
You’ve been manually searching your brand name in ChatGPT every Monday morning. Sometimes you show up. Sometimes you don’t. Last month, a competitor appeared in three out of five prompts you tested, and you couldn’t explain why. The problem isn’t that you’re not doing SEO. It’s that no amount of manual spot-checking can tell you what’s actually happening across AI search at scale.
That gap between “checking once in a while” and “knowing what AI is citing in real time” is exactly where an LLM citation tracking service fits in.
What LLM Citation Tracking Actually Measures
Most teams conflate three very different signals when they talk about “AI visibility.” Understanding the difference is the first step to tracking anything useful.
The first layer is mention. This means the AI acknowledges your brand name in its response. It knows you exist. That’s awareness, not trust.
The second layer is citation. This is when the AI explicitly links to your URL as a source. It’s pulling your content into its answer as a verifiable reference. Citation means the model trusts your content enough to back its own claims with it.
The third layer is sentiment and position. This captures how the AI frames your brand (recommended, neutral, or compared unfavorably) and where you appear in the response relative to competitors.
The delta between being mentioned and being cited is what some practitioners call the “Trust Gap.” A brand can appear in 40% of AI responses for a keyword but only be cited as a source in 8% of them. Closing that gap is the core objective of any LLM citation tracking service.
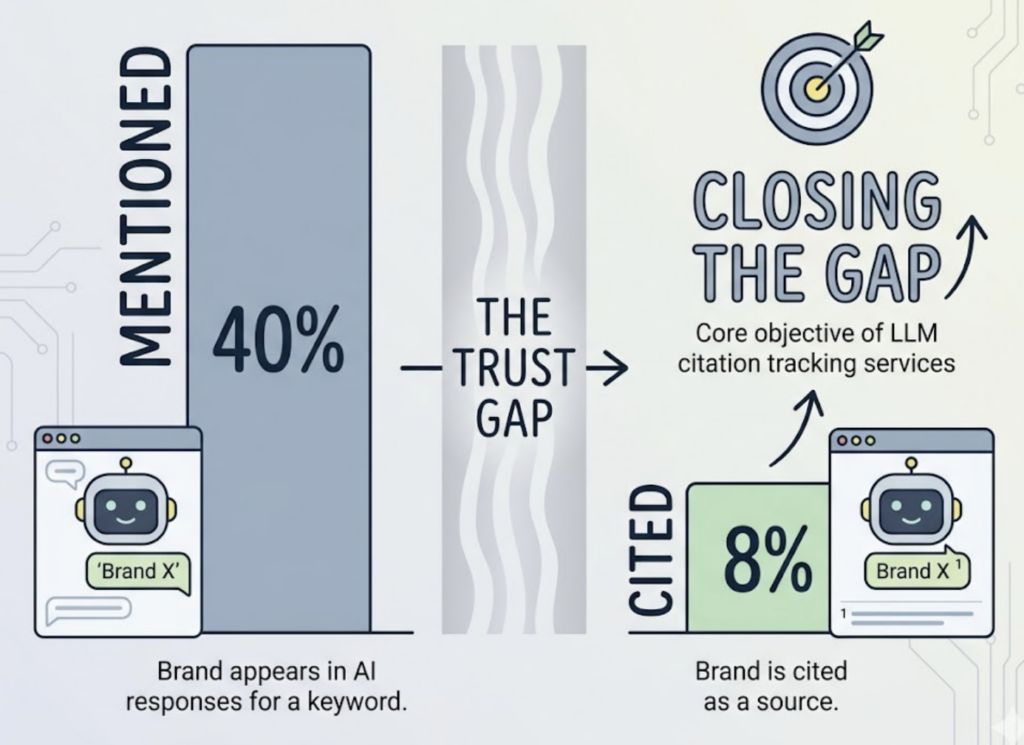
An LLM citation tracking service measures all three layers systematically, across multiple AI platforms, for the specific prompts that matter to your business. It’s not a one-time audit. It’s ongoing monitoring with trend data.
How an LLM Citation Tracking Service Works
The technical pipeline behind a professional LLM citation tracking service follows four stages.
Stage 1: Prompt sampling. The service selects high-intent prompts that represent how real users query AI engines. These aren’t random questions. They’re typically mapped to your funnel: top-of-funnel awareness prompts, mid-funnel comparison prompts, and bottom-funnel purchase-intent prompts.
Stage 2: Response collection. The system runs these prompts programmatically across multiple AI platforms (ChatGPT, Perplexity, Gemini, Google AI Overviews) under standardized conditions. This removes the variability you’d get from manual testing.
Stage 3: Citation extraction. Each AI response is parsed to identify linked domains, URLs, and brand mentions. The service separates explicit citations (linked sources) from implicit mentions (name drops without links).
Stage 4: Source matching and trend analysis. Citations are mapped against a competitor baseline. Over time, this produces a “citation share” metric, showing what percentage of AI responses for a keyword set cite your domain versus competitors.
Here’s the thing: each AI platform has a different retrieval logic. Perplexity provides explicit, numbered citations, making it highly trackable. Google AI Overviews combines traditional search indexing with generative summaries, so you need to monitor both traditional SEO signals and generative visibility. ChatGPT and Gemini often rely on proprietary RAG (Retrieval-Augmented Generation) systems that tend to prioritize fact-dense, structured content over pages with high Domain Authority alone.
That’s why cross-platform coverage isn’t optional. A service that only tracks ChatGPT gives you roughly 25% of the picture.
The Best AI Overviews Analysis Tools for Citation Tracking
Google AI Overviews deserves its own section because it sits at the intersection of traditional search and generative AI. Unlike ChatGPT or Perplexity, AI Overviews pulls from Google’s own search index, which means your existing SEO performance directly influences whether you get cited in a generative summary.
But here’s the catch: ranking on page one of Google doesn’t guarantee you’ll appear in the AI Overview for the same query. The generative layer applies its own selection logic, often favoring content that’s structured for direct extraction (lists, tables, concise definitions) over pages that rank purely on backlink strength.
The best AI overviews analysis tools let you track both layers simultaneously. You need to see your traditional SERP position alongside your AI Overview citation status for the same keyword.
Topify covers this gap. It tracks brand visibility across ChatGPT, Perplexity, Gemini, and Google AI Overviews from a single dashboard. For AI Overviews specifically, you can monitor whether your domain is being cited as a source in generative summaries, track which competitors are appearing, and identify prompts where you’re ranking on page one but missing from the AI Overview entirely.
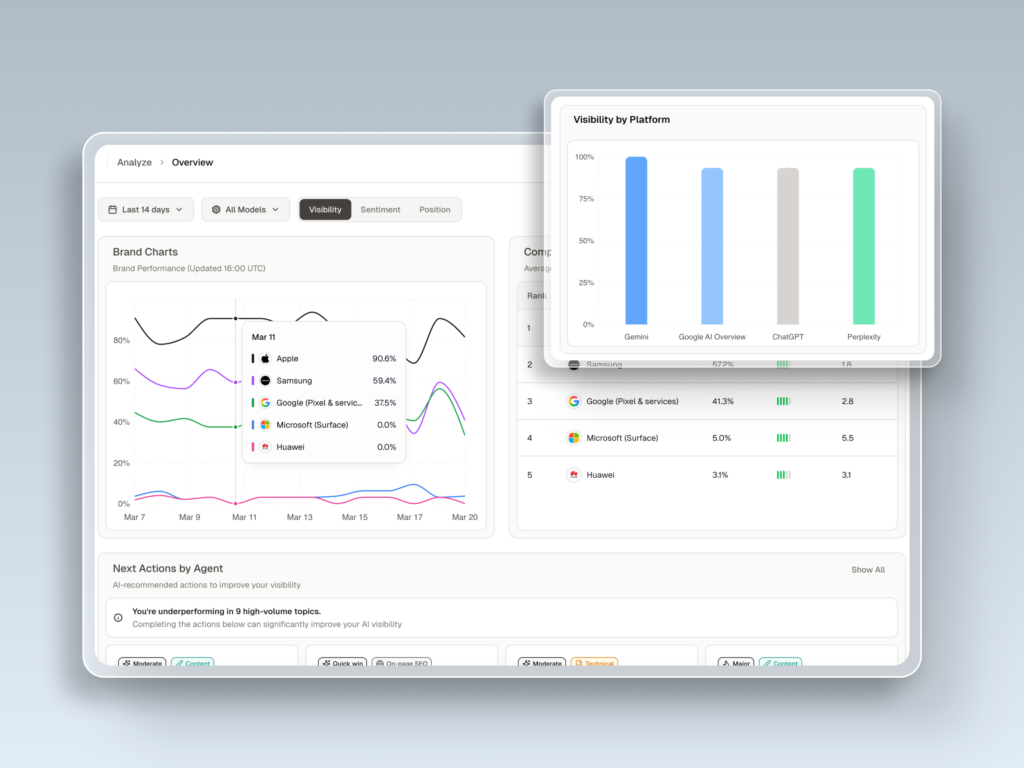
The best AI overviews checkers also show you the source context of each citation. Being cited in a “top alternatives” list is fundamentally different from being cited as the recommended solution. That context changes what action you take next.
5 Common Mistakes That Tank Your LLM Citation Data
Tracking LLM citations is only useful if you’re tracking them correctly. These are the errors that make teams draw wrong conclusions from their data.
Mistake 1: Platform monoculture. Monitoring only one AI platform, typically ChatGPT, and assuming the results apply everywhere. Retrieval behaviors vary significantly between models. A brand that dominates Perplexity citations might be invisible in Gemini responses. Every best-in-class AI overviews analysis tool tracks at least three platforms.
Mistake 2: Confusing traditional SEO metrics with AI citation signals. Domain Authority and backlink counts don’t directly predict whether an LLM will cite your content. AI models tend to prioritize conciseness, fact-density, and structured formatting over traditional link metrics. A page with DA 30 but clear, extractable data points can outperform a DA 80 page packed with marketing copy.
Mistake 3: Treating all citations as equal. Being cited in a “competitor comparison” list is fundamentally different from being cited as the “recommended solution.” Without source context analysis, you can’t distinguish between these two scenarios in your data.
Mistake 4: No competitive baseline. Tracking your own citation share without monitoring competitors is like checking your exam score without knowing the class average. You need relative performance data to identify gaps and opportunities.
Mistake 5: Tracking too infrequently. AI models update their retrieval patterns regularly. Monthly spot-checks miss the inflection points. The most reliable LLM citation tracking services run automated checks at least weekly, with some platforms like Topify offering continuous monitoring across tracked prompts.
What a Strong LLM Citation Tracking Strategy Looks Like
Having a tracking service is step one. Using it strategically is what drives results. Here’s a framework that works in practice.
Step 1: Baseline audit. Identify the top 20 to 50 high-intent prompts in your niche. Record your current citation share across every major AI platform. This becomes your benchmark.
Step 2: Entity anchoring. Standardize your brand identity using structured data (sameAs, about, mentions schema). AI systems cite entities, not just pages. If your brand entity isn’t clearly defined in the knowledge graph, you’re harder to cite.
Step 3: Content extractability. Optimize your highest-value pages for AI retrieval. Start sections with direct answers. Use lists and tables for comparison content. Back every major claim with verifiable external sources. AI models pull from content that’s structured for extraction, not content that’s written for scrolling.
Step 4: Competitive gap analysis. Use your tracking service to identify prompts where competitors are being cited and you’re not. These are your highest-leverage content opportunities. Topify’s Competitor Monitoring feature automates this by detecting competitors and showing citation share side by side across platforms.
Step 5: Iterative monitoring. Shift from manual checking to automated tracking. Monitor the impact of content updates, algorithm changes, and competitive moves. Topify’s Source Analysis tracks which specific domains and URLs AI platforms are citing, so you can see whether a new blog post or schema update actually moved the needle on your citation share.
The checklist version: define prompts, build your entity, structure content for extraction, find competitive gaps, and automate monitoring. That’s the full loop.
LLM Citation Tracking Service Pricing: What to Expect
Pricing for LLM citation tracking services generally falls into three tiers.
| Tier | Price Range | What You Typically Get |
|---|---|---|
| Entry-level | $29 to $99/mo | Single-platform monitoring, basic URL tracking, limited prompt sets |
| Pro | $199/mo | Multi-platform prompt tracking, competitor dashboards, marketing-ready reports |
| Enterprise | $499+/mo | 10+ AI engine coverage, proprietary prompt volume data, governance controls, dedicated support |
Topify’s pricing maps to this structure. The Basic plan starts at $99/mo and includes ChatGPT, Perplexity, and AI Overviews tracking with 100 prompts and 9,000 AI answer analyses. The Pro plan at $199/mo scales to 250 prompts and 22,500 analyses across 8 projects. Enterprise plans start from $499/mo with custom configurations and a dedicated account manager.
When evaluating pricing, focus on three variables: the number of prompts you can track, the number of AI platforms covered, and whether the tool maps citation gaps (not just citation presence). A tool that tells you “you were cited 12 times” is less valuable than one that tells you “your competitor was cited 38 times on prompts where you weren’t cited at all.”
Bottom line: the $99 to $199/mo range covers most mid-market teams. Enterprise brands with multi-region or multi-product portfolios should expect $499/mo and above.
Conclusion
The shift from manual spot-checking to structured LLM citation tracking isn’t a luxury anymore. It’s how brands move from “I think we show up in AI search” to “I know exactly where we’re cited, where we’re not, and what to do about it.”
The mechanics are straightforward: sample the right prompts, track citations across platforms, measure against competitors, and act on the gaps. The difference between brands that capture AI visibility and those that don’t typically comes down to whether they’ve built this loop or are still relying on Monday-morning ChatGPT searches.
If you’re evaluating services, start with Topify to establish your baseline across ChatGPT, Perplexity, Gemini, and AI Overviews. The data will tell you where to focus first.
FAQ
Q: What is an LLM citation tracking service?
A: An LLM citation tracking service systematically monitors which domains and URLs AI systems (ChatGPT, Perplexity, Gemini, AI Overviews) cite as sources when generating answers to business-relevant prompts. It tracks citation share, frequency, position, and context across platforms over time.
Q: How do you measure LLM citation tracking performance?
A: The core metrics are citation share (percentage of AI responses citing your domain vs. competitors), citation frequency (trend over time), citation position (where you appear in the reference list), and source context (whether you’re cited as a recommendation, comparison, or neutral reference).
Q: What’s the difference between LLM citation tracking and AI visibility tracking?
A: AI visibility tracking measures whether your brand is mentioned in AI responses (awareness). LLM citation tracking goes deeper: it specifically monitors whether AI systems link to your content as a cited source (trust). A brand can have high visibility (mentioned often) but low citation share (rarely linked as a source).
Q: How much does an LLM citation tracking service cost?
A: Entry-level plans typically range from $29 to $99/mo for basic monitoring. Pro-level plans around $199/mo include multi-platform tracking and competitor analysis. Enterprise plans start at $499/mo and above for full AI engine coverage and custom configurations.

