
Your team spent six months building content, earning backlinks, and climbing Google rankings. Then a prospect opened ChatGPT, asked for the best option in your category, and got a tidy list of five names. Yours wasn’t one of them. Nothing in your analytics flagged it, because traditional metrics were never built to measure what AI chooses to say about you. That gap, between the search world you can see and the AI answers you can’t, is what an AI response monitoring service exists to close.
What an AI Response Monitoring Service Actually Tracks
An AI response monitoring service systematically analyzes how large language models and answer engines represent your brand across real user prompts. It’s not web ranking, and it’s not social listening. AI engines synthesize answers rather than return a list of links, so the unit of measurement shifts from “where does my page rank” to “what does the model say when someone asks.”
That distinction matters more than it first appears.
Counting how many times your name shows up is a vanity metric. It tells you nothing about whether you were recommended as a top choice or buried as a footnote, whether the model called you a market leader or a legacy option, or whether it linked to your content as a source. The useful signal lives in three layers: positioning, sentiment, and citation. A name that appears without a citation means the model knows you exist but doesn’t trust you enough to point to you.
So a real monitoring service tracks the full picture: whether your brand appears, how it’s described, which competitors share the answer, and which sources the model cites to justify the response. The most reliable way to capture this is prompt testing across platforms like ChatGPT, Google AI Overviews, Perplexity, and Claude, since no single method gives you complete visibility on its own.
How an AI Response Monitoring Service Works, Step by Step
The mechanics are more structured than “ask the AI and screenshot it.” A working AI response monitoring service runs on prompt clusters, not keywords.
First, you build a set of prompts that mirror how customers actually phrase intent: “best [product] for [use case],” “compare [brand A] and [brand B],” “alternatives to [competitor].” Then those prompts run across the major engines on a recurring schedule, often weekly. The system captures each response, extracts your brand’s position in the list, records the sentiment around it, and logs the exact sources cited.
The last step is the one most teams skip: tracking change over time.
AI answers are non-deterministic. Ask the same question twice and the wording shifts. A single screenshot is anecdote, not data. What you’re really measuring is the probability that your brand appears for a given prompt, and how that probability moves week to week. A monitoring service watches for displacement events, the moments a competitor enters an answer while you drop out, and ties those shifts back to something you can act on.
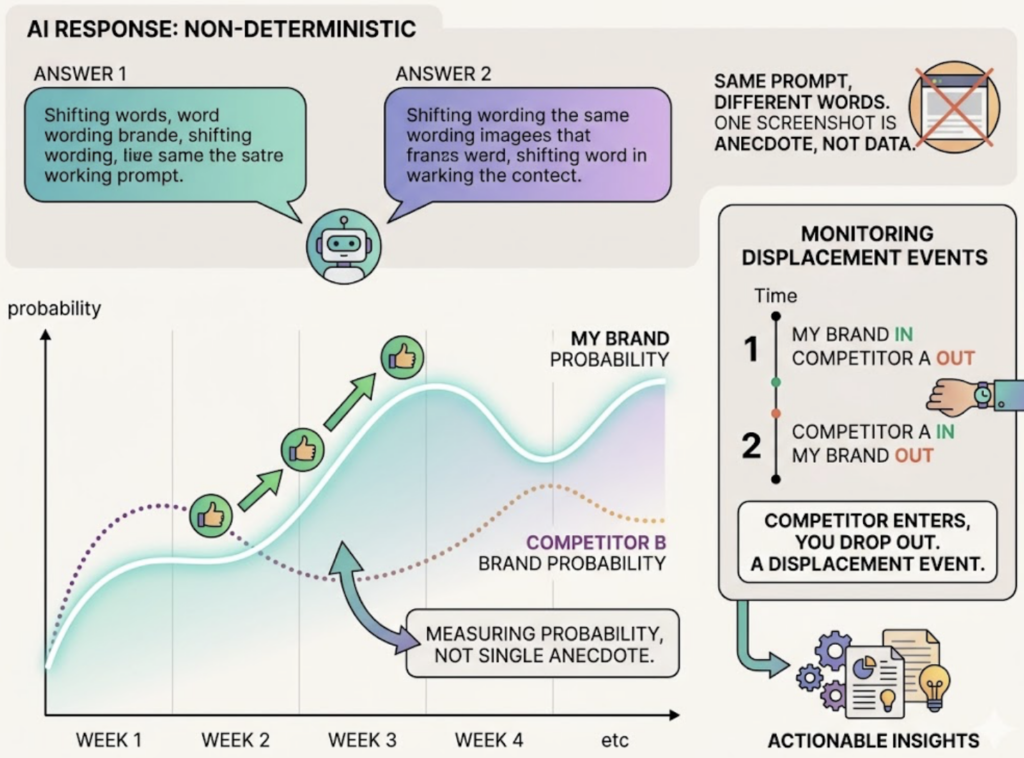
The 7 Metrics That Show Whether You’re Visible to AI
Knowing how to measure an AI response monitoring service is what separates a dashboard you check once from a system that drives decisions. Surface-level tools report mentions and stop. A measurement framework worth its cost spans seven dimensions.
| Metric | What it answers |
|---|---|
| Visibility | How often you appear across tracked prompts and platforms |
| Mentions | Where and in what context your name surfaces |
| Position | Are you recommended first, or listed fifth |
| Sentiment | Does the model describe you favorably, neutrally, or as a fallback |
| Share of Voice | Your presence in AI answers versus direct competitors |
| Citation Authority | How often the model links to your site as the source |
| CVR | The likelihood an answer pushes a user toward you |
These map onto what most research now treats as the three pillars of AI visibility: share of voice, citation authority, and sentiment positioning. The single most telling indicator is the gap between mentions and citations. If you’re named often but cited rarely, you haven’t earned enough authority to be the source of truth, and that gap is exactly where competitors quietly absorb the traffic.
This is where a purpose-built platform earns its place. Topify tracks all seven metrics across ChatGPT, Gemini, Perplexity, and other major engines in one view, and its Source Analysis reverse-engineers the precise domains and URLs the models cite. In practice, that means you can spot a drop in ChatGPT mentions and trace it to a specific source that stopped referencing you, inside the same dashboard.
5 Mistakes That Make AI Response Monitoring Useless
Most teams don’t fail at monitoring because they pick the wrong tool. They fail because they measure the wrong things, or measure and never act.
The volume trap. Prioritizing raw mention counts over citation authority. A high count with no citations means the model talks about you without trusting you.
Static snapshots. A one-time check ignores the probabilistic nature of AI answers. You need recurring runs to see the trend, not a lucky screenshot.
Chasing citations, ignoring mentions. In most commercial contexts, getting recommended by name moves the needle more than a linked footnote. Both matter, but teams that obsess over citations alone miss the recommendation that actually drives the deal.
Treating GEO and SEO as silos. AI engines weigh the same trust signals as traditional search: editorial mentions, reviews, technical authority. A monitoring program disconnected from your SEO work duplicates effort and misses leverage.
Ignoring localized context. AI responses vary by region. A brand that dominates US answers can be invisible in another market, and global-only reporting hides it.
The common thread: data without action is theater. Monitoring is the input, not the outcome.
From Tracking to Improvement: Turning Data Into Action
A monitoring service only pays off when it closes a loop. The strategy is simple to describe and harder to sustain: detect the gap, fix the underlying signal, recheck.
Detection comes from the metrics above. When a displacement event shows a rival winning a prompt you used to own, the next move is to look at what they’re citing and where your content falls short. Often the fix is structural: clearer answer-first formatting, stronger original data, better topical authority on the exact question being asked.
Here’s the part most teams underestimate. You can verify AI-driven impact with first-party data. OpenAI already provides UTM referral tracking, so you can see real traffic arriving from AI tools in your own analytics. Pair that with recurring manual prompt checks and you have a measurement framework built on outcomes you can confirm, not scores a dashboard invented.
This is where execution speed separates platforms. Topify’s One-Click Execution lets you state a goal in plain language, review the proposed GEO strategy, and deploy it without rebuilding a manual workflow each time. The point isn’t automation for its own sake. It’s shortening the distance between seeing a problem in the data and doing something about it.
Tools vs. Best GEO Agencies: How to Choose and What It Costs
Once you’ve decided to monitor AI responses seriously, the real question is who runs the program. Broadly, two paths exist: a self-serve platform your team operates, or one of the best GEO agencies handling it as a managed service.
Neither is universally right. The trade-off comes down to control, speed, and budget.
| Approach | Coverage and depth | Execution | Typical starting cost |
|---|---|---|---|
| Self-serve platform | You control prompts, platforms, and reporting cadence | Your team acts on insights directly | Often $99 to $200 per month |
| GEO agency | Strategy and reporting handled for you | Agency executes, slower feedback loop | Frequently several thousand per month |
A self-serve platform tends to suit in-house teams that want to own the data and move fast. An agency tends to suit brands that lack internal GEO capacity and prefer to outsource strategy, though it usually costs more and adds a layer between you and the dashboard. Several specialized monitoring platforms exist in this space, and a few agencies now offer GEO as a retainer service.
Topify covers both models. Its self-serve plans start at $99 per month for Basic and $199 for Pro, with Enterprise from $499. For teams that want execution done for them, Topify also runs a managed service from $3,999 per month that bundles prompt monitoring with content production. The practical takeaway: you can start small, validate the data against your own analytics, and scale into managed execution only once the value is clear.
Conclusion
The brand left off that ChatGPT list rarely knows it happened. That’s the real cost of flying blind in AI search, and it’s the problem an AI response monitoring service was built to solve. Monitoring isn’t the finish line, though. The teams that win treat it as the first step in a loop that ends with action.
Start with a baseline. Run a fixed set of customer-intent prompts across the major engines, measure where you stand on visibility, sentiment, and citations, then fix the weakest signal first. Get started with Topify to see your AI visibility baseline before your competitors widen the gap.
FAQ
Q: What is an AI response monitoring service in simple terms?
A: It’s a system that watches how AI engines like ChatGPT, Perplexity, and Google AI Overviews talk about your brand when people ask relevant questions. Instead of tracking page rankings, it tracks whether you’re mentioned, how you’re described, where you rank in the answer, and which sources the AI cites.
Q: How do you measure it, and what’s a basic checklist?
A: A solid checklist covers seven things: visibility, mentions, position, sentiment, share of voice, citation authority, and conversion likelihood. Run a fixed prompt set across multiple platforms on a weekly cadence, watch the mention-citation gap, and connect shifts to first-party referral data so you’re measuring outcomes, not isolated screenshots.
Q: What are some examples of AI response monitoring in practice?
A: Examples include tracking whether ChatGPT recommends you for “best tool for [use case],” checking how Perplexity describes your product’s positioning against a named competitor, and identifying which domains an answer engine cites when it leaves you out. Each example points to a specific content or authority fix.
Q: What does AI response monitoring service pricing usually look like?
A: Self-serve monitoring platforms typically run from around $99 to a few hundred dollars per month depending on prompt volume and seats. Managed services and GEO agencies generally cost several thousand per month, since they bundle strategy, content, and execution alongside the tracking.

