You published a 3,000-word guide last quarter. It ranks on page one, the backlinks are solid, and traffic looks healthy. Then you run your core industry prompt through Perplexity and watch it cite a competitor’s 7-step listicle instead. Three times in a row.
The frustrating part is that nothing in your analytics explains why. Google Search Console shows impressions and clicks. It doesn’t show that an AI engine scanned your page, couldn’t extract a clean answer, and moved on.
That gap has a structural cause, and it’s fixable. The fix comes in two parts: rebuild your content around formats AI engines actually cite, then verify the change with an AI rank checker instead of guessing.
Listicles and How-Tos Pull Up to 40% of AI Citations. Here’s Why.
The numbers on format are hard to ignore. According to Wix AI Search Lab research, listicles and comparative content account for 21 to 60% of all AI citations depending on query type. For commercial queries, the kind that start with “best software for” or “top tools to,” listicle citation rates reach up to 40%.
This isn’t because AI engines have a taste for numbered headlines. It’s mechanical. LLM-powered answer engines don’t read pages the way humans do. They retrieve chunks, and a listicle is essentially a pre-chunked document. Each list item functions as a discrete, self-contained unit the model can extract, verify, and cite with high confidence.
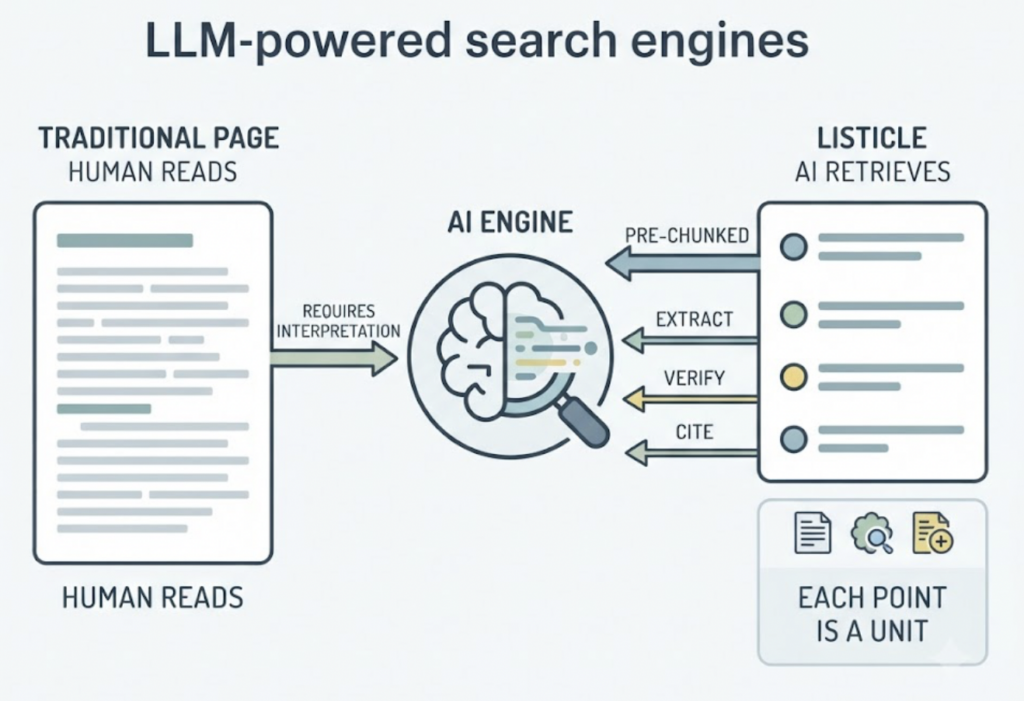
Narrative long-form works differently. The argument builds across sections, the payoff lands in paragraph twelve, and no single block stands alone. A human reader follows the thread. A retrieval system sees a wall of interdependent text and picks the competitor’s cleaner source instead.
The stakes are bigger than ego. With AI answer engines now influencing over 65% of search queries, and research from Seer Interactive and Ahrefs showing AI-referred traffic converting at up to 23x the rate of standard organic visits, citation share is becoming the metric that decides who gets the buyer.
Structure is the entry ticket.
What an AI Rank Checker Actually Measures
Before restructuring anything, it helps to understand what you’re optimizing toward, because the measurement unit has changed.
A traditional rank tracker reports a URL’s position on a static list, 1 through 100. An AI rank checker tracks something messier: whether your brand appears inside a synthesized answer, where it sits relative to competitors, and which specific URLs the engine cited to build that answer.
| Metric | Traditional SEO Tracker | AI Rank Checker |
|---|---|---|
| Objective | Keyword rank on a results page | Presence in the AI answer |
| Data unit | URL position | Citation, mention, share of voice |
| Stability | Relatively consistent | Volatile, session-dependent |
| Core value | Click-through rate | Brand trust and influence |
The two systems also disagree more than most teams expect. The Digital Bloom’s 2026 AI Citation Report found roughly a 76% overlap between Google’s top 10 and AI citations, which sounds reassuring until you flip it: about a quarter of what AI cites doesn’t come from the top of Google at all. A page can rank #1 and never get cited if it’s too dense, lacks H2/H3 hierarchy, or buries its answers.
That’s why format work and measurement have to run as one loop. You restructure, the engines re-retrieve, and the AI rank checker tells you whether the change registered. Skip the measurement half and you’re editing blind.
How to Structure a Listicle That Wins AI Citations
A citation-ready listicle follows rules that have little to do with what makes a listicle pleasant to skim. Three of them do most of the work.
Front-Load the Answer in Every List Item
AI systems scan the first 30% of a page for roughly 44% of their citations. The same top-heavy logic applies inside each list item: the first sentence should deliver the verdict, with context after.
Compare “Tool X has been around since 2019 and has grown steadily…” with “Tool X is the strongest pick for agencies managing 10+ client brands, starting at $99/month.” The second version is quotable on its own. Pages built on this pyramid structure, summary first and expansion later, show a 17.46% higher inclusion rate in AI summaries.
Keep Each Item Extractable on Its Own
Every entry should carry its own definition, one concrete data point, and a use-case sentence. If a list item only makes sense after reading the item above it, it can’t be cited independently, and independence is the whole advantage of the format.
Add a comparison table near the top. Structured data tables with specific values deliver a 2.5x citation multiplier over unstructured content, because a table gives the model pre-verified value pairs it can lift directly into an answer.
Anchor Claims to Outside Evidence
AI models lean on trust clusters. Content citing authoritative sources, industry stats, government data, or peer-reviewed research is 3.2x more likely to be cited than content making unsupported claims. Generic “top 10” pages with no external corroboration are exactly what models have learned to distrust.
How to Structure a How-To Guide AI Engines Cite
How-to content is the other format inside that 40% citation block, and its rules are stricter because the model needs to reproduce a sequence, not just a fact.
Number every step, and open each one with a verb. “Step 3: Export the citation report as CSV” gives the engine an unambiguous action unit. Vague step titles like “Getting things ready” give it nothing to anchor.
Embed specifics inside each step. Time estimates, tool names, exact settings, and thresholds all raise extraction confidence. “Wait 30 days before re-running your prompt set” is citable. “Wait a while and check again” isn’t. Detail reads as authority to both humans and retrieval systems.
Two more structural moves compound the effect. Write H2 and H3 headers that mirror real queries (“How long until AI citations update?”) so the semantic hierarchy matches how people prompt. Then close with an FAQ block backed by FAQPage schema, which hands the model labeled question-answer pairs it can map straight onto conversational queries.
3 Structural Mistakes That Cost You AI Citations
The buried verdict. The conclusion arrives in the fifth paragraph after extensive throat-clearing. Since engines weight the opening third of the page so heavily, an answer that shows up late often doesn’t show up at all in the retrieval window.
Suspense headers. Section titles like “The Surprising Truth” or “What We Learned” carry zero semantic information. The model can’t tell what the section answers, so it can’t match the section to a query. Curiosity-gap headlines are a human engagement tactic that actively hurts machine retrieval.
The unbroken wall. No tables, no lists, paragraphs running six-plus sentences. AI systems struggle to chunk long unbroken text, and content that can’t be chunked can’t be cited. Blocks of 2 to 3 sentences with clear subheads are the reliable ceiling.
Notice what’s not on this list: content quality. Plenty of genuinely excellent pages fail all three tests. That’s the uncomfortable part of the citation gap, and also the reason it’s fixable in an afternoon of editing rather than a quarter of rewriting.
Verify Your Structure Works with an AI Rank Checker
Restructuring without measurement is where most teams stall. AI answers are volatile by nature, shifting with model updates and retrieval weights, so a single manual ChatGPT check tells you almost nothing. You need a baseline, a change, and a tracked delta.
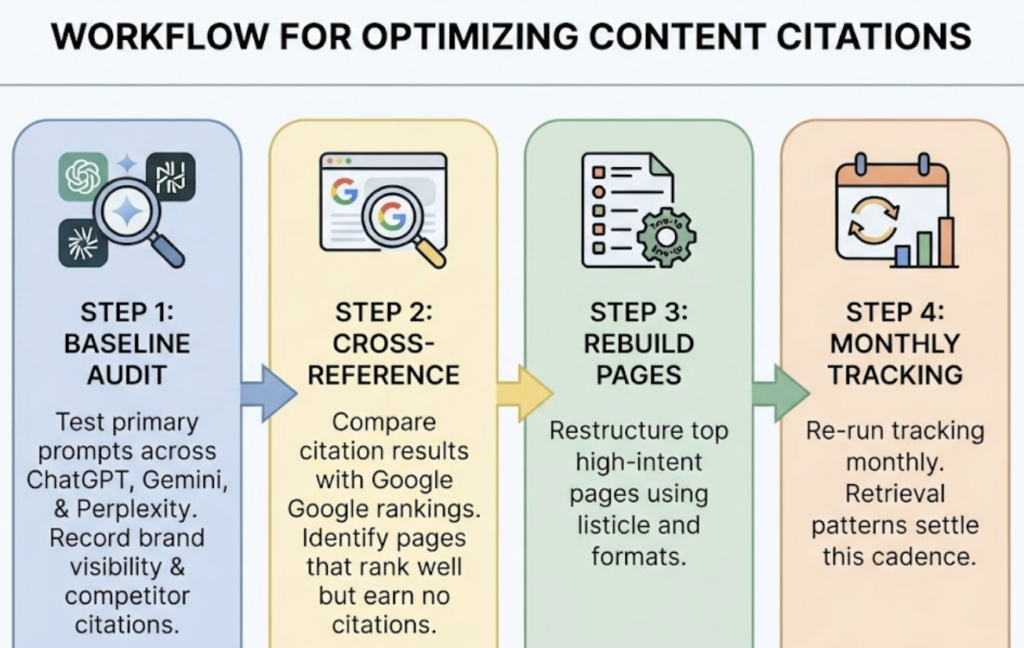
The workflow looks like this. First, run a baseline audit: test your primary industry prompts across ChatGPT, Gemini, and Perplexity, and record whether your brand appears and which competitor URLs get cited instead. Second, cross-reference against Google rankings to isolate pages that rank well but earn no citations. Those are your restructuring candidates. Third, rebuild your top high-intent pages using the listicle and how-to rules above. Fourth, re-run tracking monthly, because that’s roughly the cadence at which retrieval patterns settle.
This is the loop Topify was built to close. Its Source Analysis reverse-engineers the exact domains and URLs that AI platforms cite for your prompt set, so after a restructure you can see whether engines started pulling from your new listicle or kept citing the competitor. Position Tracking layers on where you sit in the answer relative to rivals, and coverage spans ChatGPT, Gemini, Perplexity, DeepSeek, and other major engines, which matters given how differently each platform retrieves.
In practice, that means you can publish a restructured page, wait a retrieval cycle, and trace a new citation back to the specific section that earned it. The Basic plan runs $99/month with 100 tracked prompts and 9,000 AI answer analyses, which covers a monthly measurement cadence for a mid-size content library. If you want to scope the space before committing, this GEO free tools reference collects no-cost checkers worth testing first.
Conclusion
The citation gap isn’t a quality problem. It’s a packaging problem, and the data is consistent: listicles and how-tos win up to 40% of commercial-query citations because they’re pre-chunked, front-loaded, and independently extractable.
Start small. Pick two or three pages that rank well on Google but never surface in AI answers, restructure them with answer-first list items, a data table, and query-mirroring headers, then let an ai rank checker confirm whether citations follow over the next 30 days. Track it. Adjust it. Repeat monthly. Getting a baseline in place takes minutes, and it turns format strategy from guesswork into a measurable loop.
FAQ
Q: What’s the difference between an AI rank checker and a traditional rank tracker?
A: A traditional tracker reports your URL’s position on a search results page. An AI rank checker measures whether your brand appears inside AI-generated answers, how often, in what position relative to competitors, and which URLs the engine cited as sources.
Q: How long does it take to see citation changes after restructuring content?
A: Typically one retrieval cycle, which in most cases means 2 to 6 weeks depending on the platform. Because AI answers fluctuate with model updates, monthly tracking is the minimum cadence for judging whether a structural change actually moved citation frequency.
Q: Do listicles work for every industry or topic?
A: They dominate commercial and comparison queries, where citation rates reach up to 40%. For definitional or technical queries, answer-first explainers with strong H2/H3 hierarchy and FAQ schema tend to perform better. Match format to query intent rather than defaulting to lists everywhere.
Q: Can I check AI rankings across ChatGPT, Gemini, and Perplexity at once?
A: Yes. Multi-engine coverage is the main argument for dedicated tooling over manual spot checks, since each platform retrieves and cites differently. Platforms like Topify run your prompt set across all major engines and consolidate mentions, positions, and citations in one view.

