
Your team opens ChatGPT, types in your category’s top question, and screenshots whether your brand shows up. Then Perplexity. Then Gemini. Then again next week, because the answers keep moving. Tracking even 50 prompts across three AI platforms this way burns dozens of hours a week, and the spreadsheet you’re building is stale before you finish it.
The harder problem isn’t checking once. It’s knowing whether what you saw was a real trend or just model noise.
What an AI Prompt Tracking Solution Actually Monitors
Start with the word “prompt,” because it confuses people. An AI prompt tracking solution has nothing to do with prompt engineering or writing instructions for a model. It tracks the outputs of real user queries, the high-intent questions buyers actually ask AI tools, like “best [category] software” or “[your brand] vs [competitor].”
The job is to audit how the AI answers those questions, at scale, over time.
A useful way to frame it: a strong solution measures four things about every tracked prompt. Is your brand present in the answer at all? Is it prominent, meaning where does it land in the list? Is it persuasive, meaning how does the model frame you, premium or budget, enterprise or complex? And is it cited, meaning which external sources, like G2, Reddit, or Wikipedia, does the AI lean on to validate the recommendation?
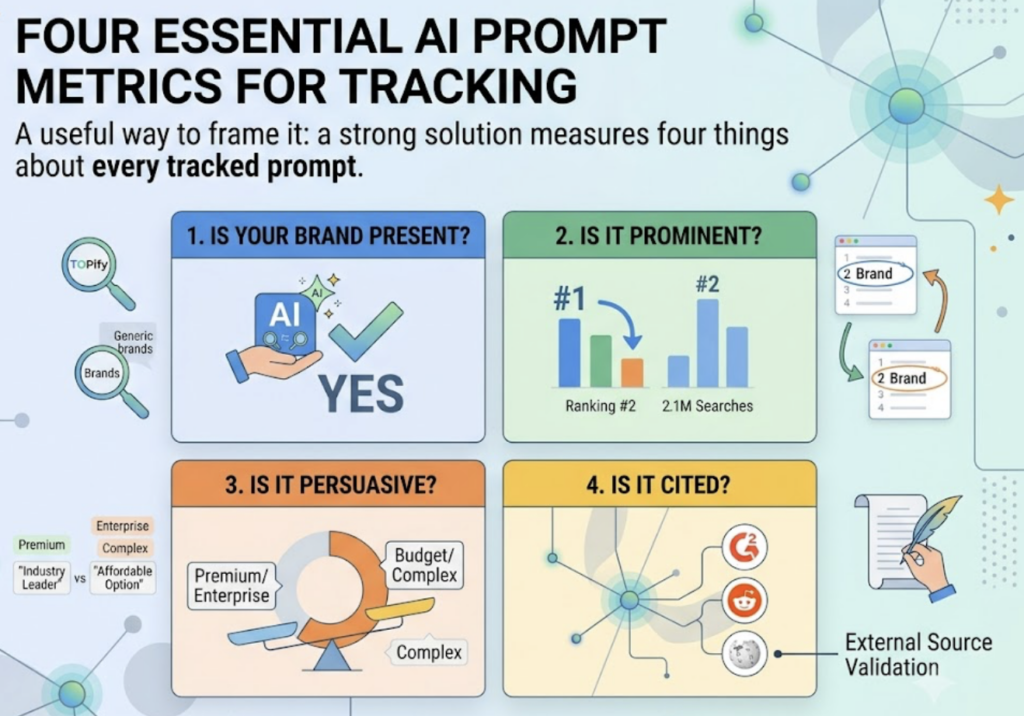
That fourth dimension is the one most teams skip. It’s also where the leverage is.
Why Manual AI Prompt Tracking Falls Apart Fast
Manual, spreadsheet-based tracking hits three walls that no amount of effort fixes.
The first is volatility. LLMs are probabilistic, not deterministic. Even with temperature pinned low, responses still drift between runs, so a single manual spot-check captures one data point when actual visibility is a distribution. You need a rolling average, a 7- or 30-day window, to separate a meaningful shift from random variance.
The second is scale. Checking a modest cluster of 50 prompts across three engines, every week, eats dozens of hours of senior marketing time. That’s expensive labor spent copying answers into cells.
The third is the snapshot trap. AI platforms update their indexes and reasoning logic constantly, so today’s screenshot is often obsolete within days.
Treat AI performance like a static SEO rank and you’ll spend your time chasing noise instead of driving growth.
That’s the gap a real system is built to close.
What a Real AI Prompt Tracking Tool Has to Measure
Most dashboards reduce AI visibility to a single number. A serious AI prompt tracking tool refuses to do that, because one number hides everything you’d actually act on.
Here’s what the analytics layer has to break out.
Visibility, Position, and Sentiment in One View
Visibility rate is the share of relevant AI answers that mention your brand at all. It’s the baseline, not the finish line.
Position, or salience, is the order of mention. This one matters more than it looks. AI models tend to weight the first 30 to 40% of an answer most heavily, so being named last in a list of seven is closer to invisible than it feels.
Sentiment, or framing, is the qualitative read: does the model call you “the enterprise option” or “a cheaper alternative”? Two brands can share the same visibility rate while one gets described in language that quietly kills deals.
Source-Level Analytics, Not Just a Dashboard Number
Then there’s source attribution, the citation supply chain. This tracks which domains feed the AI’s answer about your category.
It reframes the whole problem. If an AI cites a specific review site or industry journal when recommending tools in your space, your real optimization target isn’t only your own domain. It’s earning presence on the sources the model already trusts. A dashboard that shows your visibility score but hides which sources moved it leaves you optimizing blind.
From Dashboard to Platform: What a Complete AI Prompt Tracking System Does
Measurement is table stakes. The reason to graduate from a basic tool to a full AI prompt tracking platform is execution, turning the data into a decision you can ship the same day.
This is where Topify is built differently. Instead of stopping at rows in a database, it runs a closed loop from discovery to action.
It starts with High-Value Prompt Discovery. Rather than asking you to guess which 50 prompts to track, the system surfaces high-volume questions in your category where your brand is currently dark, then keeps surfacing new ones as AI recommendation patterns shift. You’re not maintaining a static prompt library by hand.
From there, the analytics run across seven dimensions, visibility, sentiment, position, volume, mentions, intent, and CVR, so a drop in ChatGPT mentions can be traced to a specific cause rather than logged as a mystery.
Competitor benchmarking sits in the same view. You see your share of voice against rivals at the individual prompt level, which is far more useful than a category-wide average, plus emerging competitors as AI starts naming them.
The source layer is what ties it together. The platform reverse-engineers the exact domains and URLs the AI cites, so if a competitor is being referenced by a publication that ignores you, the gap maps straight to a content target. From there, you can move on a strategy with one-click execution instead of routing findings through three more meetings.
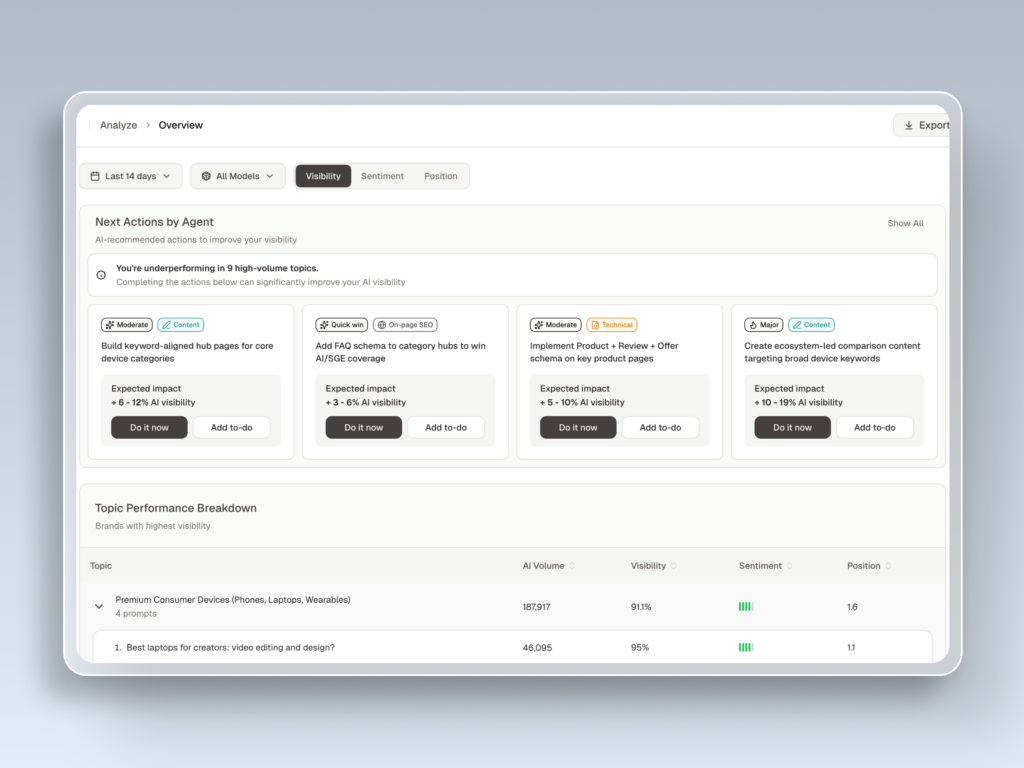
For a marketing team, the practical difference is simple. A monitoring dashboard tells you that you’re losing. A complete system tells you where, why, and what to publish next.
You can get started with Topify on a 30-day trial that covers ChatGPT, Perplexity, and Google AI Overviews tracking.
Build Your Own AI Prompt Tracking System or Buy One?
If you have engineers, building an in-house AI prompt tracking software stack looks tempting. Query a few model APIs, parse the responses, store the results. How hard could it be?
Harder than it looks, and the cost is mostly hidden. The build versus buy math rarely favors building once you account for ongoing maintenance rather than the first prototype.
| Factor | Self-built system | Specialized platform |
|---|---|---|
| Data integrity | Fragile APIs, growing maintenance debt | Scalable, high-availability architecture |
| Engine coverage | Hard to sustain across 5+ platforms | Cross-platform sync out of the box |
| Hidden costs | Engineering time, API spend, cloud overhead | Predictable subscription |
| Actionability | Often ends as data silos | Built-in gap and content analysis |
The pattern most teams hit is the data-silo trap. The pipeline works, the numbers land in a database, and then nobody has time to turn rows into decisions because they’re busy keeping the pipeline alive.
Bottom line: for most teams, buying frees you to spend your hours applying the data, citation building, content pruning, repositioning, instead of repairing infrastructure.
Conclusion
AI visibility is the new baseline, and you can’t manage what you only glance at once a week. The path forward is concrete: define a library of 25 to 50 decision-stage prompts, measure where your brand is currently invisible, audit which sources feed the AI’s recommendations, then move to a tool-based system so you’re watching trends instead of snapshots.
The goal isn’t a prettier dashboard. It’s knowing, with enough confidence to act, exactly where your brand stands the next time a buyer asks an AI for a recommendation.
FAQ
Q: What are the best tools for monitoring brand visibility in AI search results?
A: Look for a tool that tracks across multiple engines (ChatGPT, Perplexity, Gemini, Google AI Overviews) rather than one, breaks visibility into position and sentiment instead of a single score, and shows the sources behind each answer. Platforms like Topify combine prompt-level tracking with source analysis and competitor benchmarking in one place.
Q: What are AI search optimization tools?
A: They’re platforms that measure and improve how AI engines represent your brand in their answers, often called GEO (Generative Engine Optimization) or AEO tools. Unlike traditional SEO software focused on Google rankings, they track mentions, citations, and framing inside generative responses.
Q: What are the best tools for monitoring generative AI search results?
A: The strongest options monitor a defined prompt set continuously, use rolling averages to filter out model noise, and connect findings to action, like flagging which content or citations to build next. Continuous monitoring matters more than a one-time audit because generative answers shift week to week.
Q: What are the best AI search optimization tools for improving brand visibility?
A: Prioritize tools that close the loop between data and execution. Tracking alone shows where you’re invisible; the ones that move the needle also surface high-value prompts, map citation gaps to specific sources, and let you act on a strategy quickly rather than just exporting a report.

