
You built the campaign brief, wrote the system prompt, and pushed 10,000 customer reviews through your new AI pipeline. The results looked good. Then the invoice came, and the number was three times what you budgeted. The model wasn’t expensive. The prompts were.
That’s the pattern most marketing teams hit with Claude Haiku token usage: the model is priced right, but the billing logic is invisible until it isn’t. Once you understand how tokens actually work, the gap between “expected cost” and “actual cost” closes fast.
Haiku 4.5 Isn’t the “Cheap Claude” — It’s the Right Claude for High-Volume Work
Most teams pick Claude Haiku 4.5 for the price and stick around for the speed. That’s the wrong mental model.
Haiku 4.5 performs at near-frontier levels for structured, repeatable tasks. Benchmark data shows it matches the coding and reasoning capabilities of the original Claude Sonnet 4, which was state-of-the-art just months before Haiku 4.5 launched. For a marketing team processing thousands of tasks daily, that’s not a budget model. That’s the right model.
The real distinction across the Claude 4.5 family isn’t quality. It’s task type.
| Model | Best For | Latency |
|---|---|---|
| Claude Haiku 4.5 | Batch processing, ticket triage, real-time chat | Sub-second |
| Claude Sonnet 4.6 | Content generation, personalization, deep analysis | 1–3 seconds |
| Claude Opus 4.7 | Strategic planning, complex multi-agent workflows | 3–10 seconds |
Think of Haiku 4.5 as the worker, not the consultant. Where Opus handles high-level strategy, Haiku executes the thousands of discrete tasks, like generating social copy variations, categorizing support tickets, or tagging catalog items at scale.
The Token Math Most Marketers Get Wrong
A token isn’t a word. That’s the first thing to fix.
The Claude tokenizer runs on Byte-Pair Encoding, which means 1 token is roughly 4 characters or 0.75 words for standard English prose. But the rate shifts depending on content type, and those shifts have direct cost consequences.
| Content Type | Tokens per 1,000 Words | Cost Impact |
|---|---|---|
| Standard English prose | 1,300–1,500 | Baseline |
| Technical marketing copy | 1,500–1,800 | ~20% higher |
| JSON / structured data | 3,000–4,000 | 2–3x higher |
| Chinese or Japanese text | 2,000+ | Significant premium |
| HTML / JavaScript code | 2,000–3,000 | High overhead |
If your team runs multilingual campaigns or works with structured data outputs, the token count per task isn’t what you’d estimate from word count alone.
The bigger issue is the output premium. Input tokens on Haiku 4.5 cost $1 per million. Output tokens cost $5 per million. That’s a 5x multiplier. Every time a prompt asks the model to “explain in detail” or “write a comprehensive draft,” you’re pulling on the expensive side of that ratio.
Real Numbers: What 100 Customer Reviews Actually Costs
Here’s a concrete breakdown that illustrates how Claude Haiku token usage adds up in practice.
Task: Analyze 100 customer comments for sentiment and feature requests.
Input breakdown: a system prompt with brand guidelines runs about 800 tokens, and 100 comments averaging 150 words each add roughly 20,000 tokens. Total input: 20,800 tokens.
Output breakdown: 50-token analysis per comment plus a 1,000-token summary report. Total output: 6,000 tokens.
Total cost per run: approximately $0.05.
That seems trivial. Scale it to 10,000 comments per day and it becomes roughly $1,524 per month, assuming clean, single-pass calls. Add multi-turn conversation history that gets re-sent on every message, and that monthly number can increase by an order of magnitude.
The math doesn’t lie. The drift comes from not running the math at all.
5 Habits That Silently Inflate Your Claude Haiku Token Bill
Analysis of enterprise AI spend in 2026 shows the same five patterns appearing across marketing teams. None of them are obvious. All of them are fixable.
1. System prompt bloat. Marketing teams often load system prompts like contracts: every brand rule, negative constraint, and few-shot example in one block. A 3,000-token prompt in a 20-message chat generates 60,000 tokens of redundant input billing. Prompt Caching stores these prefixes at a 90% read discount on subsequent calls. It’s the highest-ROI optimization available.
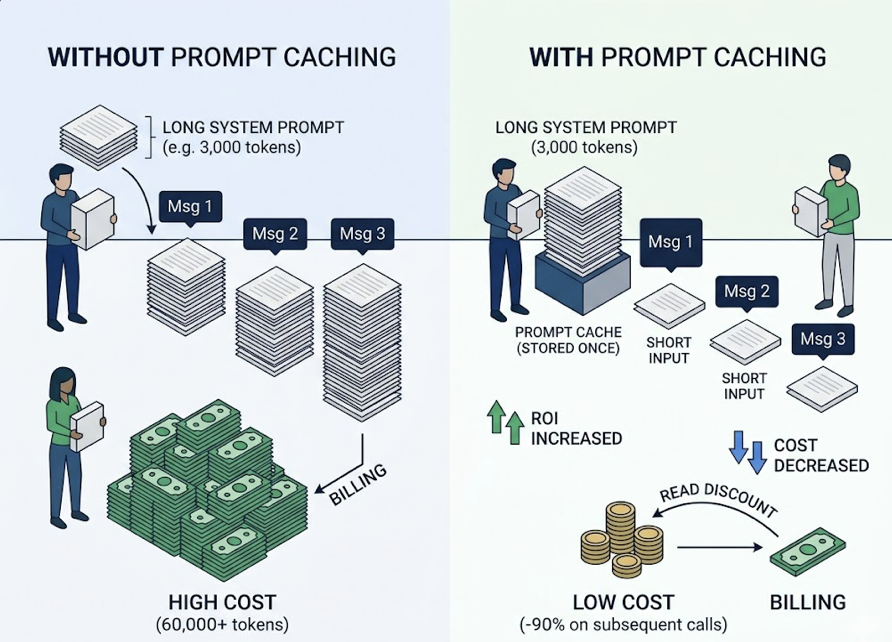
2. Linear history persistence. Many internal tools append the full chat history to every new message. By message 15, the model is re-reading message 1 for the 14th time. The fix: after 15–20 turns, ask the model to summarize key decisions, then start fresh with only that summary as context.
3. Verbosity over-requesting. Phrases like “explain your reasoning in detail” or “give me a comprehensive analysis” are output token magnets. Since output costs 5x more than input on Haiku 4.5, these phrases should stay in testing only. In production, add constraints: “no commentary” or “provide only the final JSON.”
4. Modality inefficiency. Uploading a high-resolution screenshot to extract a headline can consume over 1,300 tokens. The extracted text might be fewer than 50. Use surgical image cropping or prefer text-based markdown uploads over raw PDFs when vision isn’t actually needed.
5. Skipping batch processing. Teams run bulk tasks through the synchronous API, paying full real-time pricing for work that doesn’t require instant results. The Anthropic Message Batches API provides a 50% discount for workloads that can run within 24 hours. Nightly social sentiment analysis and catalog tagging are natural fits.
How to Estimate Your Monthly Token Budget Before You Commit
Budgeting AI spend requires a formula that accounts for variability. A reliable model:
Monthly cost = (tasks × avg tokens per task × rate) × variability multiplier
Use a variability multiplier of 1.7x to 2.0x to account for usage spikes, developer testing, and conversation drift. Here’s how that plays out across team sizes:
| Team Size | Task Type | Monthly Volume | Avg Tokens/Task | Est. Monthly Spend |
|---|---|---|---|---|
| Small team | Content & email | 500 tasks | 2,500 | ~$2–$5 |
| Mid-market | Mixed docs & RAG | 5,000 tasks | 10,000 | ~$60–$100 |
| Enterprise | Automation & triage | 50,000 tasks | 8,000 | ~$450–$600 |
| High-volume | Batch data analysis | 500,000 tasks | 5,000 | ~$2,500* |
*Assumes heavy use of the Batch API for a 50% discount.
One setting teams consistently skip: max_tokens. Setting a ceiling on every API call acts as a financial safety valve. A malformed prompt or a model loop can burn through thousands of dollars in output tokens before anyone notices. Set max_tokens on every call.
When Haiku 4.5 Isn’t Enough: The Signals to Watch
Haiku 4.5 handles 80–90% of daily marketing workloads. But there are real signals that a task has exceeded its capacity.
Instruction drift is the clearest. If the model starts ignoring constraints like “do not use the word ‘innovative'” after several turns, it’s likely hitting context saturation or reasoning limits. The 200,000-token context window is large enough to ingest an entire product documentation set or a 300-page research PDF in one pass, but the middle of long prompts can lose fidelity.
Architectural hallucination shows up in agentic workflows. If the model generates logically impossible sub-tasks that look valid on the surface, it’s lacking the global-state reasoning that Sonnet 4.6 or Opus 4.7 provide.
High-stakes nuance is a harder call. If a campaign involves sensitive cultural translations, legal compliance checks, or anything where getting the tone wrong costs real money, escalate to Sonnet or Opus.
The most cost-efficient 2026 architecture is a tiered system: Opus 4.7 plans, Haiku 4.5 executes at scale, Sonnet 4.6 reviews for quality and consistency. Teams using this barbell approach typically reduce total AI spend by around 60% compared to uniform Opus deployments, without sacrificing quality on high-stakes outputs.
The Part Token Optimization Alone Can’t Solve
You can run perfect token hygiene and still get near-zero ROI if you’re optimizing content for questions nobody asks.
That’s the gap that sits outside most token management frameworks. Marketing teams spend budget generating content around prompts that have no AI search volume, or prompts where their brand has 0% visibility regardless of content quality. Getting the economics right on the execution side doesn’t fix a strategy built on the wrong inputs.
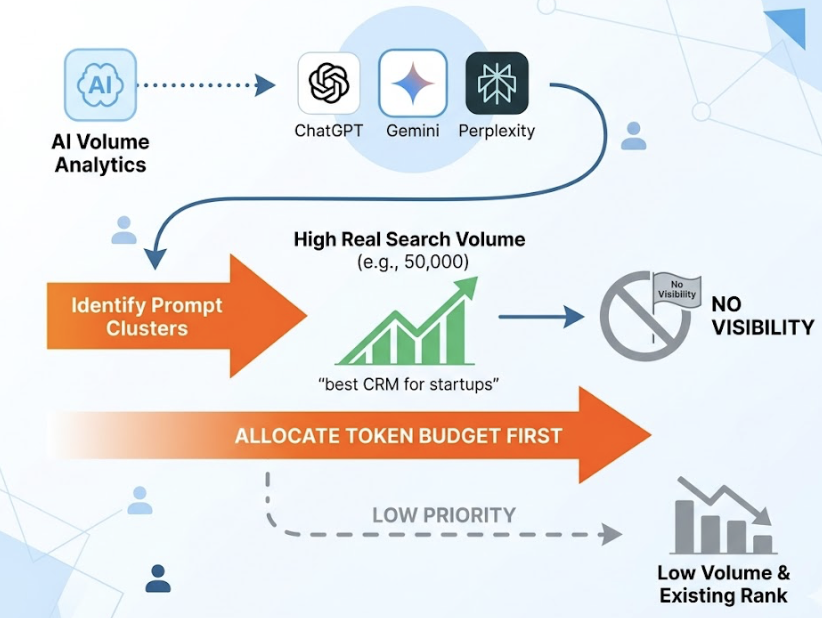
Topify addresses this from the other direction. Its AI Volume Analytics maps actual user demand across ChatGPT, Gemini, Perplexity, and other major AI platforms, showing which prompt clusters have real search volume and where your brand currently appears or doesn’t. If “best CRM for startups” has 50,000 AI searches per month and your brand has no visibility, that’s where the token budget should go first, not into low-volume queries where you already rank.
Topify also surfaces what it calls “conversion-killing hallucinations”: cases where an AI engine consistently pairs a brand with outdated pricing or wrong positioning. Catching those patterns early lets content teams fix the upstream sources before they compound. Combined with Haiku’s low-cost, high-throughput execution, the result is a closed loop: know which prompts matter, generate content for those prompts efficiently, and track whether the brand moves.
The six Topify metrics that define this loop are Visibility Rate, AI Search Volume, Sentiment Score, Position Score, Intent Coverage, and Source Citation Frequency. Together, they convert AI search from an untracked variable into a measurable channel.
Conclusion
Token optimization and content strategy are both necessary. Neither one works without the other. A team with perfect token hygiene but no visibility data is spending efficiently on the wrong things. A team with strong GEO strategy but no cost discipline will burn budget faster than the visibility gains justify.
The practical path: treat Claude Haiku token usage as a managed resource with real budget rules, use the Batch API and prompt caching as defaults rather than optional features, and use a tool like Topify to make sure the token spend is pointing at prompts that actually move the needle. That’s how AI stops being a cost center and starts producing measurable brand outcomes.
FAQ
Q: Does Claude Haiku 4.5 support vision and image input?
A: Yes, Haiku 4.5 supports image inputs. That said, images consume significantly more tokens than equivalent text, often over 1,300 tokens for a single screenshot. For tasks where only the text content matters, extracting or cropping the image before sending it will reduce both cost and latency.
Q: What’s the context window size for Claude Haiku 4.5?
A: Claude Haiku 4.5 has a 200,000-token context window for input, which is large enough to process around 150,000 words in a single request. Max synchronous output is 64,000 tokens. For batch workloads, the same 64,000-token output limit applies.
Q: Can prompt caching actually reduce Claude Haiku token costs significantly?
A: Yes, significantly. Cached input tokens are re-read at a 90% discount compared to uncached input. For any workflow that reuses a long system prompt across multiple calls (brand guidelines, instructions, few-shot examples), prompt caching is the single highest-ROI optimization available. It’s most impactful when system prompts exceed 1,000–2,000 tokens.
Q: Is Claude Haiku 4.5 suitable for long-form content generation?
A: It depends on the task. Haiku 4.5 handles structured long-form output well, such as templated reports, structured summaries, and catalog descriptions at scale. For open-ended editorial content where tone, nuance, and creative judgment matter, Sonnet 4.6 typically produces better results. The hybrid approach, using Haiku for a first draft and Sonnet for review and refinement, often delivers the best cost-to-quality ratio.

