
Your team spent six months building domain authority, earning backlinks, and climbing Google’s first page. Then a prospect typed “best tool for [your category]” into ChatGPT and got five recommendations. Your brand wasn’t one of them. The gap between traditional search rankings and AI-generated answers is growing every quarter, and most marketing teams don’t have a system to detect it. Google rankings tell you where your pages sit in an index. They can’t tell you what a language model chooses to say about your brand, or whether it mentions you at all.
That gap is where an AI answer monitoring strategy comes in.
What an AI Answer Monitoring Strategy Actually Covers
So, what is an AI answer monitoring strategy? It’s a systematic, automated framework designed to track, analyze, and optimize how a brand is mentioned, described, and cited inside AI-generated responses across multiple large language models.
This isn’t about checking ChatGPT once a week. It’s about continuously probing conversational engines to measure five dimensions of brand presence: visibility frequency, sentiment quality, recommendation position, citation source mapping, and competitive share of voice.
The scale of the opportunity makes this urgent. ChatGPT alone processes roughly 2.5 billion daily prompts, with about 31% triggering live web searches. That’s over 775 million web-driven queries every day, capturing a significant chunk of traditional search volume. Meanwhile, 31% of Gen Z users now start searches on AI-native platforms instead of Google.
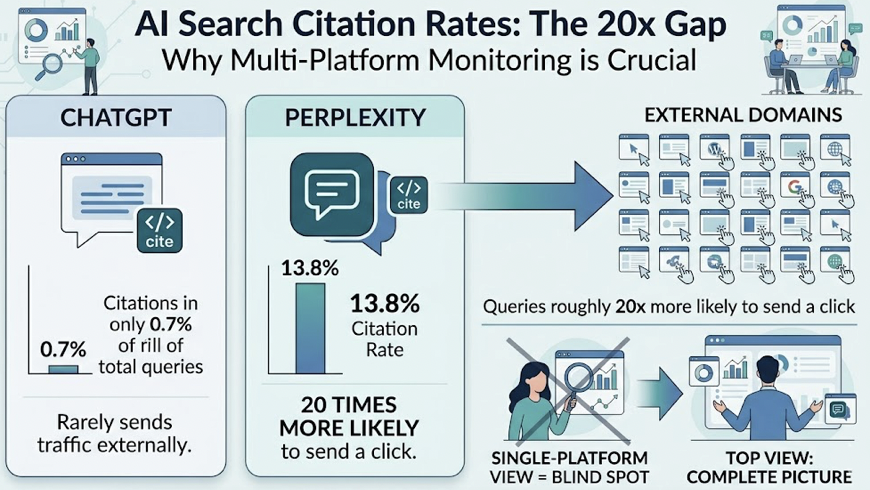
Here’s what makes this tricky: the engines don’t all behave the same way. ChatGPT cites external sources in only about 0.7% of its total queries. Perplexity, on the other hand, shows a 13.8% citation rate, making its queries roughly 20 times more likely to send a click to an external domain. A strategy that only monitors one platform is a strategy with a blind spot.
The concept of the “crawl-to-referral ratio” makes this even starker. For every single referral click OpenAI sends back to a publisher, its crawlers access 1,155 pages. For Anthropic’s Claude, that ratio jumps to 10,347:1. Generative engines consume vast amounts of content while returning minimal organic traffic. If your content is crawled but never cited in the final AI response, your brand is invisible.
Why Manual Spot-Checks Don’t Count as a Strategy
The most common of the common mistakes in AI answer monitoring strategy is treating occasional manual searches as a monitoring program. A marketer types a high-priority query into ChatGPT, sees the brand name in the response, and moves on. That approach introduces three serious blind spots.
Coverage gaps. One person can only test a fraction of the conversational pathways customers actually use. Different audience segments phrase questions in wildly different ways, triggering entirely different AI response structures. And checking only ChatGPT ignores how Gemini, Perplexity, and Google AI Overviews handle the same topic.
Temporal blindness. LLMs, real-time indexes, and RAG architectures update dynamically. A model might recommend your brand at 9 AM and drop it by 3 PM due to silent retraining, cache refreshes, or retrieval threshold adjustments. A single weekly check can’t capture that volatility.
Dimensional shallowness. Manual checks only confirm whether a brand appears. They can’t measure how the AI describes the brand, where it ranks in a recommendation list, or which sources power that recommendation.
The numbers back this up. Manual checks miss up to 55% of negative sentiment instances, which often surface only at higher temperature variations in the model’s probability distribution. Single-shot scraping captures one point in that distribution. A stateless, multi-shot probing system captures the full picture.
That’s the difference between a spot-check and a strategy.
5 Metrics That Separate a Real AI Answer Monitoring Strategy from Guesswork
To understand how to measure AI answer monitoring strategy performance, teams need to track five distinct operational pillars. Each one captures a different dimension of brand health inside generative answers.
1. Visibility Tracking. This measures the probability and frequency of your brand’s inclusion across ChatGPT, Gemini, Perplexity, and other leading LLMs. Unlike traditional SEO impressions, visibility here is probabilistic. The goal is to calculate your brand’s recommendation percentage across hundreds of semantic prompt variations to establish a reliable baseline.
2. Sentiment Analysis. AI platforms don’t just list links. They actively describe, compare, and critique products. A brand can have high visibility but poor sentiment if training data is outdated or negative reviews dominate the model’s context. Tracking sentiment on a scale from -100 to +100 lets teams verify that mentions are actually positive.
3. Position Monitoring. Clicks in generative search are heavily concentrated at the top. Within Google’s AI Overviews, the first cited source captures 47% of all clicks, the second gets 23%, and the third gets 14%. Any citation outside the top three, or buried inside a “Show more” section, sees a 68% drop in click-through rate. Position isn’t a vanity metric here. It’s the difference between traffic and invisibility.
4. Source and Citation Analysis. LLMs build credibility by citing authoritative references. About 78% of Google AI Overviews cite at least one .edu, .gov, or .org domain, and Reddit or Quora serves as a supporting source in 14% of cases. Tracking which domains the AI trusts helps brands target their digital PR and off-site content.
5. Competitor Benchmarking. This measures your brand’s share of model relative to direct competitors. By evaluating who wins the citation across high-value prompt groups, you can spot visibility gaps where competitors dominate AI recommendations and plan tactical moves to close them.
A solid checklist for AI answer monitoring strategy implementation covers all five. Skip one, and you’re flying partially blind.
How to Build Your AI Answer Monitoring Strategy from Scratch
Knowing the pillars is one thing. Building the system is another. Here’s how to improve AI answer monitoring strategy execution in five concrete steps.
Step 1: Identify your core prompt clusters. Shift from rigid short-tail keywords to natural, conversational prompts. Your customers aren’t typing “CRM software” into ChatGPT. They’re asking things like “Compare security features of enterprise cloud storage for financial compliance.” Use conversational keyword research to discover these high-value prompt pathways and cluster them by commercial intent.
Step 2: Define platform coverage. Decide which AI engines matter most for your audience. For general consumer demographics, ChatGPT and Gemini are primary. For B2B professional audiences, Perplexity tends to carry more weight. Google AI Overviews should be tracked regardless, since they directly intercept organic SERP traffic.
Step 3: Establish baselines with statistical probing. This is where most teams either get it right or stay stuck in guesswork. Single-shot scraping won’t cut it. A platform like Topify runs stateless, multi-shot probing (N≥50 per prompt) that bypasses personalization and location bias. This gives you a clean, regionalized baseline of visibility, sentiment, and position across every tracked engine.
Step 4: Set cadence and audit for model drift. Silent updates to embedding models, RAG retrieval thresholds, or token budgets can shift which brands get prioritized overnight. Weekly audits catch these shifts before they impact pipeline revenue.
Step 5: Define action triggers. Connect your tracking data to content optimization workflows. When the dashboard flags a visibility drop, it should trigger a specific response: audit the citation trail, identify the gap, and deploy content updates. Topify’s AI agent automates this loop with one-click execution, restructuring pages and publishing updates directly to your CMS.
What do successful examples of AI answer monitoring strategy look like in practice? Consider a SaaS brand that discovers it’s excluded from ChatGPT’s recommendations for “easiest CRM software.” By auditing the citation trail, they find the AI relies heavily on Reddit threads and G2 comparison pages. The brand then seeds authentic customer discussions on Reddit, optimizes its G2 profile, and applies GEO techniques to its own site. Research from the Princeton GEO study shows that incorporating expert quotations can boost visibility by 41%, adding specific statistics by 37%, and citing authoritative sources by 30%. These are the kinds of structural improvements that move the needle.
Picking the Right AI Answer Monitoring Tool for Your Strategy
You can’t run a strategy on spreadsheets and manual ChatGPT searches. At some point, you need an AI answer monitoring tool that matches the scope of what you’re tracking. Here’s what to evaluate, and how the leading AI answer monitoring software options compare.
The core standards for any AI answer monitoring platform: multi-engine coverage (ChatGPT, Gemini, Perplexity, Claude, DeepSeek), stateless multi-shot probing to eliminate personalization bias, a sentiment engine that goes beyond binary positive/negative, citation gap analysis, and automated content workflows.
| Feature | Topify | Profound | Goodie AI | Semrush AI | Otterly.ai |
|---|---|---|---|---|---|
| Platform Coverage | ChatGPT, Gemini, Perplexity, Claude, DeepSeek | All major enterprise LLMs | ChatGPT, Google | Google SGE / AI Overviews | ChatGPT, Google |
| Probing Method | Multi-shot (N≥50) | Complex multi-turn | Single-shot | Single-shot | Simple single-shot |
| Data Accuracy | 98% (Tier 1) | High (enterprise-grade) | Medium | Medium | <60% |
| Sentiment Engine | Proprietary NLP (-100 to +100) | Standard categorization | Basic | Basic | None |
| Citation Gap Audit | Yes (reverse-engineers sources) | Yes (revenue attribution) | Basic | Correlation data | None |
| Automated Workflows | One-click AI agent | CMS execution | Content rewriting | Keyword lists | None |
| Pricing | $99/mo Basic, $199/mo Pro | Premium enterprise | Custom | Mid-tier add-on | From $49/mo |
Topify stands out as the AI answer monitoring solution built natively for the generative search era. Its Tier 1 elastic probing engine achieves 98% accuracy by running stateless, multi-shot probes that eliminate personalization and location biases. The proprietary sentiment engine scores brand presence on a -100 to +100 scale, and the unified dashboard monitors five major AI platforms simultaneously. The one-click AI SEO Agent automates the full loop from insight to content update. At starting from $99/month, it offers strong ROI for mid-market and enterprise teams alike.
Profound targets Fortune 500 companies with deep Adobe Analytics and Tableau integrations. It’s powerful for tracking millions of SKUs across regions, but the high price tag and steep learning curve make it less suited for agile marketing teams.
Goodie AI combines tracking with generative content rewriting, but its monitoring capabilities are less granular, especially for non-Google conversational engines.
Semrush AI works well as a bridge for teams already in the Semrush ecosystem, showing how organic rankings correlate with AI Overviews. But it focuses primarily on Google, leaving gaps if your audience uses Perplexity or Claude.
Otterly.ai offers budget-friendly tracking starting at $49/month, suitable for startups. It lacks sentiment analysis, multi-engine probing, and automated workflows.
When evaluating AI answer monitoring strategy pricing, match the tool’s capabilities to your monitoring scope. A startup tracking 20 prompts across two platforms has different needs than an enterprise monitoring 500 prompts across five engines.
What a Working AI Answer Monitoring Dashboard Looks Like in Practice
An AI answer monitoring dashboard isn’t just a reporting screen. It’s the operational nerve center where strategy turns into weekly action.
Here’s a concrete scenario. A SaaS marketing manager opens their Topify dashboard on Monday morning. They scan the visibility and sentiment trends across their tracked prompt clusters. One thing jumps out: a 15% drop in Perplexity visibility for queries around “most secure enterprise file sharing.”
Instead of manually searching for the cause, they click into the citation tracker. The dashboard reveals that Perplexity has adjusted its retrieval parameters. It’s no longer citing the brand’s primary product page. Instead, it’s pulling from a third-party cybersecurity directory that highlights a competitor’s SOC-2 compliance data. The competitor has also deployed schema markup on their page, which can increase citation frequency by up to 89%.
The response takes minutes, not weeks. Using Topify’s integrated AI SEO Agent, the manager triggers an automated page restructure: a concise 50-word direct answer block at the top of the page, verified encryption statistics, an expert quote from the CISO, and structured FAQ schema with sameAs identity links. One click publishes the updates to WordPress.
Within 48 hours, Topify’s multi-shot probing engine confirms Perplexity has updated its retrieval cache. Visibility is restored. Sentiment rises back to 88. High-converting referral traffic ticks up 5%.
That’s what a closed-loop AI answer monitoring system looks like in practice. Not a report you read. A workflow you act on.
Conclusion
The shift from indexed search results to AI-synthesized answers isn’t a trend. It’s a structural change in how customers discover brands. Monitoring Google rankings while leaving your representation in ChatGPT, Perplexity, and Gemini unmanaged creates a gap that widens every quarter.
An effective AI answer monitoring strategy closes that gap with a continuous loop: identify high-value prompts, establish baseline metrics with multi-shot probing, track visibility and sentiment across engines, and automate content updates when citations shift. Start with your top 10 prompt clusters and build your baseline with Topify. The brands that move first are the ones AI learns to recommend.
FAQ
Q: What is an AI answer monitoring strategy?
A: It’s a systematic framework for tracking, analyzing, and optimizing how your brand is mentioned, described, and cited inside AI-generated responses across multiple LLMs. Instead of monitoring static keyword rankings, it uses automated probing to measure visibility, sentiment, position, citations, and competitive share of voice in conversational search.
Q: How do you measure the success of an AI answer monitoring strategy?
A: Through a composite of generative KPIs: your brand’s share of model across high-intent prompt clusters, the sentiment score of synthesized mentions, the frequency and position of citation links, and the volume of AI-referred sessions captured in your web analytics.
Q: What’s the difference between AI answer monitoring and traditional SEO tracking?
A: Traditional SEO tracks deterministic keyword rankings on a single platform like Google. AI answer monitoring operates in a probabilistic environment across multiple LLMs, accounting for real-time model updates, geographic personalization, and retrieval-augmented generation. It measures how multiple web sources are combined into unified answers, not just where a page ranks.
Q: How much does an AI answer monitoring strategy cost to implement?
A: Entry-level monitoring for small teams starts around $49/month. Mid-to-enterprise implementations using platforms like Topify range from $99 to $199/month. Large-scale global enterprises with custom data integrations and revenue mapping typically invest in premium contracts.

