
Your team tracks keyword rankings, traffic, and conversion across thousands of pages. Then a buyer opens ChatGPT, types “best platform for enterprise teams in your category,” and reads a three-sentence answer that names two competitors and skips you entirely. Nobody on your team saw it happen.
Across the hundreds of prompts your customers actually ask AI engines, your brand might show up in twelve of them or in two. Your current dashboards can’t tell the difference. Rank tracking was built for a world of ranked blue links, not synthesized answers, and that’s where enterprise visibility quietly leaks.
What Is AI Prompt Tracking Monitoring
AI prompt tracking monitoring is the systematic measurement of how your brand shows up inside the answers that large language models generate. Instead of asking “where does my URL rank for this keyword,” it asks “when a buyer poses this question to ChatGPT or Perplexity, does the answer mention, cite, or recommend us?”
The shift matters because the mechanics underneath are different. Traditional rank tracking measures static, deterministic positions of links on a results page. Prompt tracking measures a stochastic selection process, where the engine synthesizes a response rather than returning a ranked list.
That changes what “winning” looks like. Visibility is no longer about position one. It’s about whether the model adopts your brand as a trusted resource inside a natural-language answer, and how it frames you when it does.
How AI Prompt Tracking Monitoring Works
At a practical level, AI prompt tracking monitoring runs a structured loop that simulates how real buyers research a category.
It starts with a prompt portfolio. Most enterprise programs curate 20 to 50 category-relevant prompts that mirror genuine buyer intent: “best X for Y,” “X vs. Y,” “how to solve Z.” These aren’t keywords. They’re the full questions a prospect would type.
Next comes cross-platform execution. The same prompts run across ChatGPT, Perplexity, Gemini, Claude, and other engines, because each one has its own citation bias. A brand that dominates Perplexity answers can be invisible in Gemini, and only side-by-side testing surfaces that.
Then the system parses and scores each response on a few specific signals: mention rate (how often the brand appears), citation type (a linked source versus a passing text mention), positioning (named in the summary versus buried deep in a list), and sentiment (framed as positive, neutral, or negative). Those four signals turn a wall of conversational text into something you can actually trend over time.
Examples of AI Prompt Tracking Monitoring in Practice
A few patterns show up constantly once teams start measuring.
A SaaS brand discovers it’s mentioned in every branded prompt but absent from “best tools for [category],” the exact unbranded queries where buyers make shortlists. A retail brand finds Gemini describing it as “budget-friendly” while its positioning is premium. A B2B platform learns a competitor is the only name cited in “X vs. Y” answers, because that competitor published a comparison page and they never did.
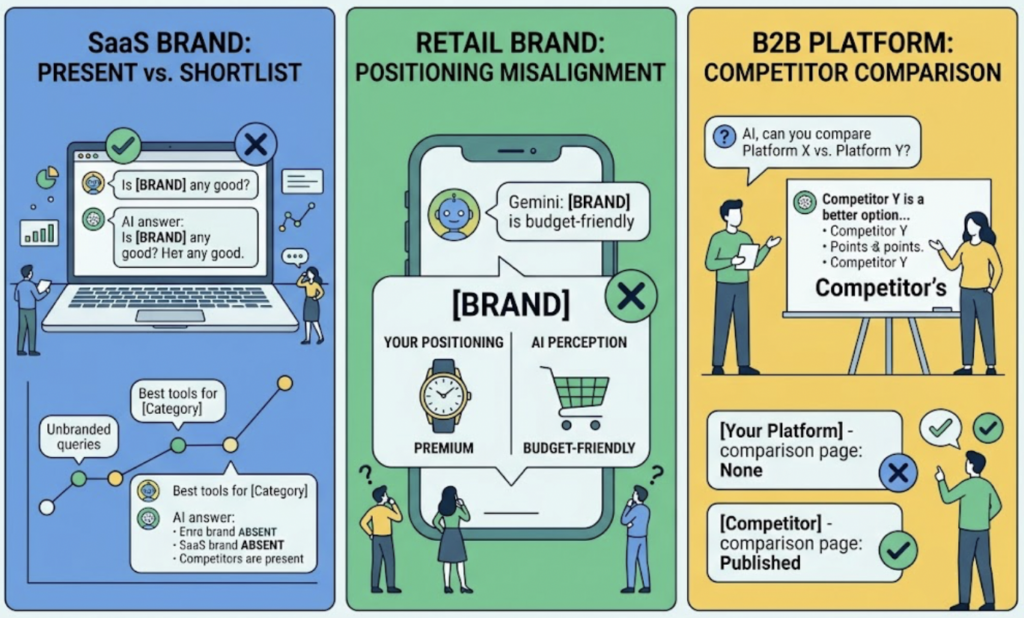
Each of these is invisible to a Google rank report. Each one is obvious the moment you track answers at the prompt level.
How to Measure AI Prompt Tracking Monitoring
Vanity metrics are easy to collect and hard to act on. Enterprise teams that get value out of this work tend to anchor on three measures.
The North Star is AI Share of Voice, calculated as your brand citations divided by total category citations, times 100. It answers the only question leadership really asks: of all the times AI talks about this category, how often is it talking about us?
The second is citation velocity and drift. AI answers aren’t stable. Engines routinely swap out the domains they cite, with some platforms churning a large share of their cited sources week over week. A brand that’s recommended today can vanish next week with no warning, so a single snapshot is close to useless. You’re tracking a trend line, not a screenshot.
The third is sentiment alignment. It’s not enough to be mentioned. You need to confirm the model isn’t pairing your name with negative reviews or citing a competitor as the “authoritative” choice in the same breath. That’s how messaging drift gets caught early.
Why Enterprise AI Visibility Needs Prompt-Level Monitoring
For a small brand, you can almost get away with spot-checking a few prompts by hand. Enterprise visibility is a different problem, and that’s where an enterprise AI visibility platform stops being optional.
Three things break manual tracking at scale.
First is the sheer volume of prompts. A large brand has dozens of product-market combinations, each with its own buyer questions. That’s thousands of prompt-platform pairs, which no spreadsheet survives. Enterprise AI search monitoring solutions handle this by tracking at the topic level rather than asking someone to manage prompts one by one.
Second is context complexity. Global enterprises need a consistent brand voice across markets and product lines, and that data is usually siloed in legacy systems. Enterprise AI visibility, done right, pulls those signals into one view so a regional gap doesn’t hide inside an aggregate number.
Third is operational integration. A serious program treats AI visibility as a leading indicator for content investment. When the data shows “AI isn’t citing us for this use case,” that becomes a direct trigger to build a technical deep-dive page, not a report nobody reads.
Common Mistakes in AI Prompt Tracking Monitoring
Most programs stumble on the same few things.
Over-relying on branded prompts is the big one. Monitoring only your own name paints a flattering picture, because models almost always describe you well when asked about you directly. Real visibility is won in unbranded category queries, where buyers haven’t decided yet.
Ignoring non-determinism is the next. Treating one AI response as fact, without re-testing on a regular cadence, mistakes a probabilistic output for a stable result. Weekly testing is the floor for establishing a reliable trend.
The subtlest mistake is keyword-based thinking. Forcing old SEO habits like exact-match density onto AI answers misreads how the systems work. LLM responses are semantic and narrative. The question isn’t whether your page repeats a phrase, it’s whether the model understands you as the answer.
How to Improve AI Prompt Tracking Monitoring: A Practical Strategy
Once measurement is in place, improvement follows a fairly clean strategy.
Start by building a buyer-intent prompt library instead of chasing volume. A focused set that spans informational, comparative, and problem-solving prompts beats a sprawling list of low-intent queries. Quality of the prompt set, not quantity, is what makes the data actionable.
Then close gaps with evidence. When tracking shows a competitor owning a “best of” prompt, that’s a content brief writing itself: build the page, add the schema, publish the comparison they’re missing. The data tells you exactly where to spend, so content investment stops being a guessing game.
This is also the point where tooling earns its keep. Topify is built around this loop for teams that need it at enterprise scale. Its Comprehensive GEO Analytics tracks brand performance across major AI platforms through seven metrics: visibility, sentiment, position, volume, mentions, intent, and CVR. In practice, that means you can spot a drop in ChatGPT mentions, trace it to a source that stopped citing you, and see which competitor took your spot, all in one place.
Two capabilities matter most for prompt-level work. High-Value Prompt Discovery surfaces the prompts that actually move your category as AI recommendations evolve, so your portfolio stays current instead of going stale. Dynamic Competitor Benchmarking shows who the engines recommend ahead of you and where, which turns a vague “we’re losing ground” feeling into a specific, fixable list. When you’re ready to map your own prompt coverage, you can get started with Topify and run a baseline before committing to a plan.
Choosing the Right Enterprise AI Visibility Tool
The market is crowded, and most tools differ less in their dashboards than in what they actually measure. When you’re comparing the best tools for AI prompt tracking monitoring, these are the dimensions that separate them.
| Dimension | What to look for | Why it matters for enterprise |
|---|---|---|
| Platform coverage | Tracks ChatGPT, Perplexity, Gemini, Claude, and more | Single-engine tools miss where your buyers actually search |
| Prompt scale | Topic-level tracking, hundreds of prompts | Manual prompt management collapses at enterprise volume |
| Metric depth | Beyond mention rate to position, sentiment, SOV, CVR | Mention-only data can’t explain why visibility moves |
| Competitor benchmarking | Automatic rival detection and positioning | You need to know who’s winning the prompts you’re losing |
| Actionability | Citation analysis that points to content gaps | Monitoring without a next step is just a report |
The pattern is simple. Tools that stop at “here’s your mention rate” leave the hardest work, figuring out what to do next, on your desk. The ones worth paying for connect measurement to a content action.
Conclusion
The gap from the opening doesn’t close on its own. Every week, AI engines answer your category’s questions, name some brands, and skip others, and without prompt-level tracking you’re guessing which side you’re on.
Start small. Build a focused prompt library around real buyer intent, run it across the platforms your customers use, and measure share of voice and sentiment on a weekly cadence. From there, let the gaps drive your content roadmap. The enterprises that treat AI visibility as a measurable channel, not a mystery, are the ones AI will keep recommending.
FAQ
Q: What is AI prompt tracking monitoring?
A: It’s the practice of measuring how your brand appears inside AI-generated answers across engines like ChatGPT, Perplexity, and Gemini. Rather than tracking where a URL ranks, it tracks whether the model mentions, cites, or recommends you when a buyer asks a real question, and how it frames you when it does.
Q: What’s a good checklist for AI prompt tracking monitoring?
A: A practical checklist covers five things: a buyer-intent prompt portfolio of 20 to 50 questions, cross-platform execution across at least three engines, scoring on mention rate plus position and sentiment, a weekly re-testing cadence to handle non-determinism, and a clear link from each gap to a content action.
Q: How much does AI prompt tracking monitoring cost?
A: Pricing varies widely by prompt scale and platform coverage. Topify’s plans start at $99/month for the Basic tier, scale to $199/month for Pro, and move to custom Enterprise pricing from $499/month with a dedicated account manager. You can review current tiers on Topify’s pricing page.
Q: How is it different from traditional SEO rank tracking?
A: Rank tracking measures fixed positions of links on a search results page. Prompt tracking measures a probabilistic answer that the model writes fresh each time, so success is defined by citation and recommendation rather than position, and results shift week to week instead of staying static.

