
Your weekly report says “AI rank: #3.” Last week it said #5. Your VP asks the obvious question: what did we do right?
You don’t have an answer. Not because you didn’t do the work, but because the AI rank checker that produced the number can’t tell you which prompts it tested, how often it sampled, or why the position moved. The number exists. Its meaning doesn’t.
This isn’t a tooling inconvenience. It’s a measurement model imported from a world that no longer applies. Here’s why the single-score approach breaks down in AI search, and what a rank actually needs to include before you can act on it.
The Number on Your AI Rank Checker Dashboard Is an Average of Averages
Traditional rank trackers were built for a deterministic system. Google returned ten blue links, your URL sat in one position, and that position was defensible and repeatable. Ask again tomorrow, get roughly the same answer.
AI search doesn’t work like that. Large language models are probabilistic systems built on retrieval-augmented generation. Temperature settings, parallel GPU processing, and real-time index refreshes mean the same prompt can produce different answers within the same hour. Research from Equal Experts on LLM non-determinism confirms what anyone who’s re-run a ChatGPT query already suspects: generation isn’t exactly reproducible, by design.
The instability runs deeper than answer wording. According to a 2026 Digital Authority Partners analysis, only 10.6% of URLs cited by AI engines persist across a 28-day window. Put differently, 89% of AI visibility wins are gone within a month. Citation behavior is a flow, not a stock.
Now consider what most AI rank checkers do with that volatility. They query a small, static set of prompts, at a handful of sampling times, on one or two platforms. Then they compress everything into a single number.
That number is noise wearing the costume of a metric.
A “rank #3” snapshot can convince a team they’re winning while the brand is absent from 80% of relevant variations of the same query. The tool isn’t lying. It’s just answering a question nobody should be asking: “where did we rank in one sample, at one moment, on one phrasing?”
Ranking Position and Getting Mentioned Are Two Different Games
Here’s the structural shift most rank trackers miss entirely. In traditional SEO, ranking and visibility were the same thing: if you weren’t in the top 10, you were invisible. In AI search, they’ve split into two separate questions.
The first question is whether you appear at all. Mention rate, the percentage of relevant prompts where AI names your brand, is the gating metric. The second question is where you appear when you do. Position only matters after inclusion is solved.
A single rank score collapses these into one number, and the collapse hides the failure mode that matters most. A brand can hold “position #2” on the three prompts a tool happens to test while being completely absent from the dozens of adjacent prompts real buyers actually ask.
There’s a second split hiding inside the first: mentioned is not the same as cited. Yext’s research across 17.2 million citations shows AI engines treat naming a brand in text and linking to it as a source as distinct behaviors. An AI answer can rank your brand #2 in a listicle-style response without citing your website once. If the goal is traffic or authority signals, that’s a zero-click event your rank checker records as a win.
Track it. Decompose it. Then decide what to fix.
Three Things a Single Score Can’t Tell You
Even a statistically clean score would still be an abstraction. Three performance drivers disappear inside it.
Which prompts the number came from
Appearing first for 100 low-intent research queries is mathematically great for a rank checker and commercially worthless for you. Prompt intent isn’t a nuance here, it’s the whole game.
Research on citation stability shows the pattern clearly. Discovery prompts carry the highest volatility, because AI engines experiment with options. Comparison prompts are more stable, since AI leans on structured comparison data. Validation prompts are the harshest of all: AI prioritizes proven, authoritative, fact-checked sources when a user is confirming a decision.
The strategic implication is uncomfortable. A brand can post a strong average rank built entirely on volatile discovery prompts while failing to appear in the validation prompts where purchase decisions actually get made. The dashboard shows green. The pipeline shows nothing.
Why the number moved
A score change is an effect, not a cause. When an AI engine drops your brand, it’s typically because it found a fresher or more authoritative source for the same claim. The cause lives in the citation layer: which domains the AI pulls from, and whether yours got displaced.
Rank checkers report the score changed. They rarely tell you the source was overtaken. Without source attribution, every fluctuation triggers the same unproductive ritual: someone asks why, nobody knows, everyone waits to see if next week’s number recovers on its own.
How AI describes you when it does mention you
Position captures where you appear. It says nothing about the frame. An AI answer can rank your product #1 while describing it as “a low-cost budget alternative,” which is a quiet disaster if you’ve spent two years positioning as enterprise-grade.
This narrative layer, what some researchers call the brand’s narrative footprint, is invisible to any tool that reduces AI presence to a coordinate. Sentiment and framing determine whether a mention builds your positioning or erodes it.
What a Meaningful AI Rank Actually Requires
Strip away the single-score abstraction and a workable measurement framework has five requirements. None of them is exotic. All of them are absent from most AI rank checkers.
| Requirement | What it means in practice | What the single score hides |
|---|---|---|
| Prompt-level granularity | Every data point traces to a specific, visible prompt | Whether the prompts tested carry any buyer intent |
| Mention rate before position | Inclusion tracked separately from ordering | Absence across the majority of relevant prompts |
| Longitudinal sampling | Repeated tests that smooth out non-determinism | Whether a rank is signal or single-sample noise |
| Citation source attribution | Which domains the AI cites, and when yours is displaced | The cause behind every score movement |
| Sentiment and framing | How the AI characterizes the brand in each answer | Narrative drift that contradicts your positioning |
Add one more dimension across all five: platform heterogeneity. ChatGPT, Perplexity, Gemini, and Google AI Overviews cite differently and rarely agree. A number averaged across platforms, or worse, sampled from just one, tells you almost nothing about the others.
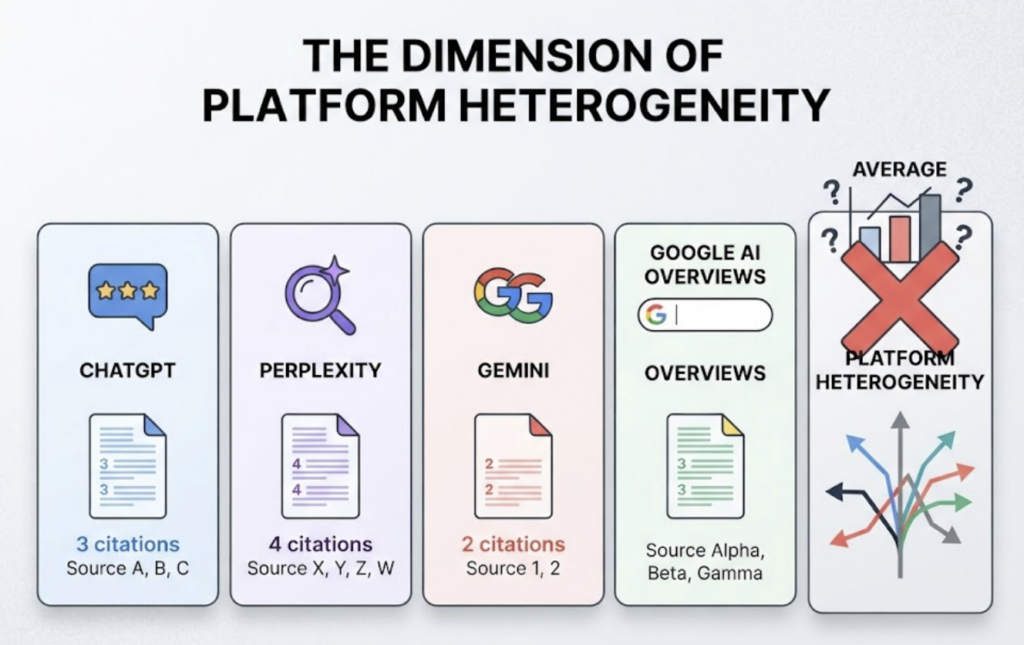
This is the bar. A tool that clears it gives you answerable questions instead of a floating number.
How Topify Turns a Meaningless Number into Seven Answerable Questions
Once you’ve accepted that “rank” needs to be decomposed, the practical question is what to decompose it into. Topify approaches this with a seven-metric matrix inside its Comprehensive GEO Analytics: visibility, sentiment, position, volume, mentions, intent, and CVR. Each metric maps to one of the failure modes above.
Position Tracking handles ranking the way AI search actually requires: at the prompt level, relative to named competitors, sampled repeatedly rather than snapshotted. Instead of “your rank is #3,” you see which specific prompts place you where, and against whom. That’s the difference between a score and a diagnosis.
Source Analysis answers the “why did it move” question directly. It tracks the exact domains and URLs each AI platform cites for your prompt set, so when your mention rate drops, you can see which source displaced yours instead of guessing. Given that roughly nine in ten cited URLs churn within a month, this layer is where most of the actionable signal lives.
AI Volume Analytics addresses the intent problem. It surfaces which prompts carry real query volume and buyer intent, so you’re not optimizing your average by winning prompts nobody commercially relevant is asking. Sentiment scoring runs alongside, flagging when AI engines frame your brand in ways that contradict your positioning.
Coverage spans ChatGPT, Gemini, Perplexity, Google AI Overviews, DeepSeek, and other major engines, which matters because cross-platform disagreement is the norm, not the exception. The Basic plan runs $99/month with 100 tracked prompts and 9,000 AI answer analyses, and there’s a 30-day trial if you’d rather validate against your own prompt set before committing. For teams still earlier in the process, this open reference list of free GEO tools is a reasonable place to benchmark what free checkers can and can’t see.
The point isn’t that more metrics are automatically better. It’s that these specific seven correspond to questions a VP will actually ask, and a single rank number answers none of them.
How to Audit the AI Rank Checker You’re Already Using
You don’t need to switch tools to start fixing this. Start by auditing the one you have against five questions:
- Can you see the exact prompts behind every number? If the prompt set is hidden or fixed, the score is untraceable.
- Does it separate mention rate from position? If one number covers both, you can’t tell absence from low ranking.
- Does it distinguish mentions from citations? A brand named in text without a linked source is a zero-click event, not a traffic win.
- How often does it sample? Point-in-time snapshots can’t smooth out LLM non-determinism. Look for repeated, longitudinal testing.
- Which platforms does it cover? Performance is rarely consistent across ChatGPT, Perplexity, Gemini, and AI Overviews. One platform is an anecdote.
If your current tool fails three or more of these, the number it gives you each week isn’t measuring your AI visibility. It’s measuring the tool’s sampling artifacts.
Conclusion
The next time someone asks what your AI rank means, you should be able to answer in specifics: which prompts, what mention rate, which sources, what framing, across which platforms. If your tool can’t support that answer, the number on the dashboard was never information. It was decoration.
Start with the five-question audit above. Then rebuild your reporting around mention rate and citation sources first, position second. The teams treating AI visibility as a decomposable system, rather than a single score to celebrate or panic over, are the ones who’ll know what they did right when the number moves.
FAQ
Q: What is an AI rank checker?
A: An AI rank checker is a tool that tracks where a brand appears in AI-generated answers across platforms like ChatGPT, Perplexity, and Google AI Overviews. Basic checkers output a single position or score. More complete platforms decompose that into prompt-level position, mention rate, citation sources, and sentiment.
Q: Why do AI rankings change every time I check?
A: LLMs are non-deterministic by design. Temperature settings, parallel processing, and continuous index updates mean identical prompts produce varying answers. Research shows only about 10.6% of AI-cited URLs persist across 28 days, so single-sample rankings are largely noise. Repeated longitudinal sampling is the only way to separate signal from variance.
Q: What’s the difference between AI search ranking and brand mentions?
A: They’re independent metrics. Mention rate measures how often your brand appears at all across relevant prompts, while ranking measures your position when you do appear. A brand can rank #2 on a few tested prompts while being absent from most others. Mention rate is the gating metric; position matters only after inclusion.
Q: What does an AI visibility score mean?
A: On its own, usually very little. A visibility score is an aggregate abstraction that compresses prompt selection, sampling frequency, platform coverage, and citation behavior into one number. It becomes meaningful only when you can trace it back to specific prompts, mention rates, and cited sources.

