
Your team checks Google rankings every week, and the report comes back green. Then a buyer opens ChatGPT, types a question your product was built to answer, and reads back five recommendations. None of them is you. That happened on Tuesday, and probably again on Thursday, and you have no record of either, because nothing in your stack watches what AI says when someone asks. Rankings tell you where you sit in a list of links. They say nothing about whether an AI engine names you when it writes the answer.
What an AI Prompt Tracking Dashboard Tracks That Rankings Can’t
An AI prompt tracking dashboard monitors how large language models answer a defined set of buyer questions, and records whether your brand shows up in those answers. Instead of a keyword and a position, you’re watching a question like “what’s the best tool for AI visibility” and checking three things: did the model mention you, did it recommend you, and where did you land relative to competitors.
That’s a different measurement problem than search ranking. Keyword tracking monitors a fixed phrase against a fixed list. Prompt tracking monitors how a model synthesizes an answer, which changes by platform, by phrasing, and even by run.
The gap between the two channels is wider than most teams expect. Research from SISTRIX found that roughly 80% of LLM citations don’t rank in Google’s top 100 results. Your rankings can be healthy while your AI presence is empty.
That’s the part most dashboards were never built to see.
How an AI Prompt Tracking Dashboard Actually Works
Under the hood, the process runs in three stages. First, you build prompt sets, which are groups of questions that map to the buyer’s journey rather than single keywords. Second, the system runs those prompts across multiple engines, often many times. Third, it parses each answer for brand mentions, citations, position, and sentiment, then logs the result over time.
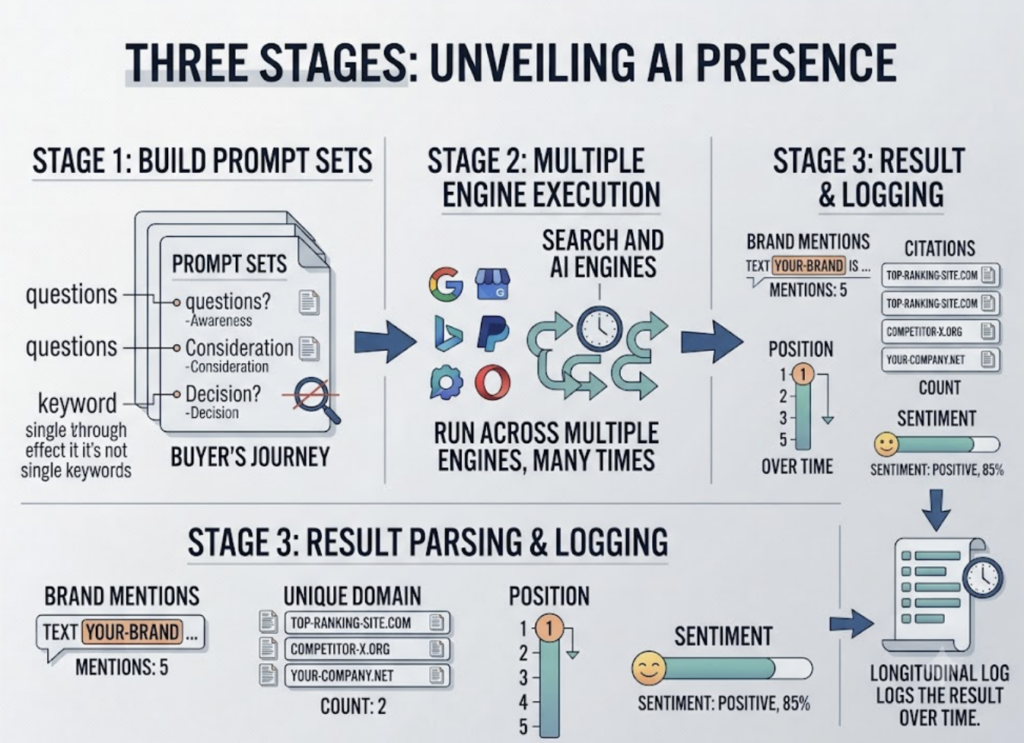
The reason for running the same prompt repeatedly is the query fan-out effect. LLMs interpret a question like “what’s the best running shoe for snow” slightly differently on each pass, so a single check tells you almost nothing. You need multiple runs to know whether your visibility is reliable or just a lucky sample.
Platform behavior adds another layer. Google AI Overviews tend to favor structured formats like FAQ and HowTo content, while Perplexity tends to reward original research and deep data. A prompt that surfaces your brand in one engine can ignore it entirely in another.
And the data goes stale fast. SISTRIX data shows Google AI Mode replaces about 56% of cited domains every week, while ChatGPT churns roughly 74%. A dashboard that updates monthly is reporting on a reality that no longer exists.
How to Measure It: Six Metrics That Beat a Mention Count
Counting mentions is the vanity metric of GEO. It tells you that you exist somewhere, not whether you’re winning. Most teams that take AI visibility seriously track six core metrics instead.
Share of answers tells you whether you have a visibility problem at all. Third-party mention measures how large your footprint is across answers you don’t control. Information correctness checks whether the AI is describing your brand accurately, since a frequent mention that calls a premium product “budget-friendly” is a problem, not a win.
The other three are about quality and reliability. Recommendations track whether the model actively prefers you, not just names you. Multi-surface tracking confirms your visibility holds across ChatGPT, Perplexity, Gemini, and AI Overviews. Multi-run consistency confirms it holds across repeated checks rather than appearing once and vanishing.
One distinction matters across all six: a brand mention is when the AI names your company, while a citation is when it links back to you. Both signal visibility, but only the citation drives direct traffic.
Where AI Prompt Tracking Dashboards Fit Among GEO Trackers
A prompt dashboard is one view inside the broader category of generative engine optimization (GEO) trackers. The market has split into two types, and the right pick depends on how your team already works.
Broad SEO suites fold AI data into an existing search workflow. Dedicated GEO platforms go deeper on citation analysis and prompt-level optimization, and some add execution on top of measurement. Here’s how the categories compare.
| Tool type | Platform coverage | Metric depth | Execution built in |
|---|---|---|---|
| Broad SEO suite (e.g. Semrush AI Toolkit, SE Ranking) | AI data added to existing search reports | Mention and basic citation tracking | No, reporting only |
| Single-platform monitor | Usually one engine | Mentions, limited position data | No |
| Dedicated GEO platform (e.g. Topify, AthenaHQ, Frase) | Multiple engines in one view | Full metric set plus source and competitor analysis | Varies by platform |
If you only need to confirm AI data alongside your keyword reports, a suite is enough. If you need to understand why an AI cites a competitor and then act on it, a dedicated platform like Topify covers more of the workflow in one place.
Common Mistakes That Turn Prompt Tracking Into Noise
The most common error is a prompt set that’s too narrow. Tracking five branded queries feels productive, but real buyers ask hundreds of unbranded questions, and that’s where you’re either present or invisible. Build prompt sets around the buyer’s journey, not around your product name.
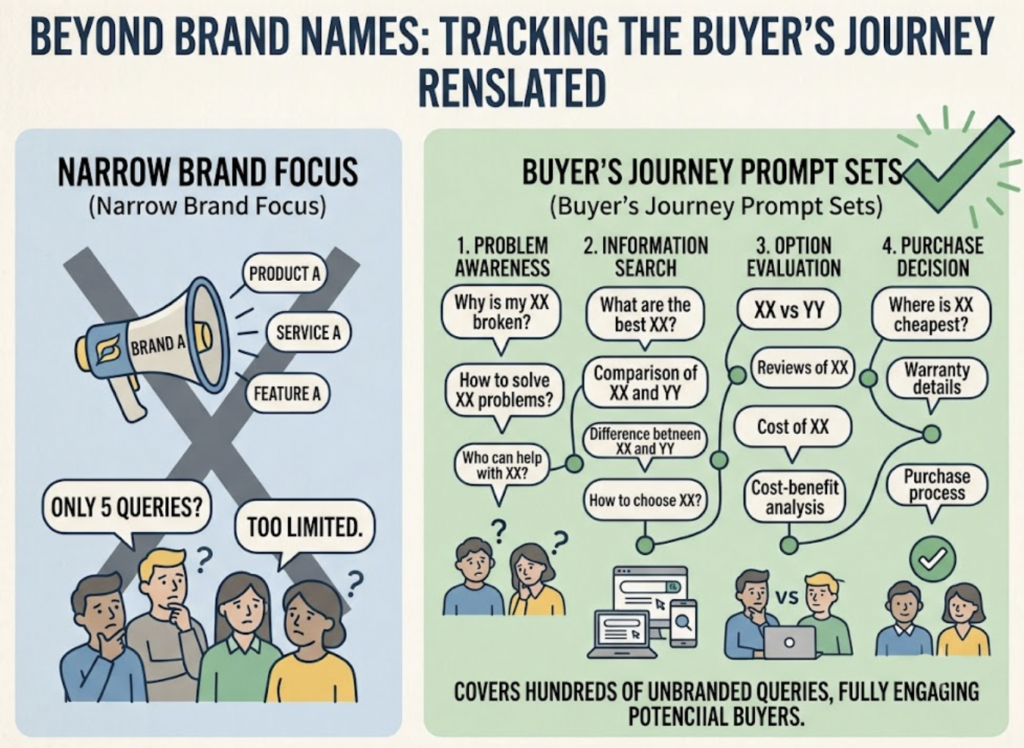
The second mistake is monitoring a single platform. Coverage on ChatGPT says nothing about Perplexity, and the two cite very different sources. Track every engine your audience actually uses.
The third is measuring mentions while ignoring position and source. Being named last in a list of seven is not the same as being the top recommendation, and a dashboard that flattens the two hides the gap. Pull position and citation data, not just a count.
The fourth is letting data go stale. Given weekly churn rates above 50%, a quarterly snapshot is closer to fiction than measurement.
What a Strong AI Prompt Tracking Setup Looks Like in Practice
A working setup starts before the dashboard. You first surface the high-value prompts that actually drive decisions in your category, then watch how the engines answer them, then trace why a given source keeps getting cited. Topify runs this as a connected loop: High-Value Prompt Discovery surfaces the questions worth tracking, Comprehensive GEO Analytics scores your presence across seven metrics including visibility, sentiment, position, and CVR, Dynamic Competitor Benchmarking shows who the engines recommend instead of you, and Reverse-Engineer AI Citations exposes the exact domains feeding those answers. The point isn’t more charts. It’s seeing a drop in ChatGPT mentions and tracing it to a specific source that stopped citing you, inside one view.
This matters because the channel converts. Buyers who arrive through an LLM answer are reportedly 4.4x more likely to convert than traditional search visitors, and with roughly 68% of Google searches now ending without a click, the AI answer is increasingly the only impression a buyer gets.
On price, the entry point is lower than most teams assume. Topify’s Basic plan starts at $99/month with a 30-day trial and covers ChatGPT, Perplexity, and AI Overviews tracking across 100 prompts. If you want to test the loop before committing, you can get started and run your own prompt set first.
A Checklist Before You Commit to a Dashboard
Run any tool through these seven questions before you buy:
- Does it cover every AI engine your audience uses, not just one?
- Does it report position and citation, or only mention counts?
- Can it discover high-value prompts, or do you supply every query yourself?
- Does it track competitors in the same answers, side by side?
- Can it show which source domains feed the AI’s citations?
- Does it run prompts multiple times to confirm consistency?
- Is the pricing transparent, with a trial to validate before you scale?
A tool that clears most of these is measuring the channel. One that doesn’t is mostly counting mentions.
Conclusion
Rankings answer a question buyers stopped asking. The one that matters now is whether an AI engine names you when someone describes their problem, and that’s exactly what an AI prompt tracking dashboard is built to show. Start by listing the 20 to 30 unbranded questions your best customers actually ask, run them across every engine that matters, and watch position and citation, not just mentions. The brands that treat AI visibility as its own measured channel will keep showing up in the answer. The ones still reading green ranking reports won’t know they’ve gone missing.
FAQ
Q: What is an AI prompt tracking dashboard?
A: It’s a tool that monitors how AI engines like ChatGPT, Perplexity, and Google AI Overviews answer a defined set of buyer questions, and records whether your brand is mentioned, recommended, cited, and where it ranks against competitors. Unlike keyword tracking, it measures presence inside generated answers rather than position in a link list.
Q: How do you improve your AI prompt tracking dashboard results?
A: Widen your prompt set to cover unbranded buyer questions, publish content in formats the engines reward (clear data, expert-aligned structure, FAQ and HowTo schema), and use citation analysis to find the source domains that AI engines trust, then earn placement in them. Then re-run and watch position move.
Q: How much does an AI prompt tracking dashboard cost?
A: Pricing ranges widely. Entry-level dedicated platforms start around $99/month, with mid tiers near $199/month for more prompts and seats, and enterprise plans running higher for dedicated support. Most credible tools offer a trial so you can validate coverage before committing.
Q: What does a good AI prompt tracking dashboard example look like?
A: A strong example surfaces high-value prompts automatically, scores visibility across multiple engines and several metrics, places competitor performance next to yours, and traces which source domains drive the citations, all in a single view rather than scattered reports.

