
Spend an afternoon researching AI query tracking services and you’ll hit the same wall most marketing leads do: every vendor defines the category differently. One platform tracks 50 prompts on ChatGPT only. Another promises “full LLM coverage” without saying what that means. Pricing runs from $49 to over $4,000 a month, and the feature lists don’t map to each other, so you can’t compare quotes side by side.
The confusion isn’t your fault. The category is barely three years old, and vendors are still inventing the vocabulary. But underneath the marketing noise, these services all do the same fundamental job, and once you understand that job, evaluating them takes an hour instead of a week.
What an AI Query Tracking Service Actually Tracks
An AI query tracking service monitors what large language models say about your brand when users ask buying-intent questions. It sends a defined set of prompts to platforms like ChatGPT, Perplexity, and Gemini on a schedule, then parses each response to record whether your brand appeared, where it ranked, how it was described, and which sources the AI cited.
That sounds like rank tracking with extra steps. It isn’t.
Traditional rank trackers monitor a static page of results: keyword in, ten blue links out, same for everyone. AI answers are non-deterministic. LLMs are stochastic by design, which means the identical prompt can produce different responses depending on model updates, temperature settings, and the platform’s retrieval process. A single manual check tells you almost nothing. Professional services solve this with multi-sample polling: querying the same prompt repeatedly over time to establish a statistically meaningful visibility baseline instead of a lucky (or unlucky) snapshot.
This is the core distinction to hold onto during vendor evaluations. If a tool can’t explain its sampling methodology, it’s a screenshot generator, not a tracking service.
How Does an AI Query Tracking Service Work? The 4-Step Pipeline
Under the hood, most professional platforms run the same pipeline. Here’s what happens between “add your brand” and “view your dashboard,” using a fictional CRM startup as the running example.
Step 1: Prompt Set Design
The service builds a library of prompts that mirror the buyer journey. For the CRM startup, that includes category queries (“best CRM for startups”), comparison queries (“HubSpot vs. affordable alternatives”), and problem queries (“how do I track sales pipeline without spreadsheets”). The brand name appears in almost none of them, which is the point. You’re testing whether AI recommends you to people who don’t know you exist yet.

Step 2: Multi-Engine Polling
The platform queries each prompt across major engines on a recurring schedule, typically daily or weekly. Coverage matters here because ecosystems behave differently: Perplexity leans heavily on citations, ChatGPT on training data plus browsing, Gemini on Google’s index. A brand can be visible on one engine and absent on another.
Step 3: Semantic Parsing
Each raw response gets parsed for four signals: mention frequency (did the brand appear), salience (did it land in the top portion of the answer, the prime real estate users actually read), sentiment (positive, neutral, or negative framing), and citation mapping (which URLs the AI referenced as evidence).
Step 4: Trend Aggregation
Individual samples get normalized into rolling averages, usually over 30 days, to filter model-induced noise from genuine shifts. If the CRM startup’s visibility drops 15 points in a week, aggregation tells you whether that’s random variance or a competitor’s new content pulling citations away.
How to Measure Results: The 5 Metrics That Matter
Once tracking runs, the question becomes what “good” looks like. These are the core AI visibility metrics that answer-engine optimization teams have standardized around, with rough health benchmarks.
| Metric | What It Measures | Health Signal |
|---|---|---|
| Visibility Rate | % of tracked prompts where your brand is mentioned | Above 40% on category-specific queries |
| Average Position | Where your brand appears in the recommendation list | Top 3 for high-intent queries |
| Sentiment Score | The tone of your brand’s description | Neutral to positive; negative framing signals content gaps |
| Citation Share | % of responses citing a given source (your blog, G2, etc.) | Higher share means the AI treats that source as authoritative |
| Conversion Signal | Branded search or traffic lift after AI mentions | Should correlate with visibility spikes |
One practical note: citation share is the metric teams most often ignore and most often regret ignoring. It tells you which third-party sites are feeding the AI’s opinion of your category. That’s actionable in a way raw mention counts aren’t, because you can pitch, publish, or partner your way into those sources.
Why an Enterprise LLM Visibility Platform Differs from a Basic Tracker
The market splits into two tiers, and the gap between them is wider than the pricing pages suggest.
Basic trackers, typically $49 to $150 per month, monitor mention frequency across one or two platforms. For a solo founder checking whether ChatGPT knows their product exists, that’s often enough.
An enterprise LLM visibility platform solves a different problem. Larger organizations need multi-brand and multi-market support, API access to pipe data into existing BI dashboards, team seats with role permissions, and automated competitor detection rather than manually maintained lists. The defining enterprise capability is citation gap analysis: reverse-engineering which sources make your competitors visible, so you know exactly which publications or review sites to target.
Here’s how the tiers compare in practice:
| Capability | Basic Tracker | Enterprise LLM Visibility Platform |
|---|---|---|
| Engine coverage | 1-2 platforms | 4+ platforms, including regional engines |
| Prompt volume | 50-100/month | Custom, often 250+ |
| Competitor tracking | Manual or none | Automated detection and benchmarking |
| Citation analysis | Mention counts only | Full citation supply chain mapping |
| Team workflows | Single user | Multi-seat, multi-project, API access |
The honest guidance: don’t buy enterprise capabilities you won’t use. But if you manage more than one brand, operate in multiple markets, or report to stakeholders who ask “why did this change,” the basic tier will frustrate you within a quarter.
Best Tools for AI Query Tracking in 2026
The vendor field has grown crowded enough that roundups of AI search monitoring tools now cover a dozen or more options, ranging from lightweight mention counters to full optimization suites. Rather than list everything, it’s more useful to look at what a complete platform includes, using one as the reference case.
Topify covers the full pipeline described above and adds the layers that basic trackers skip. It tracks prompt-level visibility across ChatGPT, Gemini, Perplexity, and DeepSeek, plus regional engines like Doubao and Qwen, which matters for brands with audiences outside North America. Monitoring spans seven metrics: visibility, sentiment, position, volume, mentions, intent, and conversion visibility rate.
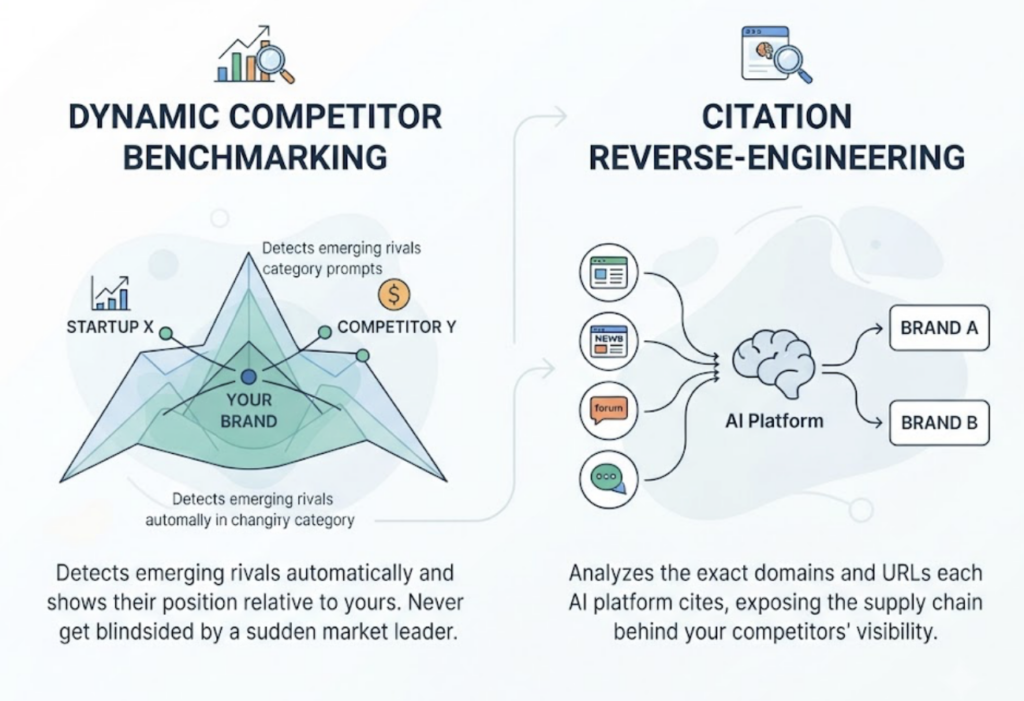
Two capabilities stand out for teams past the “are we visible” stage. Dynamic competitor benchmarking detects emerging rivals automatically and shows their position relative to yours, so you’re not blindsided by a startup that suddenly dominates your category prompts. And citation reverse-engineering analyzes the exact domains and URLs each AI platform cites, exposing the supply chain behind your competitors’ visibility.
For teams that want execution alongside measurement, the platform’s agent can propose and deploy GEO strategies from plain-English goals. That’s a meaningful difference from tools that stop at dashboards.
Other tools in the category serve narrower needs well: some focus purely on Google AI Overviews, others on single-engine mention alerts at lower price points. The fit depends on how many engines your audience uses and whether you need the citation layer.
A 7-Point Checklist Before You Buy
Run every vendor demo against this list. It compresses the evaluation from weeks to a single call.
- Engine coverage. Does it track every platform your audience actually uses, including regional ones if you sell internationally?
- Prompt quota. How many prompts per month, and what does expansion cost? Under 100 is tight for most mid-size brands.
- Sampling frequency. Daily or weekly polling with aggregation, not one-off snapshots.
- Competitor tracking. Automated detection, or a manual list you’ll forget to update?
- Citation analysis. Can you see which sources drive AI answers, or just whether you were mentioned?
- Data access. Export, API, or dashboard-only? Dashboard-only becomes a bottleneck once leadership wants the numbers in their own reports.
- Pricing transparency. Published tiers you can budget against, or “book a call” pricing that hides the real cost?
If a vendor fails on points 3 or 5, keep looking. Those two separate measurement from guesswork.
Common Mistakes That Skew Your Tracking Data
Even with the right tool, three errors reliably corrupt AI visibility programs.
The single-sample bias. Someone on the team asks ChatGPT about the category once, screenshots the answer, and the screenshot becomes strategy. Model volatility makes any single response unreliable. Always work from aggregated data across multiple samples.
Tracking only brand-name queries. If every prompt contains your brand name, your visibility rate will look great and mean nothing. The revenue-relevant queries are category ones (“best cloud accounting software”) where you should appear but the user never typed your name.
The SEO-to-AEO fallacy. Teams assume Google logic transfers: build links, watch AI mentions rise. It doesn’t work that way. Strong domain authority and backlink profiles often coexist with zero AI mentions, because LLMs weigh semantic authority, clear Q&A structure, and third-party social proof over link density. Your rank tracker and your query tracker will regularly disagree, and both will be right about what they measure.
That third mistake is the expensive one. It leads teams to spend another quarter on link building when the actual gap is structural content and citation coverage.
AI Query Tracking Service Pricing: What You’ll Actually Pay
Pricing has coalesced around prompt volume and engine coverage, with three consistent tiers across the market:
- Entry level ($49-$199/mo): 50-100 prompts, often single-engine focus. Fine for validation, limiting for strategy.
- Professional ($200-$500/mo): Multi-engine coverage, sentiment analysis, basic competitor tracking.
- Enterprise ($500-$4,000+/mo): Custom prompt volume, API access, agency workspaces, dedicated support.
As a concrete reference point, Topify’s pricing runs Basic at $99/month (100 prompts, ChatGPT, Perplexity, and AI Overviews tracking, 4 projects), Pro at $199/month (250 prompts, 10 seats), and Enterprise from $499/month with a dedicated account manager. Multi-engine tracking and competitor benchmarking are included below the $200 line, which undercuts the market’s typical professional tier.
Budget guidance: start where your prompt volume actually sits. A focused brand tracking 100 high-intent prompts learns more than a sprawling program tracking 500 vague ones.
How to Improve Your Numbers: A 90-Day Strategy
Tracking without action is just expensive anxiety. Here’s the strategy sequence that turns data into visibility gains.
Days 0-30: Baseline. Audit your top 100 high-intent prompts across major engines. Record your visibility rate, average position, and sentiment against your top three competitors. Resist optimizing anything yet; you need clean baseline data first.
Days 31-60: Citation gap analysis. Map the citation supply chain. If competitors keep getting cited by specific review sites or industry publications that ignore you, those sites are your target list. Prioritize content partnerships, PR outreach, or review-platform presence there.
Days 61-90: Structural optimization. Restructure key pages to be answer-friendly: clear FAQ sections, transparent pricing tables, expert author bylines. Then watch the next tracking cycle for movement. Visibility shifts typically lag content changes by weeks, so aggregated trend data (not daily checks) tells you whether it worked.
Then the cycle repeats: expand the prompt set, refine, remeasure.
Conclusion
The vendor confusion that makes this category hard to shop is mostly surface-level. Every AI query tracking service does the same core job: sample AI answers systematically, parse them for brand signals, and aggregate the noise into trends. The real differences live in engine coverage, citation analysis depth, and whether pricing scales with your prompt volume.
Run the 7-point checklist against any shortlist and the decision usually makes itself. If you want to see what prompt-level tracking looks like on your own brand before committing budget, you can start with Topify and have baseline data within the first tracking cycle.
FAQ
Q: What is an AI query tracking service?
A: It’s a platform that repeatedly sends buying-intent prompts to AI engines like ChatGPT, Perplexity, and Gemini, then parses the responses to measure whether your brand is mentioned, where it ranks, how it’s described, and which sources the AI cites.
Q: How much does an AI query tracking service cost?
A: Entry-level plans run $49-$199/month for limited prompts, professional tiers $200-$500/month with multi-engine coverage, and enterprise plans $500-$4,000+/month. Topify starts at $99/month with multi-engine tracking included.
Q: How is an enterprise LLM visibility platform different from a basic tracker?
A: Enterprise platforms add multi-brand support, API access, automated competitor detection, team workflows, and citation gap analysis. Basic trackers typically count mentions on one or two engines.
Q: How often should AI queries be sampled?
A: Daily or weekly, then aggregated over a rolling window such as 30 days. AI responses are non-deterministic, so single checks produce unreliable data.

