
Your CEO asks a simple question in the Monday standup: “How are we showing up when someone asks ChatGPT or Perplexity for a recommendation in our category?” You pull a couple of screenshots from last week. By the time you’ve answered, the data’s already stale. Large language models are non-deterministic, so the same prompt can surface a different set of brands in more than 38% of consecutive runs. Spot-checking by hand can’t keep pace with that kind of variance. What you need isn’t another screenshot. It’s a repeatable way to measure where your brand stands, across platforms, on a cadence you can actually report against.
Why AI Response Monitoring Strategy Can’t Be an Afterthought
AI search stopped being an experiment a while ago. By February 2026, ChatGPT alone passed 900 million weekly active users, and roughly 37% of consumers now start product research inside an AI tool rather than a search box.
The bigger shift is behavioral. About 58.5% of search sessions now end without a single click to an external site. The answer happens inside the model. If your brand isn’t in that answer, the customer often never learns you exist.
That’s the gap most dashboards still can’t see.
For B2B teams the stakes are sharper. Around 94% of buyers now fold generative AI into their purchase process somewhere, from shortlisting vendors to checking alternatives. A monitoring strategy isn’t a nice-to-have reporting layer anymore. It’s how you find out whether AI is recommending you or quietly routing demand to a competitor.
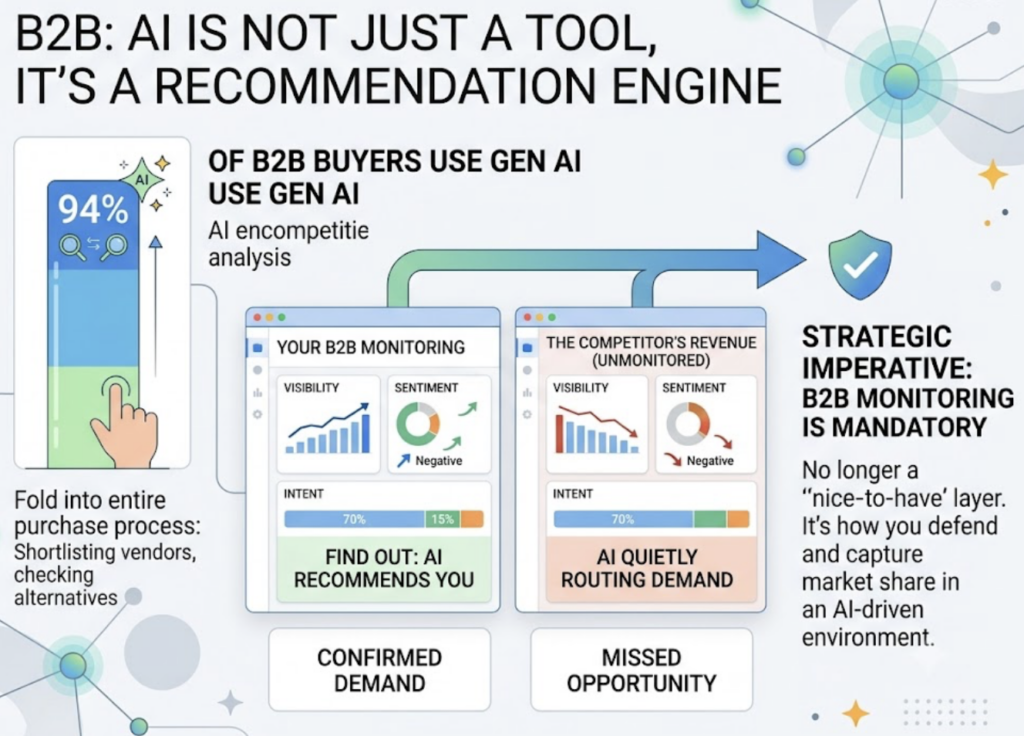
What an AI Response Monitoring Strategy Actually Tracks
Most teams start and stop at “did we get mentioned.” That’s a binary that hides almost everything useful. A mature AI response monitoring strategy tracks four dimensions, and each one answers a different question.
Mention and visibility rate. How often your brand shows up across the high-intent prompts that matter to revenue. This is the baseline, but it’s only the floor.
Positioning and salience. Being named tenth in a list is not the same as being the top recommendation. Position matters more than most teams assume: a brand in the first slot of an AI answer is about 3.1× more likely to drive a click-through than one buried further down.
Sentiment and context. How the model frames you. There’s a real difference between “a solid budget option” and “a premium enterprise platform.” If AI consistently describes your product in language that fights your positioning, a mention can work against you.
Source authority. The upstream domains the model leans on when it builds an answer, think Reddit, G2, Wikipedia, industry roundups. If your brand is missing from those nodes, the model has fewer reasons to cite you, no matter how good your own site is.
Track one dimension and you get noise. Track all four and you get a strategy.
How to Build an AI Response Monitoring Strategy in 5 Steps
Here’s a framework you can stand up without a data science team. The point is to turn ad-hoc checking into something systematic.
Step 1: Build a prompt library. Curate 50 to 150 revenue-critical prompts, the questions real buyers ask. Think “best [category] alternatives,” “[your brand] vs [competitor],” and “tools for [specific use case].” These prompts are your measurement instrument, so they need to reflect actual intent, not vanity queries.
Step 2: Cover multiple engines. ChatGPT, Perplexity, and Google’s AI Overviews each pull from different retrieval indexes. Optimizing for one tells you almost nothing about the others. Multi-engine coverage isn’t optional if you want a real picture.
Step 3: Set a metric baseline. Standardize on a single AI Visibility Score that rolls presence, position, and sentiment into one number you can trend over time. Without a baseline, every report becomes a fresh argument about what “doing well” means.
Step 4: Pick a cadence that filters noise. Daily readings swing wildly because of model variance. Use 7-day or 30-day rolling averages instead, so you’re reacting to genuine movement rather than the model’s mood that morning.
Step 5: Close the loop. Monitoring that doesn’t feed action is just expensive curiosity. When visibility drops on a prompt, correlate it with a content gap or a missing third-party mention, fix that, and watch whether the score recovers. Measure. Diagnose. Act.
How to Track Brand Mentions in Perplexity
Perplexity deserves its own playbook, and here’s why: only about 25% of cited domains overlap between ChatGPT and Perplexity for the same query. A strategy tuned for ChatGPT will miss most of what’s happening on Perplexity.
Perplexity is citation-first by design. It shows its sources right alongside the answer, which means to track brand mentions in Perplexity you’re really watching two things at once: whether you’re named in the synthesized response, and whether your domain made it into the citation list underneath.
You can do this by hand. Run your prompt library through Perplexity, log every mention, note the position, and check the source list each time. The problem is scale and decay. Manual checks can’t cover 100 prompts across multiple engines on a weekly rhythm, and the data goes stale within days as citation patterns shift.
That’s where automation earns its place. Tracking mention rate, citation inclusion, and source overlap on a schedule turns a one-off audit into a living signal you can act on.
Where AI Response Monitoring Strategies Quietly Fail
Plenty of teams set up monitoring and still end up flying blind. The failure modes are predictable.
The one-engine trap. Optimizing only for ChatGPT ignores Perplexity’s research-heavy, citation-led audience entirely. Different engine, different game.
Treating every mention as a win. If the model keeps attaching negative qualifiers to your brand, you may be losing buyers before they ever reach your site. Sentiment isn’t a vanity metric.
No attribution. When AI mentions get logged as generic impressions instead of pre-click signals, you miss the link between visibility spikes and the branded search volume that follows. The teams that win track that correlation deliberately.
Manual inefficiency. Relying on human auditors builds in a 48 to 72 hour lag between a market shift and your response. At enterprise scale, that delay is the whole ballgame.
Turning Monitoring Data Into Action With Topify
The hard part of an AI response monitoring strategy isn’t collecting data. It’s connecting a drop in visibility to the specific reason behind it, fast enough to do something about it. That’s the gap Topify is built to close.
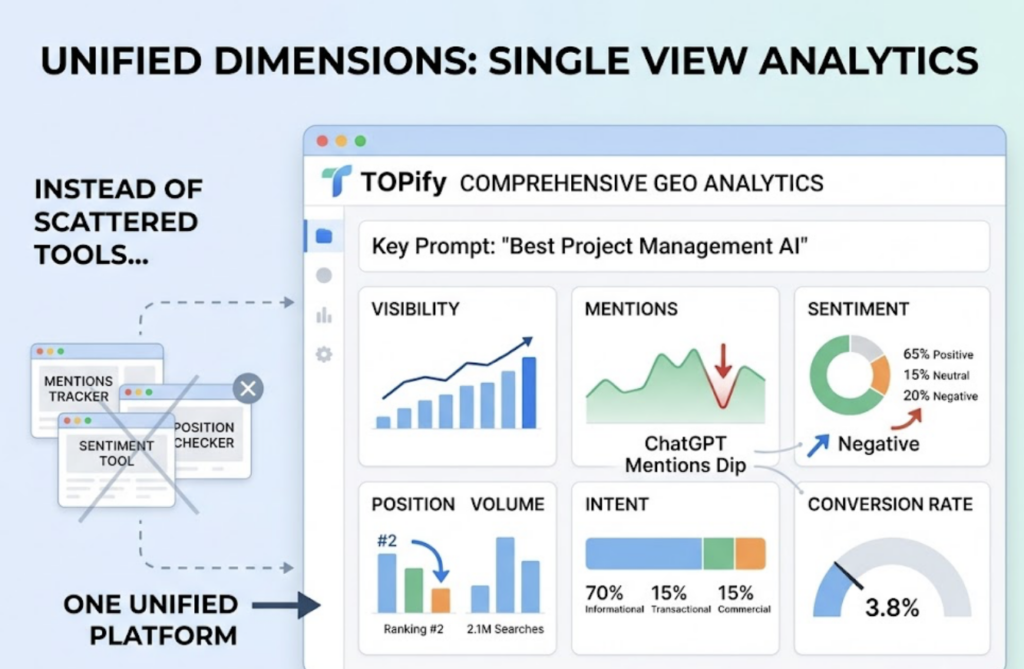
Instead of stitching together screenshots and spreadsheets, Topify’s Comprehensive GEO Analytics aggregates performance across seven dimensions in one view: visibility, mentions, sentiment, position, volume, intent, and conversion rate. So when ChatGPT mentions dip on a key prompt, you see the position change and the sentiment shift in the same place, not three separate tools.
Source Analysis handles the citation supply chain. It reverse-engineers the exact domains and URLs the models cite, which lets you see whether competitors are pulling authority from review sites or forums you’re absent from. That’s usually where lost visibility actually originates.
Competitor Monitoring rounds it out by flagging where rivals consistently outrank you in comparison queries, so you can prioritize the content gaps that move the needle rather than guessing. The payoff isn’t just tidier reporting. AI-referred traffic converted about 31% higher than traditional search referrals over the 2025 holiday season, which means visibility in these answers tends to reach buyers with sharper intent. You can get started with Topify and run your prompt library across all three major engines from a single dashboard.
Conclusion
AI answers are becoming the place buying decisions start, and the brands that show up are the ones measuring it on purpose. You don’t need to boil the ocean to begin. Build a prompt library around your highest-intent queries, cover ChatGPT and Perplexity at minimum, and commit to a weekly or monthly cadence with a real feedback loop. Strategy beats spot-checking every time. Get those three things running, then layer in source and competitor analysis once the baseline is stable.
FAQ
How do I track brand mentions in Perplexity?
Run your high-intent prompts through Perplexity and log two things each time: whether your brand appears in the answer, and whether your domain shows up in the source citations beneath it. Because Perplexity is citation-first, the source list matters as much as the mention itself. For ongoing tracking, automate it so you’re capturing changes weekly rather than auditing by hand.
How to track brand mentions in Perplexity without checking manually?
Use a monitoring platform that runs your prompt set against Perplexity on a schedule and records mention rate, position, and citation inclusion automatically. This removes the 48 to 72 hour lag that manual auditing introduces and lets you spot citation shifts as they happen.
How often should I run AI response monitoring?
Use 7-day or 30-day rolling averages rather than daily checks. Model output varies enough that daily readings create false alarms. Rolling windows normalize that variance so you respond to real trends.
What metrics matter most in an AI response monitoring strategy?
Four: mention rate, position, sentiment, and source authority. Mention rate is the floor, position drives clicks, sentiment shapes perception, and source authority explains why the model cites you or doesn’t. Tracking only one gives you a misleading picture.

