
Your robots.txt tells crawlers what not to touch. Your sitemap tells indexers where everything lives. But neither one tells an AI model what your site is actually about, what it should prioritize, or how to represent your brand accurately in a generated answer.
That’s the gap llms.txt was built to fill.
The File Search Engines Never Needed, But AI Does
Since 1994, robots.txt has been the standard handshake between websites and automated programs. Its logic is defensive: it defines what crawlers shouldn’t access. That was enough for the keyword-indexing era.
Large language models work differently. Systems like ChatGPT, Perplexity, and Claude don’t just index pages. They read, synthesize, and generate answers, often from a limited context window where every token counts. A typical HTML page is packed with navigation menus, JavaScript, tracking scripts, and visual rendering logic that AI systems have to parse before reaching the actual content. That processing isn’t free.
Token economics matter here. In a large language model, processing 1,000 tokens costs a fixed amount of compute. If 80% of a webpage is structural noise, the model spends 80% of its budget on content that doesn’t answer the user’s question. llms.txt solves this by offering a clean, pre-curated Markdown file that strips away everything except what’s essential.

The result: compared to raw HTML, llms.txt can reduce token consumption by over 90%.
| Protocol | Core Logic | Primary Audience | Format | Purpose |
|---|---|---|---|---|
| robots.txt | Access control | Search engine crawlers | Plain text directives | “Don’t crawl this” |
| sitemap.xml | Inventory | Search engine indexers | XML URL list | “Everything lives here” |
| llms.txt | Content guidance | LLMs, AI agents, RAG systems | Structured Markdown | “Here’s what matters and why” |
What’s Actually Inside an llms.txt File
llms.txt is a standard Markdown file placed at your root domain: yourdomain.com/llms.txt. The format was proposed by Jeremy Howard, co-founder of Answer.ai, in September 2024. It’s intentionally minimal.
A well-structured file typically contains four elements:
An H1 title with the project or brand name. This is the only required field.
A summary block, written as a Markdown blockquote (>), that gives the AI instant macro context about what the site does and who it serves.
H2 sections that group links by category: core docs, product pages, policies, FAQs.
Annotated link lists in the format - [Title](URL): short description. The description is the critical part. It lets the AI assess a page’s relevance without requesting the URL first.
Here’s a clean example:
# Acme Analytics
> Acme Analytics helps B2B marketing teams track brand visibility across AI search platforms including ChatGPT, Gemini, and Perplexity.
## Product
- [How It Works](https://acme.com/how-it-works): Overview of AI visibility tracking and competitor benchmarking features.
- [Pricing](https://acme.com/pricing): Subscription plans for teams and agencies.
## Documentation
- [Quick Start Guide](https://docs.acme.com/quickstart): Get your first AI visibility report in under 5 minutes.
- [API Reference](https://docs.acme.com/api): Full endpoint documentation and authentication guide.
## Optional
- [Changelog](https://acme.com/changelog): Historical product updates and feature releases.
The ## Optional section signals lower priority. When an AI system is working within a strict token budget, it can skip this block without losing critical information.
5 Reasons Your Site Needs an llms.txt Right Now
1. AI citation systems favor structured sources.
When Perplexity or SearchGPT generates an answer, it runs a rapid source evaluation. Given two sites with comparable content, AI systems tend to reference whichever one has lower parsing friction. A clean llms.txt lowers that friction and raises your probability of being cited first.
2. LLMs process Markdown hierarchy more reliably than HTML semantics.
Models are significantly more responsive to Markdown heading hierarchy (H1, H2, H3) than to equivalent HTML tags like <section> and <article>. llms.txt exposes your site’s information architecture in the format LLMs actually prefer, reducing the chance that key product details get buried or misread.
3. Early adopters are already seeing measurable gains.
Technical companies like Stripe, Vercel, OpenAI, and Anthropic moved fast on this standard. A case study from dev5310, a technical agency, showed that after submitting llms.txt, Google’s AI Mode began treating it as an authoritative identity layer for the company, prioritizing structured details from the file in generated summaries. This is the kind of first-mover advantage that shrinks quickly once the practice becomes standard.
4. llms.txt is a foundational GEO asset.
Generative Engine Optimization (GEO) is less about keyword density and more about citation frequency and answer accuracy. llms.txt ensures that when AI systems reason about your brand, they’re starting from a curated, accurate source you control, rather than a patchwork of third-party mentions, outdated press coverage, and misread product pages.
That distinction matters. AI hallucinations often originate from information gaps, not model failures.
5. It gives you something measurable.
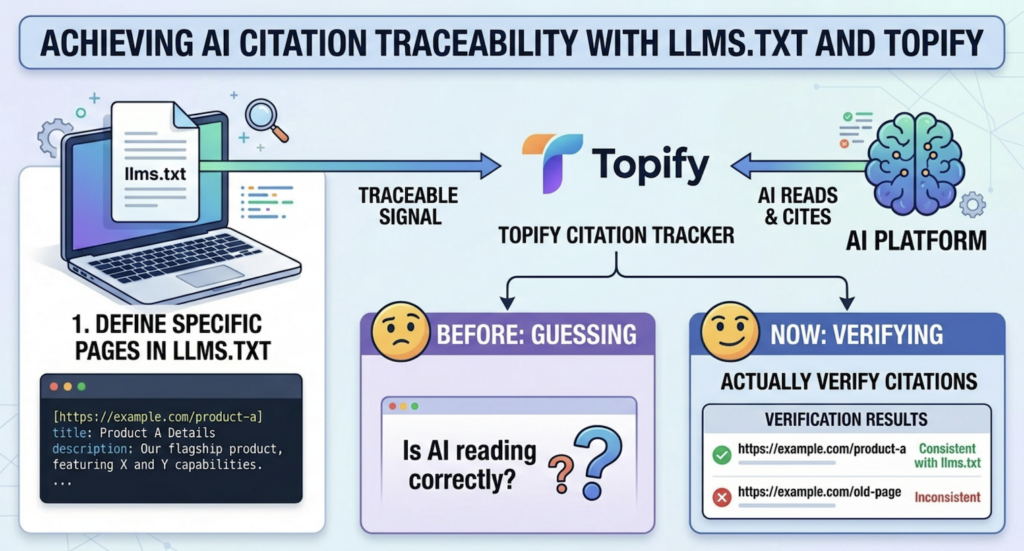
When you define specific pages in llms.txt with structured descriptions, you create a traceable signal. Tools like Topifycan track which URLs AI platforms are citing and whether those citations align with the content you’ve surfaced through llms.txt. You go from guessing whether AI is reading your site correctly to actually verifying it.
How to Create an llms.txt File: Step-by-Step
Step 1: Identify Your Core Information Assets
Don’t try to include everything. An overloaded llms.txt creates the same token-waste problem it was designed to solve.
Focus on four categories:
- Brand identity: who you are, what you do, who you serve
- Product and pricing pages: anything that drives decisions
- Key documentation: guides that reduce support load
- Policy files: pricing, terms, security, and return policies, where accuracy in AI answers directly affects customer trust
Step 2: Write in Standard Markdown Format
Use absolute URLs, not relative paths. A link like /docs/quickstart will break when an AI system tries to resolve it without knowing your domain. Write https://yourdomain.com/docs/quickstart instead.
Every link description should answer one question: why would the AI need this page? Be specific. “Overview of features” is weak. “Explains how the sentiment scoring algorithm works across 7 AI platforms” gives the model enough to decide if it’s relevant.
Step 3: Place It at Your Root Directory
The file must live at yourdomain.com/llms.txt. Most AI crawlers follow a standard scan pattern that checks the root first.
If you run separate subdomains, such as docs.example.com, add a corresponding llms.txt to each root. The files can be different and should reflect the specific content scope of each subdomain.
Step 4: Validate and Test
Before publishing, run your file through a validator like Radarkit or Rankability to check formatting. After publishing, confirm it’s accessible via curl https://yourdomain.com/llms.txt and verify the HTTP status code is 200.
Then do a live test. Ask ChatGPT, Perplexity, or Claude a question about your company’s product or documentation. If the model returns structured, accurate details that match your llms.txt content, it’s working. If it’s still pulling from stale third-party descriptions, you may need to add richer annotations or revisit the priority hierarchy in your file.
llms.txt vs. llms-full.txt: Which One Do You Need?
The original proposal from Jeremy Howard includes two formats. They serve fundamentally different use cases.
| Feature | llms.txt | llms-full.txt |
|---|---|---|
| Primary role | Structured index (navigation) | Complete content archive |
| Typical file size | Under 10KB | Can reach several MB |
| AI handling | Quick scan, follows links on demand | Single-pass full read |
| Best for | Real-time AI search, brand discovery | Developer AI tools (Cursor, Copilot) |
| Maintenance effort | Low, update links as content changes | High, requires full-content sync |
| Token footprint | Minimal | Significant |
For most marketing sites, SaaS landing pages, and product-focused domains: llms.txt alone is sufficient.
For API-first companies, developer tool providers, and documentation-heavy platforms: both files are worth maintaining. llms.txt handles AI search discovery. llms-full.txt gives AI coding assistants the full context they need for deep technical work, without requiring multiple round trips to individual doc pages.
The trade-off is maintenance. llms-full.txt requires you to sync actual content, not just links. If your documentation updates frequently, that overhead compounds quickly.
After You Publish It, How Do You Know It’s Working?
Publishing llms.txt is step one. Knowing whether it’s actually influencing AI behavior requires different tooling than traditional analytics.
Standard tools like Google Analytics don’t capture LLM server-side requests. You won’t see GPTBot or PerplexityBot visits in most dashboards unless you’re actively parsing server logs for those user agents.
What you’re actually trying to measure is citation behavior: which URLs AI platforms are referencing, in what order, and whether those citations match the content hierarchy you defined in your llms.txt.
Topify‘s Source Analysis feature tracks exactly this. It identifies the specific domains and URLs that AI platforms cite when answering questions in your category, and shows how citation patterns shift over time. If a competitor’s domain starts appearing more frequently in AI answers after a content update, that’s a signal. If a page you featured prominently in your llms.txt isn’t showing up in citations at all, that’s an optimization cue.
Three metrics worth tracking after deployment:
Share of AI Voice: the percentage of relevant AI-generated answers that mention your brand or cite your domain.
Citation accuracy: whether AI descriptions of your product match the official positioning in your llms.txt, rather than older third-party summaries.
Crawler activity: server log requests from GPTBot, OAI-SearchBot, PerplexityBot, and Claude-Web, particularly against your llms.txt endpoint. Frequency spikes often correlate with model updates or index refreshes.
Treat this as an ongoing loop, not a one-time setup. Content changes, model behavior shifts, and citation patterns drift. A quarterly audit of your llms.txt, aligned to your major content releases, keeps the signal clean.
Conclusion
robots.txt told the internet what to block. llms.txt tells AI what to read first.
The file itself is simple. What it represents isn’t: a deliberate shift from passive indexing to active AI navigation. For brands investing in GEO, it’s one of the highest-leverage steps you can take without touching your core content. You’re not rewriting pages; you’re giving AI the curator’s guide to what already exists.
The companies that’ll have the clearest AI presence twelve months from now are the ones building that infrastructure today, not waiting for it to become a requirement.
Start with your ten most important pages. Write clean descriptions. Ship the file. Then track whether AI citations actually reflect what you intended.
FAQ
Q: Is llms.txt an official web standard?
A: Not yet. It hasn’t been ratified as an RFC by the IETF. It’s best described as a community consensus protocol. That said, the fact that Anthropic, OpenAI, Stripe, and Vercel have all deployed it on their own domains gives it significant de facto authority. Adoption is accelerating faster than formal standardization typically moves.
Q: Do ChatGPT and Perplexity actually read llms.txt?
A: Evidence from server log analysis and published case studies suggests yes, at least for high-authority or frequently queried domains. AI crawlers like GPTBot and PerplexityBot have been observed making direct requests to yourdomain.com/llms.txt as part of their retrieval optimization routines. This behavior isn’t guaranteed for every site, but it’s consistent enough that early implementation carries real upside with minimal downside.
Q: How often should I update my llms.txt?
A: Sync updates with your major content cycles. Any time pricing, product features, core team, or key documentation changes, update your llms.txt the same day. For everything else, a quarterly review is a reasonable baseline. Stale descriptions are one of the primary causes of AI-generated content misrepresenting a brand’s current positioning.
Q: Does llms.txt affect traditional SEO rankings?
A: There’s no evidence that Google’s core ranking algorithm treats llms.txt as a direct ranking signal. That said, better-structured entity signals can improve how search engines understand site architecture and topical authority over time. The more meaningful impact is on AI-generated search surfaces like Google AI Overviews, where structured, machine-readable context tends to get prioritized over raw HTML content.

