
Your team spent a year building content, earning links, and climbing Google rankings. Then a buyer in your category opened ChatGPT and asked for the best option. The model named five brands. Yours wasn’t one of them. Nothing in your SEO dashboard explained why, because those metrics were never built to measure what an AI decides to say out loud. That blind spot has a name, and closing it starts with knowing what’s being said in the first place.
What AI Recommendation Tracking Actually Means
AI recommendation tracking is the systematic process of monitoring how AI-powered search engines represent your brand when someone asks for a product or service suggestion. It’s less about where a page ranks, and more about whether the model names you at all.
Traditional SEO tracks the position of a specific URL on a results page. Recommendation tracking watches the synthesized answer an LLM generates, and asks one question: did your brand make the shortlist?
That distinction matters more than it sounds. A top-three Google ranking doesn’t guarantee a single mention inside a ChatGPT answer. The two systems retrieve and prioritize information in different ways.
This work sits under Generative Engine Optimization, or GEO. AI models pull live web data through a Retrieval-Augmented Generation (RAG) pipeline, then condense it into a short, ranked set of recommendations. If your brand isn’t in the retrieved set, it can’t be recommended. There’s no second page to scroll to.
That’s the gap most brands still can’t see.
How Does AI Recommendation Tracking Work
AI systems are non-deterministic. Ask the same question twice and the wording, order, and even the names can shift. So tracking can’t be a one-time check. It has to be a repeatable measurement discipline.
In practice, a working setup runs through four steps.
First, a prompt repository. You curate a set of high-intent, category-defining questions a real buyer would ask, like “What’s the best CRM for a small business?” or “Which project management tool works for remote teams?” These prompts become your measurement baseline.
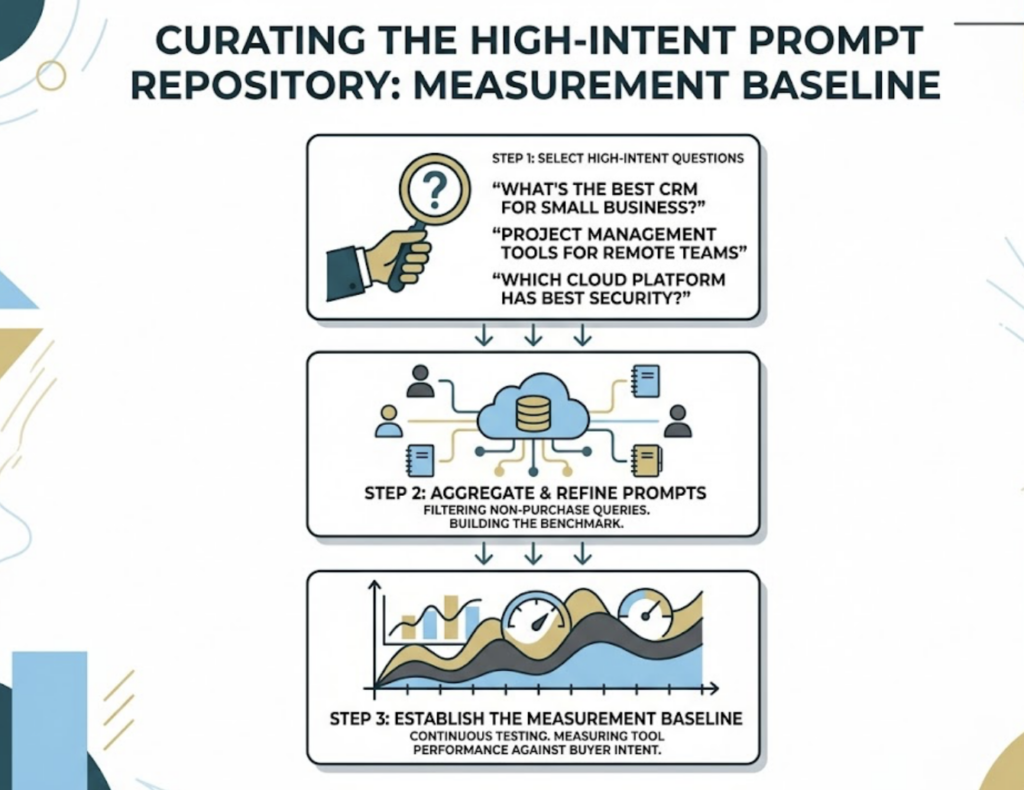
Second, cross-platform probing. The same prompts run across ChatGPT, Perplexity, Gemini, and Google AI Overviews. Each engine retrieves and ranks sources differently, so a brand that dominates one can be absent on another.
Third, cyclical sampling. Because responses drift with model updates and changing retrieval results, a single snapshot is close to useless. Running the prompt set weekly builds a stable visibility baseline instead of a lucky guess.
Fourth, semantic parsing. Automated systems read each answer and pull out the structured signals: whether your brand was mentioned, where it sat in the list, how it was described, and which source the model cited.
Here’s a concrete version. A team tracks 200 prompts across four AI platforms, sampled weekly for 30 days. By the end, they don’t have an opinion about their AI presence. They have a measured rate, a position trend, and a list of the exact pages the models keep citing instead of theirs.
How to Measure AI Recommendation Tracking
Knowing you’re “sometimes mentioned” isn’t a metric. To report on AI presence with any credibility, you need a defined framework. Most mature programs track five signals.
| Metric | What It Tells You |
|---|---|
| Visibility (mention) rate | Share of prompts where your brand appears at all. Your top-of-funnel presence. |
| Position / share of voice | Where you land in the recommendation list, relative to competitors. |
| Citation share | How often the model links directly to your domain. A proxy for source authority. |
| Sentiment accuracy | The tone and framing used when your brand is named. |
| Conversion rate (CVR) | How AI-referred traffic converts compared to traditional search traffic. |
Each metric answers a different question, and skipping any one leaves a blind spot. Visibility without position tells you that you exist, not whether you’re the first name a buyer sees. Citation share without sentiment tells you the model links to you, not whether it’s describing you the way you want.
This is also where ai-powered brand visibility tracking tools earn their place. Pulling these five signals by hand, across four platforms, every week, isn’t realistic. Automation is what turns scattered observations into a baseline you can actually trend over time.
How to Improve AI Recommendation Tracking and Avoid Common Mistakes
Measurement tells you where you stand. Improving the result is a separate discipline, and it tends to come down to making your brand easy for a model to retrieve, trust, and quote.
A few practices do most of the work.
Entity optimization. AI engines favor brands that are legible to a machine. Consistent factual claims across the web, clean product data, and structured Schema markup help a model anchor a recommendation to you rather than guess.
Expertise-first content. Models reward signals of experience, authority, and trust. Original research, clear methodology, and named expert bios make a page more likely to be cited than generic marketing copy.
Answer-first formatting. Direct Q&A blocks, FAQs, and short summaries are easier for a model to extract. Content it can lift cleanly is content it’s more likely to surface.
Now the mistakes. Most teams lose visibility not from doing nothing, but from measuring the wrong way.
- Single-platform bias. Assuming a strong ChatGPT showing means you’re visible everywhere. Each engine runs a different RAG mechanism.
- Snapshot reliance. Testing once a month and treating it as truth, despite how much responses fluctuate week to week.
- Ignoring sentiment. Being mentioned, but framed as the “legacy” or “budget” option. Presence isn’t the same as a good recommendation.
- Neglecting source authority. Chasing mentions while giving the model nothing citable to point at.
If you want a quick self-check, run this list before your next review: Are you tracking more than one AI platform? Are you sampling on a schedule, not once? Are you watching position, not just mentions? Are you reading sentiment, not assuming it’s neutral? Do you know which pages get cited in your category? Five yeses is a healthy program. Anything less is a gap worth closing.
AI-Powered Brand Visibility Tracking Tools: What to Look For
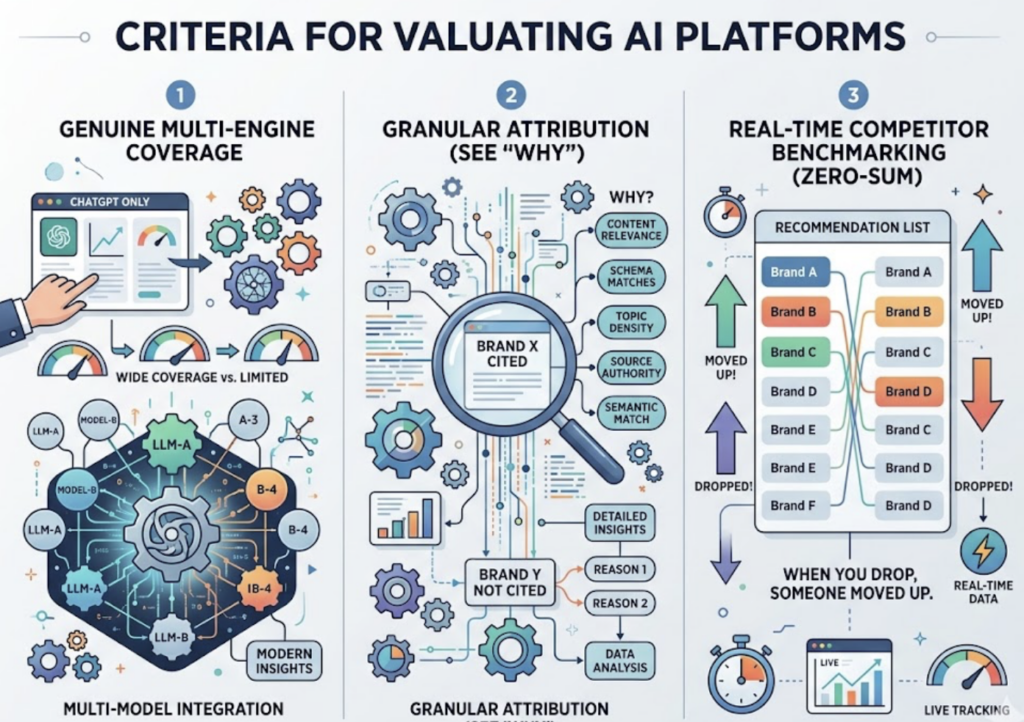
The market for AI visibility tools is filling up fast, and most of them measure a slice of the picture. The best tools for AI recommendation tracking share a few non-negotiable traits.
Look for genuine multi-engine coverage, not a ChatGPT-only dashboard wearing a broader label. Look for granular attribution, so you can see why a brand was or wasn’t cited, down to content relevance and schema matches. And look for real-time competitor benchmarking, because a recommendation list is zero-sum: when you drop, someone else moved up.
For teams that want these signals in one view, Topify tends to stand out by consolidating Visibility, Position, Sentiment, and Citation Share rather than reporting them in separate silos. In practice, that means you can catch a drop in your ChatGPT mention rate, trace it to a competitor that replaced you in the answer, and see which source the model cited instead, all in the same place.
Topify’s team frames that last pattern as a “Displacement Event,” the moment a rival takes your slot in an AI response. Competitor Monitoring surfaces it in real time, Source Analysis shows the citation that anchored the swap, and Position Tracking confirms how far you slid. That’s the difference between knowing your number went down and knowing what to do about it.
Pricing follows usage rather than inflated enterprise bundles, which makes it realistic to start small and expand as the data proves out. If you want to set a baseline this week, you can get started with Topify and run your first prompt set across multiple engines before your next reporting cycle.
Conclusion
AI recommendation tracking has moved from a nice-to-have SEO add-on to a basic requirement for staying visible in a generative-first web. The buyers asking ChatGPT and Perplexity for a recommendation aren’t waiting for your rankings to catch up. The practical first step is small: build a prompt repository for your category, pick a tool that covers more than one platform and more than one metric, and measure a baseline. Once you can see what AI is saying, you can finally do something about it.
FAQ
Q: What is AI recommendation tracking in simple terms?
A: It’s monitoring whether and how AI search engines name your brand when a user asks for a recommendation. Instead of tracking a page’s rank, you track whether the model includes you in its synthesized shortlist, where you land in that list, and how it describes you.
Q: How does AI recommendation tracking work across different platforms?
A: You run a fixed set of high-intent prompts across engines like ChatGPT, Perplexity, Gemini, and Google AI Overviews, then sample them on a schedule because responses shift over time. Automated parsing extracts your mentions, position, sentiment, and citations from each answer so you can compare platforms side by side.
Q: What does AI recommendation tracking pricing typically look like?
A: It usually scales with how many prompts and platforms you monitor. Topify’s plans start around $99 per month for tracking across ChatGPT, Perplexity, and AI Overviews, with a Pro tier near $199 and Enterprise from roughly $499, so smaller teams can start lean and expand as value becomes clear. You can review the current tiers on the Topify pricing page.
Q: What are some examples of AI recommendation tracking in practice?
A: A common example is tracking a prompt like “best [your category] tool” across four AI platforms, weekly, for 30 days. The output shows your mention rate, your average position versus competitors, and which sources the models cite, which together reveal exactly where to focus content and citation efforts.

