
Your SEO dashboard looks great. Keyword rankings are stable, impressions sit at an all-time high, and the monthly report practically writes itself. Yet qualified leads keep slipping, quarter after quarter. Then your CMO asks a question nobody in the room can answer: “If our SEO is this good, does ChatGPT actually recommend us when someone asks about our category?”
Silence.
Nothing in a traditional marketing stack measures what AI assistants say about your brand. The instinct is to blame an algorithm update or a soft market. In most cases the real cause is quieter: the recommendation layer of buying decisions has moved, and nobody was watching where it went.
What Is AI Recommendation Tracking and Why Brands Suddenly Need It
The shift is measurable. As of Q1 2026, visits to AI search and assistant tools grew 42.8% year over year, with query volume jumping from 15.6 billion to 27.4 billion. Around 37% of consumers now start their research and brand comparisons inside an AI tool instead of a search engine. On the commercial end, 64% of consumers plan to use AI chatbots as a primary shopping aid in 2026, and shoppers who’ve already tried AI-assisted buying have completed an average of $408 in purchases through it.
The behavioral pattern matters more than the raw numbers. Buyers increasingly ask an AI assistant to digest hundreds of reviews and spec sheets, then hand back a shortlist of two or three names. Traditional search gets demoted to a verification layer: people use it to find the pricing page of a brand the AI already picked. If you’re not in that shortlist, your SEO traffic pool never enters the conversation.
That’s the gap AI recommendation tracking exists to close.
AI recommendation tracking is the practice of continuously monitoring and quantifying how often your brand appears in the recommendation answers generated by AI assistants like ChatGPT, Perplexity, Gemini, and Google AI Overviews, plus where it ranks in those answers, how it’s described, and which sources the AI leaned on to say it.
It’s tempting to treat this as rank tracking with a new coat of paint. It isn’t. Rank tracking assumes a fixed SERP where position #3 means the same thing for every searcher. AI engines don’t have a SERP. Answers are generated on demand, shaped by conversation context and phrasing. The two systems have effectively decoupled: analysis of 2026 market data found only a 2.1% overlap between top-10 organic results and the sources ChatGPT actually cites in its answers. Even Google AI Overviews, which sits closest to traditional search, overlaps with top-10 organic rankings just 8.3% to 15.5% of the time.
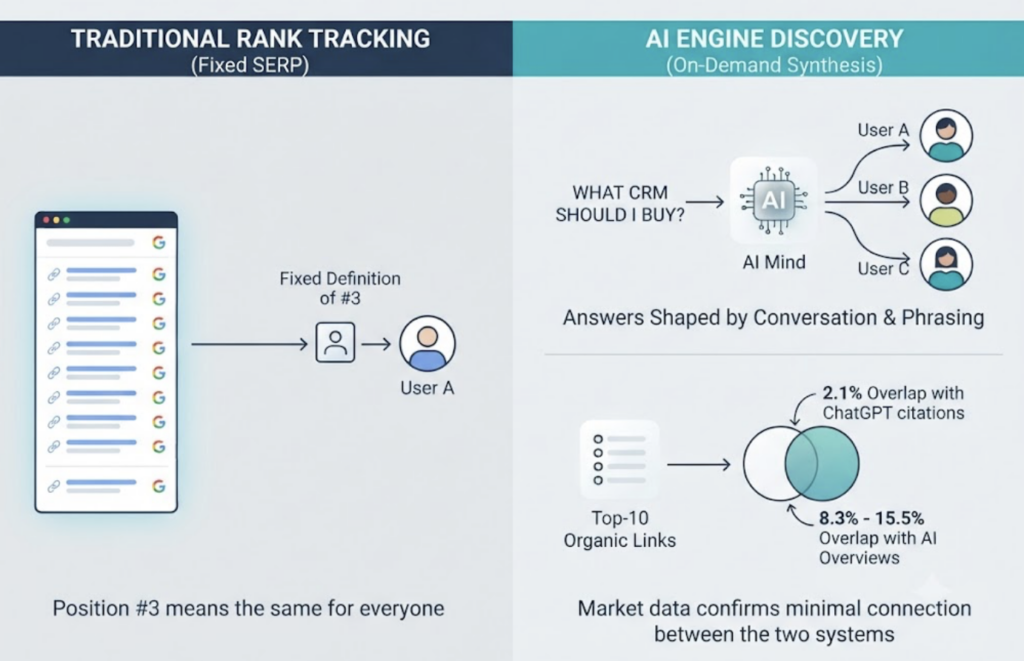
Bottom line: a #1 Google ranking tells you almost nothing about whether AI recommends you. You need a separate measurement system.
How AI Recommendation Tracking Works Under the Hood
Understanding how AI recommendation tracking works explains why manual spot checks fail. A production-grade tracking system runs a four-stage pipeline on a continuous loop.
Stage 1: Prompt sampling. Instead of short keywords, the system builds a prompt library that mirrors how real buyers actually ask. Not “CRM software,” but “What’s the best CRM for a European fintech startup that needs strict data compliance, and how does Brand A compare to Brand B?” A serious setup samples hundreds of these high-intent conversational prompts.
Stage 2: Multi-platform querying. The system pushes those prompts to every major AI engine on a schedule, under controlled conditions: normalized locations, cleared session memory, consistent configurations. Without that control, the data isn’t comparable across platforms or time.
Stage 3: Answer parsing. AI answers are unstructured text, so traditional crawlers are useless here. NLP and entity-disambiguation models extract four things from each answer: whether your brand was mentioned, where it appeared in the recommendation order, the sentiment and framing of the description, and which URLs the AI’s retrieval layer cited to justify the recommendation.
Stage 4: Aggregation over time. This is the step most teams skip, and it’s the one that makes the data trustworthy.
Here’s the thing: LLM output is non-deterministic. The same prompt asked Monday morning and Wednesday afternoon can return different brand lists, because models sample probabilistically and platforms retune their retrieval indexes constantly. In active commercial categories, the domains cited in AI answers drift 40% to 60% month over month. A single screenshot isn’t a data point. It’s survivorship bias with a timestamp.
Real visibility only emerges from repeated sampling and 7-day or 30-day rolling averages that smooth out the probabilistic noise.
The Metrics That Actually Matter in an AI Recommendation Tracking System
Raw parsed answers become useful only when they’re organized into metrics that answer a business question. If you’re figuring out how to measure AI recommendation tracking, this framework covers what to watch and what each signal actually tells you. It maps closely to the seven-metric system used by Topify, which tracks visibility, sentiment, position, volume, mentions, intent, and CVR in a single view.
| Metric | What to Look At | What It Explains |
|---|---|---|
| Visibility rate | % of tracked prompts where your brand appears | Whether you’re in the AI’s consideration set at all |
| Position | Where you rank within the recommendation order | Attention capture; first mentions absorb most of the trust |
| Sentiment and framing | How the AI describes you, scored 0-100 | Whether AI positioning matches your actual positioning |
| Citation sources | The URLs and domains the AI relied on | Your action map: which pages to fix or influence |
| Share of voice | Your mentions vs. competitors’ on the same prompts | Competitive standing, independent of category growth |
A few of these deserve unpacking.
Visibility rate is the entry ticket. A 2% score means that in 100 high-intent conversations about your category, you were absent from 98. Position determines whether presence converts: a brand mentioned first in the answer and a brand tacked onto the final “other options include” sentence both count as mentions, but only one of them influences the buying decision.
Sentiment catches a subtler failure mode. If AI recommends your enterprise-grade platform first but frames it as “a simple entry-level option for small teams,” you’ll attract the wrong leads and lose the right ones. Positioning drift is invisible without tracking.
Citation source analysis is where data turns into action. AI doesn’t prefer brands on a whim; it synthesizes from sources. If Perplexity keeps recommending your competitor because of one third-party review article, you now know exactly which URL to address.
Share of voice keeps you honest. In a category where AI mentions are growing across the board, your visibility can rise while your competitive position quietly erodes. If a rival’s SoV jumps from 35% to 50%, your improving absolute numbers are masking a loss.
Common Mistakes That Make AI Recommendation Tracking Data Useless
Teams that move early on AI tracking often burn budget on data that misleads more than it informs. Three mistakes account for most of the damage.
Mistake 1: Tracking only one AI platform. For many marketers, ChatGPT has become shorthand for AI search. The data says otherwise. When ChatGPT and Perplexity answer the same commercial question, their cited domains overlap just 11%. Each platform plays a structurally different game: Gemini cites brand-owned domains in 52.15% of its references, ChatGPT pulls 48.73% of citations from third-party directories, review roundups, and Wikipedia, and Perplexity averages nearly 22 citations per answer with a strong tilt toward expert analysis and communities like Reddit. Track only ChatGPT and you might conclude your official site content is worthless in AI search, then abandon the exact assets that win on Gemini and AI Overviews.

Mistake 2: Counting mentions while ignoring position and framing. Impressions-era thinking treats every mention as equal. In a linear AI answer, the brand dissected in the opening paragraph and the brand mentioned in a closing caveat (“Brand X also exists, though it lags on integrations”) get the same tally in a crude tracking tool. One is a recommendation. The other is reputational damage counted as a win.
Mistake 3: Treating a single query as a stable state. SEO habits die hard. A page that ranks #1 on Google tends to stay there for weeks, so teams assume one end-of-month AI check represents the month. It doesn’t. With citation drift running 40% to 60% monthly in active categories, the platform that recommends you first on Tuesday may omit you entirely on Thursday. Only automated, continuous sampling with rolling averages produces a trend line you can act on. A monthly snapshot can hide a visibility collapse for weeks.
Choosing an AI Recommendation Tracking Tool: What Separates Platforms
The market for AI recommendation tracking software has split into two tiers: tools that detect mentions, and platforms that explain them and help you act. Whether a given tool, platform, or dashboard deserves your budget comes down to four criteria: how many AI engines it covers, whether it tracks at the prompt level with real conversational queries, whether it benchmarks competitors dynamically, and whether it closes the loop from insight to content action.
Among dedicated AI recommendation tracking platforms, Topify is built around that full loop. It was developed by founding researchers from OpenAI alongside veteran Google SEO practitioners, and the pedigree shows in how it handles measurement.
On the core visibility and position tracking use case, Topify runs high-frequency concurrent queries across ChatGPT, Gemini, Perplexity, DeepSeek, and Google AI Overviews, measuring whether your brand lands the lead recommendation or gets buried at the end of the list for real buyer-intent prompts. The dashboard converts volatile generated answers into smoothed rolling averages and a 0-100 sentiment score, so a marketing team can spot the business impact of a model update without needing a data scientist to interpret it.
What separates it from detection-only tools is the pairing of Competitor Benchmarking with Source Analysis. The platform doesn’t just report that you’re missing from a high-value prompt; it identifies which competitor took that slot and reverse-engineers which specific review article, wiki page, or forum thread the AI weighted to make that call. That turns tracking output into a concrete task list: which URL to update, which citation gap to fill. There’s also an agent-driven execution layer that generates LLM-optimized structured content from those findings, so analysis and action live in one system rather than three tools and a spreadsheet.
On pricing, basic mention-monitoring tools cluster around a $79 median, while deep-audit platforms run into the hundreds or thousands per month. Topify’s pricing starts at $99/month for the Basic plan, which covers 100 tracked prompts across platforms with full sentiment and source analysis, and $199/month for Pro with 250 prompts and multi-project support for teams and agencies. For a system that includes the execution layer, that lands on the affordable end of the category.
Other tools serve narrower needs. Semrush offers basic AI Overviews detection for teams still centered on traditional search. ZipTie specializes in fine-grained citation auditing. Profound targets large regulated enterprises with compliance-integrated setups. For most B2B and B2C marketing teams that need both insight depth and execution, a purpose-built closed-loop GEO platform is the more practical solution.
Building Your AI Recommendation Tracking Strategy in Four Steps
A tool without a framework produces dashboards, not growth. This four-step sequence doubles as a working checklist for building a durable AI recommendation tracking strategy.
Step 1: Define a buyer-intent prompt set. Drop the keyword list. Build an initial library of 50 to 100 prompts written the way buyers actually talk, weighted toward mid-funnel and bottom-funnel intent: category exploration (“best cloud ERP for mid-size precision manufacturers”), pain-driven consideration (“which database architecture handles Black Friday traffic spikes”), and direct comparison (“your brand vs. competitor on API quality, pricing, and support”). High-intent prompts are what connect tracking data to revenue.
Step 2: Establish a baseline and tolerate the noise. For the first 30 days, resist the urge to change anything. Let the system sample continuously across platforms and record visibility, position, and sentiment. The rolling average at day 30 is your baseline snapshot, and it becomes the yardstick for every optimization ROI calculation that follows. You can’t improve a number you never measured cleanly.
Step 3: Run gap analysis and source attribution. Find the dead prompts: high-volume, high-intent questions where you’re invisible. Use competitor benchmarking to see who owns those slots, then use source analysis to learn why. Is the competitor’s site serving clean FAQ structure and Schema markup that AI can parse? Did one authoritative third-party comparison swing the model’s judgment? Turn the findings into a prioritized fix list.
Step 4: Execute and close the loop. Restructure existing high-authority pages before writing new ones: add JSON-LD Schema (FAQPage, Product, Organization), reorganize content into direct question-and-answer heading structures, and convert vague promotional copy into extractable bullet points and tables. Reinforce entity signals on the third-party domains AI actually cites. Then keep watching the metrics. The results can move fast: one B2B SaaS company lifted its AI visibility score from 12 to 50 within six weeks of adding structured data and AI-parseable formatting, a 317% gain. A fintech startup grew its category share of voice 3.1x in eight weeks by building out a structured knowledge hub.
Track, diagnose, fix, verify. Then repeat.
Conclusion
The uncomfortable answer to that CMO question is that most brands genuinely don’t know whether AI recommends them, because nothing in their stack was built to check. Meanwhile 37% of consumers have already moved their research and comparison behavior into AI tools, and the shortlists those tools produce are deciding deals before your website ever loads.
You can’t optimize what you can’t measure. Stop spot-checking ChatGPT for reassurance. Define a high-intent prompt library, set up systematic tracking, build a 30-day baseline, and let source-level data tell you exactly where to act. The brands that map their position in AI answers now will be the ones the next wave of buyers actually sees.
FAQ
Q1: What is AI recommendation tracking?
A: AI recommendation tracking is the ongoing monitoring of how AI assistants like ChatGPT, Gemini, Perplexity, and Google AI Overviews mention and recommend your brand in generated answers. It measures appearance frequency, recommendation position, sentiment, and the sources behind each recommendation. Unlike SEO rank tracking, it monitors dynamically generated conversational answers rather than fixed search result pages.
Q2: How much does AI recommendation tracking cost?
A: Pricing depends on prompt capacity, platform coverage, and analysis depth. Basic mention-monitoring tools cluster around $79/month, while mid-tier systems with competitor benchmarking and citation analysis typically run $79 to $149. Topify’s Basic plan is $99/month with cross-platform tracking and source analysis, and Pro is $199/month with 250 prompts and multi-project support.
Q3: How often should you check AI recommendations?
A: Continuously, not monthly. AI answers are non-deterministic, and cited domains in active categories drift 40% to 60% per month. Best practice is automated daily or high-frequency sampling with 7-day or 30-day rolling averages, which filters probabilistic noise and produces a trend you can actually act on.
Q4: Can you track AI recommendations manually?
A: Not reliably. Manual checks can’t sample across platforms at scale, can’t neutralize the randomness in model outputs, can’t parse sentiment and citations from large volumes of text, and can’t build a baseline over time. Individual queries carry heavy survivorship bias, which makes them risky inputs for business decisions. Dedicated tracking software is the only way to get statistically meaningful data.

