
You can pull up rank positions for 200 keywords in under a minute. Domain authority, backlinks, SERP movement, all of it sits in one dashboard. Then someone asks Claude, “What’s the best tool for [your category]?” and your brand doesn’t come up. Your rank tracker has nothing to say about that, because it was built to crawl pages, not read answers. The gap between what you can measure and what AI is telling buyers keeps widening, and most of the tools on your desk can’t see into it.
That’s the gap an AI prompt tracking tracker is built to close.
What an AI Prompt Tracking Tracker Actually Measures
A traditional rank tracker answers one question: where does this URL sit on a results page? An AI prompt tracking tracker answers a different one. It measures whether an AI model mentions your brand when someone asks a real question, where in the answer you show up, and how you’re described.
The tracking unit shifts from keyword position to prompt-level brand mention. Instead of “rank #3 for project management software,” you’re measuring “named in 4 of 10 Claude responses to buyers comparing project tools, usually in the second paragraph.” That’s a more honest picture of what people actually see.
The data nature is different too. Google rankings are deterministic: same query, same result, every time. AI answers are probabilistic, so the same prompt entered twice can return two different brand lists. The job of a tracker isn’t to read one answer. It’s to sample many and turn that noise into a trend.
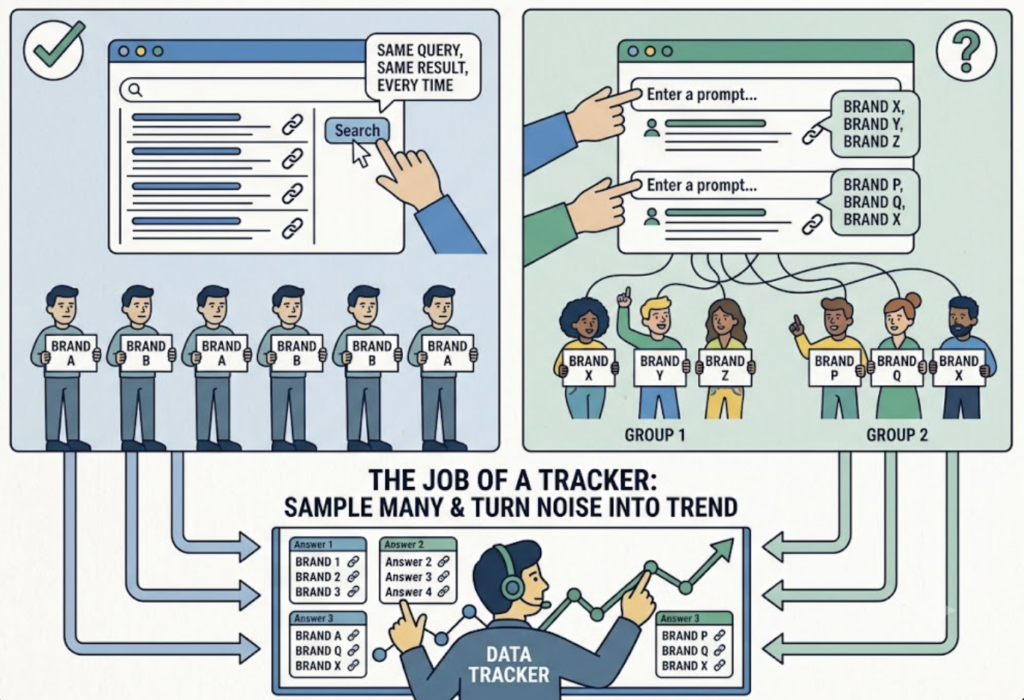
The KPIs follow from that. Not traffic and click-through rate, but share of voice, citation rate, and sentiment.
How Does an AI Prompt Tracking Tracker Work
Under the hood, the work is a pipeline built to normalize messy, non-deterministic output into something you can chart.
It starts with a prompt portfolio: a curated set of head and long-tail prompts that mirror the buyer’s journey, spanning informational, comparative, transactional, and brand-specific queries. This is the part most teams underinvest in, and it’s the part that decides whether the data means anything.
Then comes cross-platform execution. The same prompt set runs against multiple models (GPT-4, Claude, Gemini, Perplexity) because each one retrieves and synthesizes differently. A brand that dominates Perplexity can be invisible in Claude.
Next is output parsing. The tracker reads each answer and extracts four things: brand mention rate, citation source (did the model link your URL), positioning (intro summary versus a secondary list), and sentiment. Then trend aggregation maps those points over time into a visibility score.
One detail explains why sampling matters. LLMs use query fan-out, breaking a single prompt into several sub-retrieval tasks. That’s why the same question yields different brand sets on different runs, and why a one-time check tells you almost nothing.
Why a Rank Tracking Tool Won’t Cover Claude
Search “rank tracking tool claude” and you’ll find SEO platforms that crawl and index HTML pages. That architecture is the exact reason they can’t measure AI visibility.
Three problems stack up.
First, there’s no ranking page. A Claude or ChatGPT answer is generated in real time. It isn’t a static URL sitting in an index that a crawler can revisit. Second, personalization and non-determinism: models vary answers by user history and temperature, while SEO tools assume a clean, logged-out browser state. Third, no synthesis analysis. Legacy suites like Ahrefs, Semrush, and Moz look for keyword density and backlink counts, but a prompt tracker has to evaluate semantic completeness and whether your entity is aligned in the model’s knowledge graph.
This catches SEO teams off guard. Stable Google rankings increasingly lose clicks as AI Overviews and chat answers absorb the query. Your position can hold while your real visibility erodes.
A rank tracker will never flag that, because it’s measuring the wrong surface.
How to Measure AI Prompt Tracking Tracker Performance
Once you accept that mentions beat rankings, the question becomes which metrics to trust.
Four matter most. Share of voice is your mention rate relative to direct competitors inside the same prompt cluster. Citation velocity is how often the model links directly to your owned content, which tends to be the strongest signal of authority. Sentiment alignment tells you whether you’re framed as a category leader or an afterthought. And visibility drift tracks how often your brand simply vanishes between runs.
That last one is sobering. Roughly 65% of domains cited in AI answers change between weekly runs, which means a single good report can hand you a false sense of security.
This is where Topify fits the measurement problem. Its Comprehensive GEO Analytics rolls seven metrics (visibility, sentiment, position, volume, mentions, intent, and CVR) into one view across ChatGPT, Gemini, Perplexity, Claude, and others. In practice, you can watch a drop in Claude mentions and trace it to a specific source that stopped citing you, without stitching together four separate tools.
The point isn’t more dashboards. It’s seeing share of voice and the reason behind it in the same place.
How to Improve Your AI Prompt Tracking Setup
A measurement system only pays off if it drives changes. Here’s a working checklist.
Audit your prompts first. Start with 20 to 30 high-value prompts, not 500 random keywords. Tracking 25 to 40 strategy-aligned prompts is more meaningful than monitoring hundreds of low-intent ones, because each AI answer is dense and costly to parse.
Baseline before you touch anything. Record your share of voice across major platforms so you have a “before” to measure against.
Then run the optimization loop. Treat citation gaps, prompts where competitors appear and you don’t, as your content roadmap. Improve structured data and FAQ sections so your pages are easier for models to parse and quote.
Finding those gaps by hand is slow. Topify’s prompt discovery surfaces high-volume prompts you’re missing, and its competitor benchmarking shows who the model recommends instead of you.
Last, hold steady. Track for at least 30 days before pivoting, because models need time to pull new content into their retrieval pipelines.
Audit. Baseline. Optimize. Repeat.
Common Mistakes in AI Prompt Tracking
Most failed setups share the same handful of errors.
Testing one platform. A brand can lead on Perplexity and disappear on Claude, so single-platform data is misleading by default.
Too few prompts, or too many of the wrong kind. Five prompts can’t capture a category, and 500 generic keywords drown the signal in noise.
Reading a single run. Given non-deterministic output, one snapshot is closer to a coin flip than a measurement.
Watching mentions but ignoring position. Being named last in a ten-item list isn’t the same as leading the answer, yet a raw mention count treats them as equal.
And measuring without a baseline, which leaves you unable to prove whether the change you made actually worked.
Best Tools for AI Prompt Tracking and Their Pricing
Tools in this category split along one line: how many platforms they cover, and whether they explain the “why” behind a score instead of just the number.
| Tool | AI Platforms Covered | Metrics Depth | Starting Price |
|---|---|---|---|
| Topify | ChatGPT, Gemini, Perplexity, Claude, DeepSeek, and more | 7 metrics + prompt discovery + competitor benchmarking | $99/mo |
| General SEO suites (Ahrefs, Semrush) | Limited, mostly AI Overviews | Keyword-centric, light AI coverage | Varies |
| Single-platform monitors | Usually 1 to 2 | Mention rate, basic sentiment | Varies |
On pricing, Topify’s Basic plan runs $99/mo and includes tracking across ChatGPT, Perplexity, and AI Overviews, 100 prompts, and 9,000 AI answer analyses. The Pro plan at $199/mo lifts that to 250 prompts and 22,500 analyses, which suits teams running multi-cluster prompt portfolios. Enterprise starts at $499/mo with a dedicated account manager. Full numbers sit on the Topify pricing page.
For a category this volatile, a $99 entry point that samples answers across platforms costs far less than the visibility you lose by guessing. You can get started on a trial and baseline your share of voice in an afternoon.
Conclusion
Rank trackers measure pages. AI prompt tracking measures answers, and answers are what buyers see now. The gap from the opening (strong rankings, zero presence in Claude) closes only when you start sampling prompts instead of crawling URLs. Begin with 20 to 30 high-intent prompts, baseline your share of voice across platforms, and treat citation gaps as your content roadmap. The brands that win AI search aren’t the ones ranking highest. They’re the ones measuring what the model actually says, then fixing it.
FAQ
Q: What is an AI prompt tracking tracker?
A: It’s a tool that measures whether AI models mention your brand in response to real prompts, where you appear in the answer, and how you’re described. Unlike a rank tracker, it tracks prompt-level mentions and citations instead of keyword positions on a results page.
Q: How does an AI prompt tracking tracker work?
A: It runs a curated set of prompts across models like ChatGPT, Claude, Gemini, and Perplexity, parses each answer for mention rate, citation source, position, and sentiment, then aggregates those into a visibility trend. Because outputs are non-deterministic, it samples many runs rather than reading a single answer.
Q: Can a rank tracking tool track Claude?
A: Not in any meaningful way. Rank trackers crawl indexed HTML pages, but a Claude answer is generated in real time and isn’t a static, crawlable URL. Measuring Claude visibility requires sampling generated responses, which is a different method entirely.
Q: How much does AI prompt tracking cost?
A: Entry-level platforms start around $99/mo. Topify’s Basic plan is $99/mo for 100 prompts and cross-platform tracking, Pro is $199/mo for 250 prompts, and Enterprise begins at $499/mo. Pricing usually scales with prompt volume and the number of AI answers analyzed.

