
Your SEO rankings are solid. Your domain authority is climbing. Then a potential customer opens ChatGPT and types, “What’s the best tool for [your category]?” The agent returns three names. Yours isn’t one of them.
That’s not a search ranking problem. It’s a selection problem — and traditional SEO metrics can’t detect it, because they were never designed to measure what an agentic AI decides to recommend.
Agentic AI Doesn’t Search. It Decides.
Most brands still think of AI as a smarter search engine. It isn’t.
Traditional AI answers questions. Agentic AI completes tasks. When a user asks ChatGPT or Perplexity to “find the best project management tool for a remote engineering team,” the agent doesn’t return a list of links and walk away. It evaluates options, applies criteria, and delivers a final recommendation — often without the user ever seeing a search results page.
That’s the core distinction. A search engine finds the best document. A decision engine solves a problem.
The implications for brand visibility are significant. In the search era, the goal was to rank. In the agentic era, the goal is to be chosen. Those are two different games, and most brands are still playing the first one.
From Answer Engine to Decision Engine
The shift has happened in three distinct phases. First came keyword indexing: rank a page, earn a click. Then answer engines like the early versions of ChatGPT and Perplexity synthesized information and delivered direct responses — the goal shifted from ranking a URL to earning a citation.
Now comes the decision engine era. A user doesn’t ask “What is the best CRM?” anymore. They ask an agent to set one up. The agent evaluates brands not just on content quality, but on whether the brand has enough consistent, trustworthy data in the AI’s knowledge base to justify a recommendation. Brands that lack that foundation are excluded before the decision process even begins.
The Shortlist Problem Most Brands Don’t Know They Have
Here’s what makes this particularly difficult to detect: agentic AI doesn’t consider every brand on the open web. It operates from an internal candidate pool — a shortlist generated through retrieval mechanisms that prioritize authority, semantic clarity, and cross-platform consistency.
If your brand isn’t in that pool, it will never appear in a recommendation. Not because the AI evaluated you and passed, but because it never considered you at all.
Organic search traffic is predicted to decrease by 50% or more as consumers shift to generative AI. Yet most brands won’t notice this in their traditional analytics, because the failure happens silently. You’ll still see your Google rankings. You won’t see the AI conversations where your competitors are being recommended and you’re absent.
This is what makes the shortlist problem so dangerous. It’s invisible until it isn’t — and by then, competitors have already built a substantial head start in AI recommendation share.
What Agentic AI Looks for Before It Picks a Brand
To get into the shortlist, it helps to understand what signals the agent is actually using. They’re not what most marketers expect.
Citations Over Clicks
In the search era, backlinks were the primary trust signal. In the agentic era, the equivalent is citations — how often your brand appears in AI-generated responses and what sources are being used to justify those mentions.
Research from Princeton and Georgia Tech found that specific content optimizations can increase AI visibility by 30–40%. Adding statistics boosted citation probability by roughly 40%. Including references to authoritative external sources added another 30–40%. Expert quotations contributed 20–30%.
The mechanism matters here. Agentic AI systems use RAG (Retrieval-Augmented Generation) to ground their recommendations. They look for content that can be extracted cleanly, stated declaratively, and verified against other sources. Dense, promotional marketing copy fails this test. Factual, specific, high-information content passes it.
Sentiment Isn’t Soft Data Anymore
This is the part most brand teams underestimate. LLMs don’t just track whether your brand is mentioned — they evaluate how it’s described across every platform they have access to: G2, Trustpilot, Reddit, industry publications, news sites.
That sentiment analysis produces a score, typically on a 0–100 scale, and that score directly influences recommendation probability. A brand with a high visibility score but a poor sentiment score for “customer support” won’t appear in queries like “best tool with responsive support.” The agent filters it out.
More important is sentiment velocity — the direction sentiment is moving over time. A downward trend, even a gradual one, is a leading indicator of declining AI recommendations. A product bug discussed across Reddit in one week can suppress AI mentions several weeks later. By the time traditional brand monitoring picks it up, the damage in AI recommendation share may already be done.
Entity Consistency Across the Digital Ecosystem
Agentic AI builds its understanding of a brand entity by synthesizing information across dozens of sources. When those sources contradict each other — conflicting pricing, outdated feature descriptions, varying company names — the agent treats that as uncertainty. And uncertain data typically means exclusion from the shortlist.
Maintaining what researchers call “Entity Hygiene” means ensuring your brand’s factual record is consistent and accurate across Google Knowledge Panels, Wikipedia, LinkedIn, G2, Trustpilot, and the third-party publications your category relies on. The AI trusts neutral, encyclopedia-style information more than promotional copy. Shifting from a marketing tone to a factual, informative tone isn’t a stylistic choice in the agentic era. It’s a technical requirement.
Why Your SEO Score Won’t Save You Here
This is worth stating plainly: the technical logic that drove SEO success for the past 20 years is not the same logic that governs agentic AI recommendations. They’re different systems solving different problems.
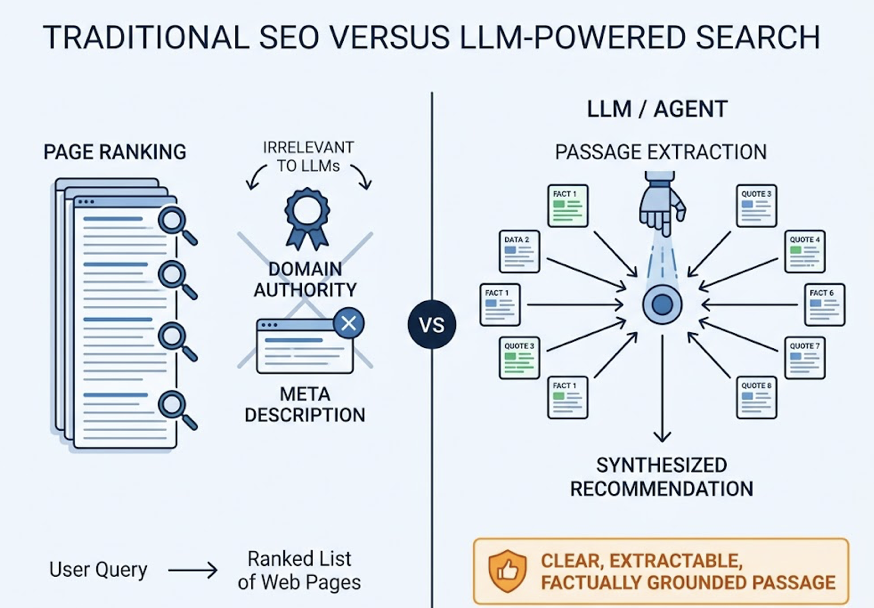
Traditional SEO ranks pages. LLMs extract and synthesize passages. An agent might pull 10 content chunks from 10 different websites and combine them into a single recommendation. Your page’s domain authority and meta description are irrelevant to that process. What matters is whether your content contains a clear, extractable, factually grounded passage that the agent can use to justify including your brand.
| Signal | Traditional SEO | Agentic AI |
|---|---|---|
| Primary goal | Rank a URL | Be cited in a recommendation |
| Success metric | Click-through rate | Recommendation probability |
| Trust signal | Domain authority | Entity confidence + co-citation |
| Content unit | Full page | Individual passages/chunks |
| Relevance mechanism | Keyword match | Semantic similarity (embeddings) |
Content optimized for human conversion — emotional hooks, benefit-focused headlines, CTAs — often performs poorly in AI retrieval environments because it lacks the structural clarity required for machine inference. Agents reward semantic depth, structured data (FAQPage and Organization schema), and declarative language that states the core claim in the opening paragraphs.
A brand might rank #1 on Google and still be completely absent from ChatGPT or Perplexity recommendations — not because of a content quality issue, but because the content isn’t structured for AI extraction.
How to Check If You’re on Agentic AI’s Radar
The most direct starting point is a manual prompt audit. Test your brand across ChatGPT, Gemini, Perplexity, and Claude using three types of prompts.
Direct-brand prompts: “What does [Brand] do?” / “Is [Brand] reliable?” / “How does [Brand] compare to [Competitor]?” These check whether the AI has accurate, current knowledge of your brand entity.
Category-level prompts: “What’s the best [category] tool for [use case]?” / “Top 5 [category] platforms for enterprise teams.” These measure your organic recommendation frequency when no brand is specified.
Scenario-based prompts: “I need to [goal], which tool should I use?” These test how the AI translates complex user objectives into specific brand recommendations.
For each response, document four things: whether your brand was mentioned at all, where it appeared in the response, what tone the AI used, and which sources were cited to justify the mention.
That last point is where most manual audits stop short. Knowing that you were or weren’t recommended is useful. Knowing which third-party domains the AI relied on to make that decision is actionable.
This is where Topify closes a significant gap. Manual audits don’t scale across geographies, languages, or time — and AI platforms update their citation patterns frequently, often weekly. Topify’s Source Forensics feature identifies the specific domains and URLs that AI platforms cite when mentioning your brand (or your competitors), surfacing citation blind spots that you can then target with content or PR strategy. Its Visibility Tracking monitors recommendation frequency across ChatGPT, Gemini, Perplexity, and other major platforms, giving teams a unified score rather than a collection of disconnected snapshots.
The 30-prompt audit tells you where you stand today. Systematic tracking tells you whether you’re moving in the right direction.
Getting Into the Shortlist: What Actually Works
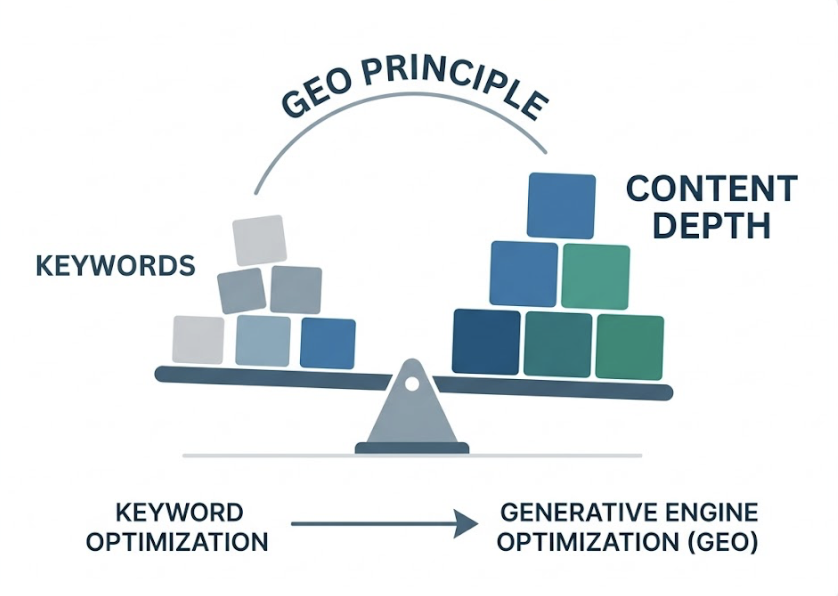
There’s a term for the practice of optimizing content for AI recommendation systems: Generative Engine Optimization, or GEO. The Princeton research that quantified citation impacts established one core principle: content depth matters more than keyword optimization for GEO success.
In practice, that means four things.
Factual specificity over promotional language. Replace benefit statements with verifiable claims. Instead of “industry-leading performance,” use a specific benchmark with a source. LLMs prioritize what researchers call “high-entropy” content — dense with facts, light on filler.
Authority amplification through earned media. AI agents weight third-party editorial mentions more heavily than brand-owned content. Getting your brand discussed alongside category leaders in independent industry publications builds the co-citation signals that move you into the agent’s candidate pool.
Proactive sentiment correction. If the AI is citing an outdated negative review or a 2022 article that no longer reflects your product, that source is actively suppressing your recommendation probability. Reaching out to the publisher to update the record, or building a body of newer, accurate coverage, is a direct GEO intervention.
Structured data implementation. FAQPage, Organization, and Product schema give AI crawlers a deterministic data layer — a clean, machine-readable version of your brand’s key facts that doesn’t require the agent to infer anything.
The challenge for most marketing teams is the gap between detecting a visibility problem and fixing it. Topify’s One-Click Execution addresses this directly. Its AI agent continuously monitors recommendation data across platforms and generates a prioritized list of GEO actions — content updates, citation opportunities, sentiment corrections — that teams can deploy without building custom workflows. When AI platforms update their citation patterns, the system detects the shift and surfaces new actions automatically, creating a closed loop between visibility monitoring and strategy execution.
That’s a meaningful operational difference. Weekly SEO audits are too slow for a system where citation data can shift within days.
Conclusion
The transition from search engine to decision engine is already in progress. Agentic AI is making brand recommendations today, in real conversations, for real purchase decisions — and most brands have no visibility into whether they’re winning or losing those moments.
The brands that move first to build entity authority, citation density, and consistent sentiment signals will establish a structural advantage that compounds over time. The ones that wait until their traffic data shows the impact will be correcting a deficit instead of building a lead.
Get started with Topify to see where your brand currently stands in AI recommendations — and what’s actually driving (or blocking) the result.
FAQ
Q: What is agentic AI and how is it different from regular AI search?
A: Regular AI search (like early ChatGPT) synthesizes information and gives you an answer. Agentic AI goes further — it can plan, reason across multiple steps, use external tools, and complete tasks autonomously on behalf of the user. Instead of telling you which CRM options exist, an agentic AI might evaluate your team’s needs and recommend a specific one. For brands, this distinction matters because agentic AI doesn’t just present options; it selects a winner.
Q: Does agentic AI use Google search results to make recommendations?
A: Not directly. Agentic AI systems typically rely on their own RAG (Retrieval-Augmented Generation) pipelines, which pull from a curated mix of indexed web content, structured databases, and internal knowledge bases. A high Google ranking can increase the chance that your content gets indexed by these systems, but it doesn’t guarantee inclusion. The selection criteria — factual grounding, entity consistency, sentiment scores, citation patterns — are different from Google’s ranking signals.
Q: How can I tell if my brand is being recommended by agentic AI?
A: Start with a manual audit: test 20–30 prompts across ChatGPT, Gemini, Perplexity, and Claude using direct-brand, category-level, and scenario-based queries. Track whether your brand appears, where it ranks in the response, and which sources are cited. For ongoing monitoring at scale, platforms like Topify automate this tracking across platforms and geographies, and can identify exactly which third-party domains are influencing your AI recommendation rate.
Q: What’s the fastest way to improve my brand’s visibility to AI agents?
A: The highest-impact starting point is usually source correction — identifying which third-party domains AI platforms are currently citing about your brand or category, and ensuring your brand has accurate, current coverage on those specific sites. This is more direct than creating new content from scratch. From there, implementing structured data (Organization and FAQPage schema) and securing mentions in category-level editorial pieces are consistently strong GEO moves, backed by the Princeton/Georgia Tech citation research.

