
Step 1: Define your AI platform scope. Your target audience determines which engines matter most. For B2B SaaS, ChatGPT and Perplexity are typically priorities since buyers use them for vendor shortlisting. For consumer brands, Google AI Overviews and Meta AI are more relevant due to their integration into search and social surfaces. Cover at least three engines for cross-model reliability.
Step 2: Build a prompt library grounded in real buyer behavior. A “Golden Prompt” library typically starts with 50 to 100 questions across four tiers: informational (“What’s the best way to automate [process]?”), comparative (“[Brand] vs [Competitor] for enterprise security?”), transactional (“Which [category] tool has the lowest TCO?”), and branded/accuracy (“What are the latest features of [Brand]?”). Source these from sales call recordings, Reddit discussions, and Google’s “People Also Ask” sections.
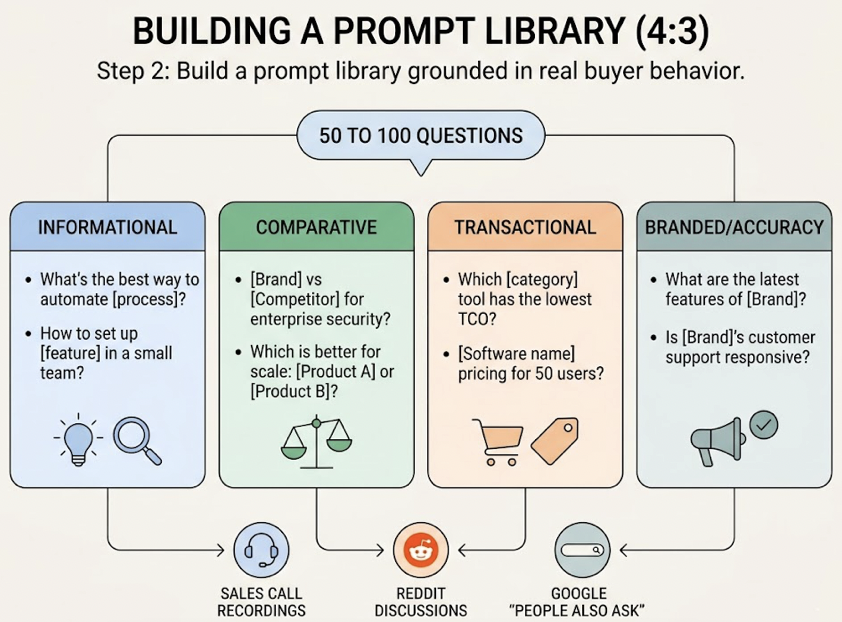
Step 3: Run a 30-day baseline measurement. Before optimizing anything, you need to know where you stand. This baseline reveals your current AI visibility score and surfaces “Dark Queries,” the prompts where your brand should appear based on SEO rankings but is currently missing from AI responses.
Step 4: Map the competitive field. Configure your tracker to detect which brands are “Citation Leaders” (cited for links) and “Mention Leaders” (recommended by name). This reveals the Entity Association Gap. If the AI consistently pairs a competitor with “enterprise-grade” and pairs you with “small business,” you’ve uncovered a positioning problem that content alone can fix.
Step 5: Set a reporting cadence and optimization loop. Weekly monitoring works for established brands. Daily tracking is better during active campaigns or product launches. The cycle looks like this: detect a drop in citation share on a key prompt, identify that the AI switched from citing your blog to a competitor’s new research report, produce a more comprehensive piece with proper Schema markup, then validate through the tracker that the AI updated its source within 14 days.
That loop is where monitoring turns into growth.
What the Best AI Visibility Solutions Available Look Like in Practice
The market for AI response monitoring is split between legacy SEO platforms bolting on AI features and GEO-native platforms built specifically for this problem. The difference matters.
Here’s what to evaluate when choosing a tool: multi-model coverage (does it track ChatGPT, Gemini, Perplexity, Claude, and regional engines like DeepSeek or Doubao?), an execution layer (does it tell you how to fix the gaps it finds?), attribution integration (can it connect AI citations to GA4 or Shopify revenue?), and enterprise compliance (SOC 2, HIPAA readiness).
| Platform | Notable Feature | Starting Price | Best For |
|---|---|---|---|
| Topify | 7-dimension metrics + one-click agent execution | $99/mo | Teams needing end-to-end optimization |
| Profound | “Prompt Volumes” panel data + shopping visibility | $399/mo | Large orgs focused on deep market research |
| ZipTie | On-page crawlability audits for AI agents | $69/mo | SEO teams focused on the Big Three engines |
| Otterly AI | Broadest engine coverage at low cost, daily tracking | $29/mo | Solo marketers and small teams on a budget |
Topify stands out for teams that need more than a dashboard. Its platform covers ChatGPT, Gemini, Perplexity, DeepSeek, Doubao, Qwen, and other major AI engines, tracking seven core metrics (visibility, sentiment, position, volume, mentions, intent, and CVR) across all of them. But the real differentiator is the execution layer.
Most monitoring tools stop at data. Topify’s AI agent identifies the prompts where competitors are winning, surfaces high-volume opportunities as AI recommendations evolve, and helps teams deploy optimized content with a single click. For e-commerce brands, that means identifying category prompts like “best eco-friendly running shoes” and optimizing product pages so AI agents can extract and recommend specific SKUs. For B2B SaaS teams, it means closing the gap between “being mentioned” and “being the first recommendation.”
Pricing scales with usage: the Basic plan starts at $99/mo (100 prompts, 9,000 AI answer analyses, 4 projects), Pro at $199/mo (250 prompts, 22,500 analyses, 10 seats), and Enterprise from $499/mo with a dedicated account manager. You can check current pricing details on the Topify website.
The team behind the platform includes a GEO strategy lead with 10+ years of Fortune 500 SEO experience, an LLM algorithm researcher from Stanford with publications at NeurIPS and AAAI, and a growth operator who’s scaled companies from zero to $20M in revenue.
Ready to see where your brand stands? Get started with a baseline audit and find out which AI platforms are recommending your competitors instead of you.
Conclusion
The shift from “searchable” to “recommended” isn’t coming. It’s already here. Between 60% and 93% of informational queries now resolve inside AI-generated answers, and the brands that show up in those answers convert at 4.4x the rate of traditional organic traffic.
An AI response monitoring tracker gives you the visibility your existing analytics can’t: which AI platforms mention you, how they frame you, where they rank you against competitors, and which sources they trust. The five-step framework outlined above, defining your platform scope, building a real prompt library, running a 30-day baseline, mapping competitors, and establishing an optimization loop, is where most successful teams start.
The brands winning in AI search aren’t the ones with the highest domain authority. They’re the ones who know exactly what the models are saying about them and have a system to influence it.
FAQ
Q: What is an AI response monitoring tracker? A: An AI response monitoring tracker is a system that continuously monitors how AI platforms like ChatGPT, Perplexity, and Google AI Overviews mention, describe, and recommend your brand when users ask natural-language questions. It tracks metrics like visibility, sentiment, position, and citation sources across multiple AI engines.
Q: How does an AI response monitoring tracker work? A: It uses prompt-level simulation, programmatically sending real user queries to AI engines and analyzing the full response. Professional trackers combine API-level tracking (for structured baseline data) with browser-level scraping (for real-time citations and live search results), running prompts multiple times to detect response drift and inconsistencies.
Q: What’s the difference between AI response monitoring and traditional SEO tracking? A: Traditional SEO tracks keyword-to-URL rankings on search engine results pages. AI response monitoring tracks prompt-to-entity associations, measuring whether AI models mention your brand, how they frame it, and which sources they cite. The two systems measure fundamentally different discovery paths.
Q: How much does an AI response monitoring tracker cost? A: Pricing varies by platform and scale. Entry-level tools start around $29/mo for basic tracking, mid-tier platforms like Topify start at $99/mo with full 7-dimension metrics and execution capabilities, and enterprise solutions range from $399/mo to $499/mo+ depending on prompt volume and custom requirements.

