
Your team can pull domain authority, keyword positions, and organic traffic in about thirty seconds. Then someone in the room asks whether your brand showed up when a buyer typed your category into ChatGPT, and the report goes quiet. Traditional SEO tools were built to measure a ranked list of links, not whether you’re part of a synthesized answer. That gap is where AI prompt tracking lives, and most teams don’t realize how wide it’s gotten until a competitor’s name is the one the model keeps recommending.
What AI Prompt Tracking Actually Means, and Why Rankings Don’t Apply
AI prompt tracking is the systematic monitoring of how your brand shows up inside the natural-language responses that generative engines produce. The question shifts from “where do we rank” to “are we part of the answer” that ChatGPT, Perplexity, or Google’s AI Overviews hand the user.
That shift matters because the two systems behave differently. Classic search is deterministic: the same query returns roughly the same ranked list. AI search is probabilistic. The model runs a query fan-out, breaking one prompt into sub-questions, pulling from multiple sources, and synthesizing a fresh response each time.
So your brand can headline the answer in one run and disappear in the next. None of that surfaces in a rankings report.
The stakes are concrete. Organic click-through rate falls 61% on queries where an AI Overview appears, while brands cited inside that overview see click-through about 35% higher than the page’s normal rate. Presence in the answer isn’t a vanity metric. It’s the difference between earning the click and watching it evaporate.
How AI Prompt Tracking Works Under the Hood
Page crawlers don’t work here. There’s no fixed results page to scrape, so AI prompt tracking relies on structured probing: feeding defined prompts into each engine and parsing the response the way a real user would receive it.
The hard part is volatility. In SE Ranking’s local search test, only about 35% of domains repeated when the same prompt ran multiple times from the same location. Broader runs show more than 60% of domains and 80% of URLs vanishingbetween sessions. A single snapshot tells you almost nothing.
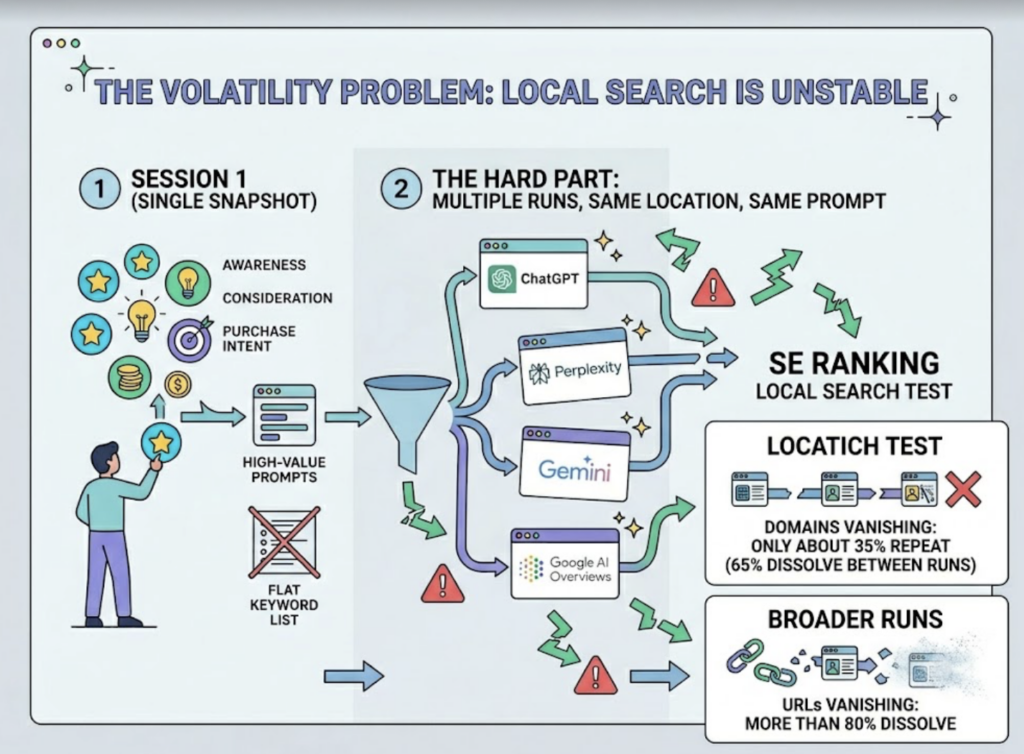
That’s why credible systems use repeated sampling. They run each prompt many times across accounts and locations, then average the results into a visibility score that’s statistically stable instead of a lucky screenshot.
The fan-out adds another layer. When the engine decomposes a master prompt into sub-queries, a good tracker watches which sub-topics the model associates with your brand, not just whether your name appears once.
How to Measure AI Prompt Tracking: The Metrics That Matter
Counting raw mentions is the trap most teams fall into. A useful measurement framework tracks five metrics together, because each one answers a different question.
| Metric | What it tells you |
|---|---|
| Mention Rate | The share of your tracked prompts where the brand gets named at all |
| Citation Share | How often the engine links to your site, which drives referral traffic |
| Average Position | Where you land in the AI’s ordered list of recommendations |
| Sentiment | Whether the model frames you as positive, neutral, or negative |
| Share of Voice | Your mentions relative to a defined competitor set across the same prompt cluster |
The signal hiding in this table is the gap between mention rate and citation share. If AI names you often but rarely cites your page, that usually points to a structural problem on your site: missing schema, thin information architecture, or content the model can’t confidently treat as a source of truth.
This is also where ai search trackers earn their keep. Pulling five metrics by hand across three engines, repeated often enough to beat the volatility, isn’t realistic. The tooling exists to automate the sampling and turn it into something you can report on weekly.
How to Improve AI Prompt Tracking, and the Mistakes That Quietly Sink It
Improving your numbers starts with not sabotaging them. A few mistakes show up again and again.
The dashboard trap is the most common. Tracking “total monthly mentions” with no denominator and no competitor context produces a number that climbs as the AI ecosystem grows, not as your performance improves. It feels like progress and measures nothing.
Siloing GEO from SEO is the second. AI engines lean on the same E-E-A-T signals (expertise, experience, authoritativeness, trustworthiness) that Google’s classic systems reward, so treating AI visibility as a separate discipline wastes the authority you’ve already built.
The third is ignoring source accuracy. Models often describe brands using stale or wrong data from their retrieval index, which is why entity audits, checking that the AI understands your products, founders, and positioning, belong in the workflow.
On the improvement side, structure does heavy lifting. 44.2% of LLM citations come from the first 30% of a page’s text, and structured formats like clear headings, lists, and FAQ blocks tend to get pulled more often than dense prose. Put your answer up top, mark it up cleanly, and you make it easy for the model to quote you.
A Quick AI Prompt Tracking Checklist
If you’re building a process from scratch, this is the short version:
- Curate a high-value prompt repository by intent (procedural, comparative, problem-solving) instead of tracking every keyword.
- Standardize the query environment, including location when it’s relevant, to cut baseline noise.
- Run each prompt multiple times and average, rather than trusting one response.
- Track mentions and citations together, and earn the name-drop before chasing the link.
- Benchmark against a fixed competitor set so your share of voice means something.
- When a rival gets cited and you don’t, run a diff on their page structure, schema, and content depth.
Best AI Search Trackers 2026: What to Look for in a Prompt Tracking Tool
When you start comparing the best AI search trackers 2026 has to offer, the useful filter is simple: look for a visibility system, not a reporting dashboard. A dashboard shows you numbers. A system tells you why the engine chose one source over another and what to do about it.
Three capabilities separate the two. Cross-engine coverage, so you’re watching ChatGPT, Perplexity, and AI Overviews at once rather than one platform in isolation. Competitor benchmarking, so every metric reads as relative performance inside a peer group. And actionable attribution, so the tool can point at the page structure, schema, or content depth that earned a citation.
This is where Topify fits the brief. It runs prompt-level tracking across the major engines and folds visibility, position, sentiment, and source analysis into a single view, so a drop in ChatGPT mentions can be traced back to the specific source that stopped citing you.
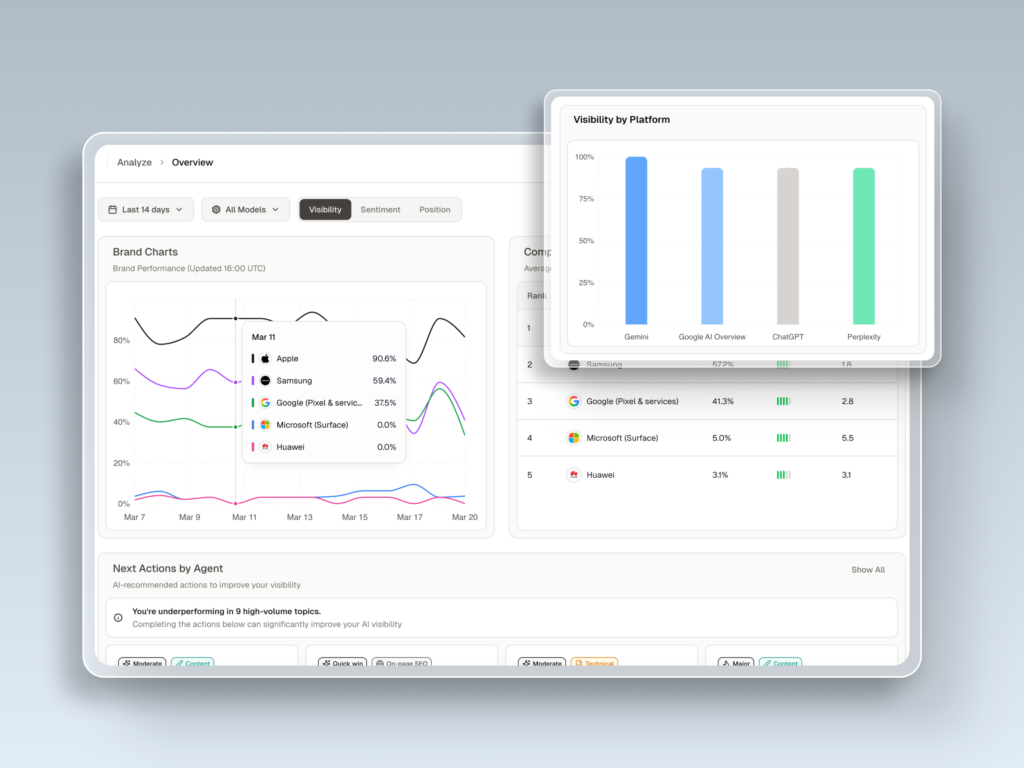
Its High-Value Prompt Discovery is the part most reporting tools skip. Instead of waiting for you to guess which prompts matter, it surfaces the high-volume questions in your category and watches how the answers shift, which moves a team from passive monitoring toward proactive content work. Competitor Monitoring then shows who the engines recommend ahead of you, and where the gap sits.
On cost, plans start at $99 a month and scale by prompt volume and seats, with usage-based tiers rather than inflated enterprise bundles. Other platforms cover slices of this well, but the payoff of a single connected view is that you stop stitching three tools together to answer one question. You can get started without committing to a year up front.
Conclusion
The quiet moment in that meeting, when the rankings report can’t say whether you showed up in the AI answer, isn’t going away on its own. It widens every quarter as more buyers start their research inside a chatbot instead of a search bar.
The fix isn’t complicated to start. Define a small set of high-intent prompts, run them across ChatGPT, Perplexity, and AI Overviews a few times each, and see where you actually stand. Once you can measure it, you can improve it, and that’s the whole point of AI prompt tracking.
FAQ
Q: What is AI prompt tracking? A: It’s the practice of monitoring whether and how your brand appears inside generative AI responses, prompt by prompt, across engines like ChatGPT, Perplexity, and Google AI Overviews. Instead of measuring keyword rank, it measures presence in the synthesized answer the user actually reads.
Q: What are some examples of AI prompt tracking in practice? A: Running “best tools for [your category]” across three engines fifty times and recording how often your brand is named, tracking whether Perplexity cites your pricing page versus a competitor’s, or watching your average position drop after a model update. Each is a prompt tracked, sampled, and scored over time.
Q: What do AI search trackers typically cost? A: Pricing varies by prompt volume, engine coverage, and seats. Entry tiers tend to start around $99 a month for a capped set of prompts and projects, with higher plans scaling sampling and competitor coverage. Usage-based pricing generally beats fixed enterprise bundles for teams still sizing their prompt set.
Q: What are the most common mistakes in AI prompt tracking? A: Reporting total mentions with no denominator or competitor context, treating GEO as separate from SEO when both reward the same E-E-A-T signals, and trusting a single snapshot despite the volatility that makes most results shift between runs.

