
Your organic traffic report looks stable, but your pipeline doesn’t. Somewhere between the query and the click, a growing share of your buyers now ask ChatGPT or Perplexity for a shortlist, get an answer, and never open Google at all. Traditional analytics can only count the visitors who arrived. It says nothing about the deals you lost because an AI model recommended someone else. That blind spot is exactly what AI recommendation tracking analytics exists to close: measuring who AI engines recommend, why they recommend them, and how often your brand makes the cut.
What AI Recommendation Tracking Analytics Actually Measures
Start with the definition. An AI recommendation tracking solution is an analytics system that monitors how large language models mention, rank, describe, and cite your brand inside their generated answers. Coverage typically spans conversational AI like ChatGPT and Claude, retrieval-first engines like Perplexity, and Google’s AI Overviews and Gemini.
The difference from traditional rank tracking isn’t cosmetic. It’s structural.
Classic SEO tracking assumes a deterministic system: one query, one fixed SERP, ten blue links, the same list for everyone. AI engines don’t work that way. Every prompt triggers retrieval-augmented generation that synthesizes a unique answer from multiple sources, in real time, with probabilistic variation between runs. There’s no fixed page to scrape. That’s why a brand can rank #1 on Google for its category and still be completely invisible when ChatGPT assembles a buying recommendation.
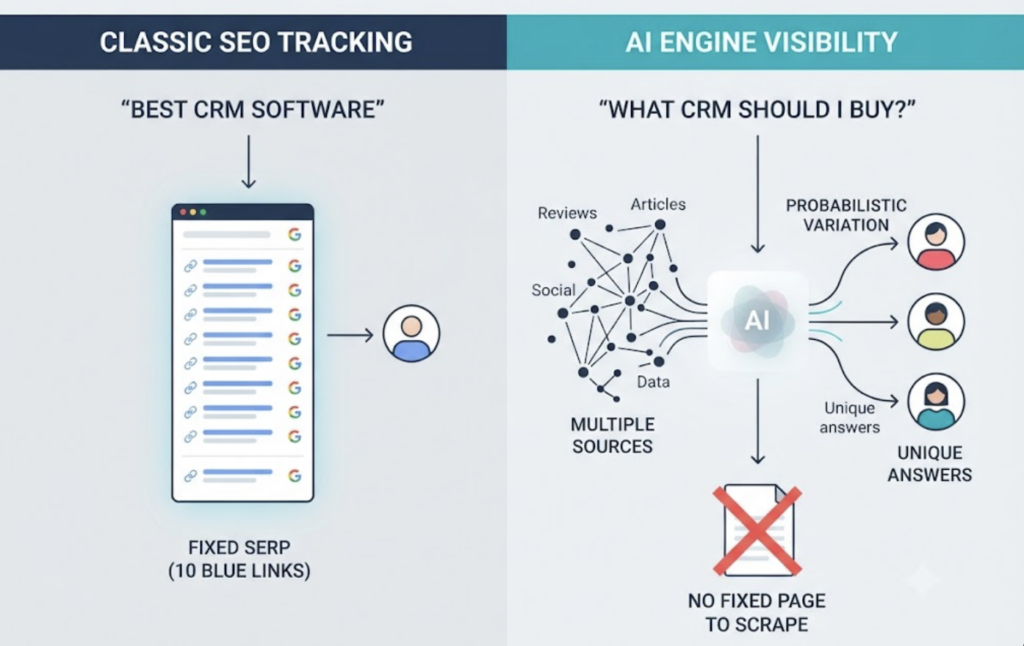
What gets measured also changes. AI recommendation tracking analytics doesn’t ask “what position do you hold in a list.” It asks “does the model consider your brand authoritative enough to include in its synthesized answer at all.”
The stakes have moved fast. ChatGPT reached roughly 900 million weekly active users by February 2026, making it the fastest consumer app in history to approach the billion-user scale, with adoption among users over 35 climbing sharply into business purchasing contexts. The commercial signal is even sharper: during the late-2025 retail season, AI-driven referral traffic grew 693% year over year, and those visitors converted at rates 31% higher than non-AI traffic.
If your brand isn’t being tracked in this layer, you’re not measuring a channel. You’re missing one.
How AI Recommendation Tracking Works Behind the Scenes
So how does an AI recommendation tracking solution work in practice? Modern platforms decompose the AI black box through four connected stages.
Stage 1: Prompt sampling. Instead of short-tail keywords, the system builds a portfolio of natural-language prompts that mirror real buyer intent, like “What’s the most reliable ERP system for a mid-market B2B manufacturer?” These are the queries that actually trigger a model’s recommendation logic.
Stage 2: Cross-platform polling. The same prompt set is fired concurrently at multiple AI engines. This matters because the platforms retrieve differently: ChatGPT and Claude lean on parametric knowledge plus specific retrieval APIs, Gemini is wired into Google’s knowledge graph, and Perplexity runs a citation-forward RAG pipeline. The same question routinely returns different brand shortlists on different engines.
Stage 3: Answer parsing. NLP modules extract structured data from each unstructured response: whether the brand was mentioned, where it sat in the recommendation order, what sentiment the model attached to it, and whether the answer included a live citation link to the brand’s own site.
Stage 4: Time-series aggregation. Single data points get placed on a longitudinal timeline, so teams see week-over-week visibility shifts, citation retention, and share-of-voice trends instead of isolated snapshots.
That last stage exists because of one uncomfortable fact: LLM output is volatile by design. Temperature settings mean two identical prompts can produce different wording and different supporting sources. In competitive commercial categories, 40% to 70% of AI citation sources rotate within a single week, a pattern practitioners call citation drift.
One screenshot is not data. It’s a lottery ticket. Only high-frequency, large-sample polling can turn probabilistic answers into a reliable measure of how often your brand is actually the recommended choice.
The Metrics That Separate Real Analytics from Vanity Dashboards
Counting raw brand mentions with a social listening tool feels like progress. In practice, it’s the fastest way to build a vanity dashboard. Measuring an AI recommendation tracking solution properly requires seven distinct signals.
| Metric | What it measures | Why it matters |
|---|---|---|
| Visibility Rate | Probability your brand appears in AI answers for a defined prompt set | Determines whether you’ve entered the model’s consideration set at all |
| Mention Frequency | Absolute volume of brand mentions across platforms and contexts | Baseline of your digital footprint; signals entity strength |
| Position | Whether you appear in the lead recommendation or a footnote | In zero-click answers, position decides whose message gets absorbed |
| Sentiment | The polarity of how the model describes you | A negative mention isn’t visibility, it’s a PR problem at scale |
| Citation Share | Whether the AI links to your owned assets as a source | Linked citations drive traffic and mark genuine entity trust |
| Prompt Volume | How often a given question is actually asked on AI platforms | Directs optimization budget toward the highest-value intents |
| CVR | Downstream conversion of AI-referred visitors | Closes the loop between generative exposure and revenue |
The conversion metric deserves attention. Visitors arriving from AI search tools tend to spend 45% to 68% longer on site than traditional search visitors, which is why treating this traffic as a rounding error understates its pipeline contribution.
Turning seven metrics into one operational dashboard is where most teams stall. This is the specific problem Topify was built for: its Comprehensive GEO Analytics layer tracks all seven dimensions in a single view, so a drop in ChatGPT visibility can be traced to a shift in sentiment, position, or a lost citation source without stitching together three separate tools.
A Strategy That Improves the Numbers, Not Just Reports Them
A tracking platform that only produces reports manufactures anxiety. A useful strategy for an AI recommendation tracking solution converts monitoring into a repeatable optimization loop with four steps.
Find the citation gap. Use source analysis to see which URLs the AI actually retrieved when it recommended your competitor: a data-heavy whitepaper, a high-authority review directory, a two-year-old industry report.
Target high-value prompts. Surface queries with strong commercial intent where your visibility is low, and hand them to the content team as named objectives.
Rebuild the cited content. Restructure pages the way generative engines prefer: dense verifiable facts, machine-readable schema, answer-first definitions near the top of the page.
Re-poll and verify. Push updates live, let the platform re-test at high frequency, and confirm whether Citation Share and Visibility Rate actually inflect.
This isn’t guesswork. The GEO benchmark study from Princeton, Georgia Tech, and the Allen Institute for AI (Aggarwal et al., KDD 2024) tested optimization tactics across 10,000 queries in 9 domains. Adding concrete statistics lifted content visibility in AI answers by up to 40%, citing authoritative sources produced similar gains, and adding expert quotations delivered up to 35%. The same research found that keyword stuffing without substance did nothing, and often got content down-weighted.
Here’s what the loop looks like in the wild. A B2B logistics SaaS provider was spending $10,000 a month on link building and blog volume while its lead quality collapsed, because its buyers had moved their vendor research to Perplexity. Tracking data showed zero visibility on its core “best logistics API” prompt, with AI answers repeatedly citing an outdated third-party report. The team cut $6,000 of low-value link spend, converted broad blog posts into fact-dense technical whitepapers, added a structured JSON pricing feed, and placed 40-to-60-word answer-first product definitions in the top third of key pages. Within a quarter, its Citation Share on Perplexity went from zero to the #1 recommended position, and cost per demo request fell 35%.
The pattern generalizes: track, diagnose the source layer, rebuild for fact density, re-measure.
Common Mistakes That Quietly Corrupt Your Tracking Data
Most tracking failures aren’t tooling failures. They’re inherited habits from the SEO era. These five common mistakes in AI recommendation tracking solution rollouts distort data badly enough to misdirect budget.
| Mistake | What goes wrong | What the data actually shows |
|---|---|---|
| Single-platform blindness | Testing only ChatGPT and treating it as the market | ChatGPT’s share of B2B AI referral traffic fell from 89.1% to 62.6% by early 2026, while Claude reached 18.5%, Gemini 10.6%, and Perplexity 7.3%. Poll across platforms or measure a shrinking slice. |
| The snapshot fallacy | One manual test on a Monday afternoon becomes “our AI ranking” | With 40%+ of citations rotating within weeks, single samples are statistical noise. Only time-series aggregation produces a real baseline. |
| Mention-only reporting | Celebrating 50 mentions without reading them | “Brand A is overpriced and unreliable, so we recommend Brand B” counts as a mention. Without Sentiment and Position, mention counts are worthless. |
| Ignoring the citation source layer | Watching final answers, never the URLs behind them | Roughly 86% of AI citations come from assets brands can control or influence. Skipping source tracking means abandoning the optimization lever entirely. |
| Static prompt sets | Porting 1-2 word SEO keywords straight into the tracker | Real AI queries run 15 to 30 words with heavy context. Short-tail prompts measure a conversation your buyers aren’t having. |
The unifying theme: AI tracking is a probability discipline, not a ranking discipline. Teams that treat it like SERP monitoring end up optimizing against fiction.
Choosing the Best Tool for Search Visibility in the AI Era
Once the discipline is clear, the selection question gets sharper. Finding the best tool for search visibility today means testing whether a platform’s underlying architecture was actually built for generative engines, or whether an AI tab was bolted onto a web crawler.
| Evaluation dimension | Traditional SEO tools like Semrush, Ahrefs | Modern GEO platforms like Topify |
|---|---|---|
| Model coverage | Mostly limited to AI Overviews inside Google, plus rough web mention scans | ChatGPT, Gemini, Perplexity, Claude, DeepSeek, Qwen, Doubao, and other major engines |
| Metric depth | Static keyword rankings and basic mention counts from SERP scraping | Synthetic LLM probing that quantifies all seven GEO metrics, including sentiment and CVR |
| Source analysis | Backlink counting; can’t explain why an AI retrieved a passage | Reverse-engineers the exact URLs, entities, and data blocks that triggered a recommendation |
| Competitor benchmarking | Domain-level traffic share comparisons | Prompt-level Share of Voice showing your recommendation frequency against named rivals |
| Execution loop | Stops at reports; optimization is fully manual | AI Agent-driven One-Click Execution from diagnosis to deployed fix |
| Underlying model | Historical crawl snapshots | Continuous, compute-driven live querying of the models themselves |
Semrush and Ahrefs still earn their keep for classic Google work: backlink profiles, technical audits, keyword research at scale. The structural problem is that crawl-based architectures can’t see inside closed generative engines, and answers that are synthesized fresh on every request leave nothing static to crawl.
For teams whose priority is the AI recommendation layer specifically, Topify tends to be the strongest fit in this comparison. Its probing approach reaches the citation-evaluation behavior inside engines like ChatGPT and Perplexity rather than inferring it from the open web. And its One-Click Execution collapses the usual weeks-long cycle of audit, content brief, and rollout into a reviewable automated loop, which is the difference between a dashboard and an operating system for AI visibility.
A Buyer’s Checklist Before You Pay for Any Platform
Demand for AI tracking has flooded the market with repackaged crawlers. Before signing an annual contract, run this checklist for an AI recommendation tracking solution during the demo, item by item.
| Stage | Checklist item |
|---|---|
| Baseline | 1. Can you run an initial GEO readiness diagnosis on your URL before paying? |
| Baseline | 2. Is the prompt quota large enough to cover your category’s core buying queries? |
| Baseline | 3. Can one task poll ChatGPT, Gemini, Perplexity, and Claude in parallel? |
| Data depth | 4. Does the parser strictly separate plain-text mentions from linked citations? |
| Data depth | 5. Is there built-in NLP sentiment detection for positive, neutral, and negative framing? |
| Data depth | 6. Can you add named competitors and watch Share of Voice trends over time? |
| Execution | 7. When a citation is lost, does the system explain why, or just raise an alert? |
| Execution | 8. Can the dashboard surface citation drift across long observation windows? |
| Execution | 9. Are AI traffic reports separable from traditional SEO data for clean attribution? |
Pricing structure is the tenth, unwritten check, because it reveals whether the technology is real. Agencies selling GEO on a labor model bill by the hour, the backlink, or the word count. Genuine tracking platforms carry a different cost base: they burn tokens running synthetic probes against LLM APIs at scale, so honest pricing is usage-based SaaS tied to prompt capacity.
That shift has kept entry costs low. Topify’s pricing starts at $99/month on the Basic plan, which covers continuous monitoring across ChatGPT, Perplexity, and AI Overviews with 100 tracked prompts, a 30-day trial included. Teams that validate ROI typically scale to Pro at $199/month for 250 prompts, while Enterprise plans from $499/month add dedicated support and custom volume. Cost grows with usage, not with headcount.
Conclusion
Back to the conflict this article opened with: your organic demand didn’t evaporate. It relocated into synthesized AI answers, where an invisible recommendation layer is already steering B2B budgets and consumer purchases before a single click reaches your site. Holding onto rank-tracking habits in that environment means volunteering to disappear from the map.
The rational first move isn’t a content sprint. It’s a baseline. Start with a small set of your highest-intent commercial prompts, track them across engines for a few weeks, and let the data show you where the citation gaps actually are. Then pick a platform that can see the source layer and close the loop from insight to execution. You can start that first cross-engine visibility assessment today and know exactly where your brand stands before the next model update reshuffles the answers.
FAQ
Q1: What is an AI recommendation tracking solution? A: It’s a business intelligence system that tracks how generative AI platforms like ChatGPT, Gemini, and Perplexity mention, cite, and recommend your brand inside their synthesized answers. Unlike rank trackers that monitor fixed URL positions, it measures whether your brand enters the model’s live consideration set, what position and sentiment it receives, and whether the AI links back to your assets.
Q2: How does an AI recommendation tracking solution work?
A: Through synthetic probing. The system sends a portfolio of high-intent, long-form prompts to multiple AI platforms at high frequency, parses the unstructured responses with NLP to extract mentions, citations, sentiment, and position, then aggregates everything into time series. The aggregation step cancels out the natural randomness of LLM output and produces reliable visibility trends.
Q3: How much does an AI recommendation tracking solution cost?
A: Because the cost driver is LLM compute rather than labor hours, most platforms use transparent usage-based SaaS pricing. Entry plans such as Topify Basic start around $99/month, mid-tier plans with larger prompt capacity run about $199/month, and enterprise plans with high-volume polling and dedicated support typically start from $499/month.
Q4: What are examples of AI recommendation tracking in practice?
A: A common pattern: a software company tracks 50 “best tool in category” prompts weekly across engines and discovers it ranks well on Google but is never cited on Perplexity. Source analysis shows Perplexity favors a third-party review site with detailed comparison data. The team updates that authoritative source and adds structured, answer-first benchmark data to its own pages, then confirms in the next tracking cycle that it has become the top recommendation, with lead acquisition costs falling as high-intent AI referrals grow.

