
The signals behind Claude AI brand visibility, and what you can do to change your position
Your brand has a website. You publish content. You rank on Google. And yet, when someone asks Claude to recommend tools in your category, your name doesn’t come up.
That’s not a SEO problem. It’s a different problem entirely.
Claude doesn’t work the way Google does. The logic behind its recommendations is separate, and misunderstanding that gap is exactly why most brands stay invisible in AI-generated answers.
Here’s what’s actually happening.
Claude Isn’t Pulling from a Search Index
When Claude responds to a recommendation request, it’s not querying a live database or crawling the web in real time. It’s synthesizing a response from what researchers call “parametric memory,” the patterns and associations encoded into the model’s neural weights during training.
Think of it as sediment. Every piece of content that existed before Claude’s training cutoff left a trace. The more a brand appeared across credible, consistent sources, the deeper that trace.
This architecture has a direct implication for brand teams: your brand’s weight in Claude’s responses was largely determined before you started optimizing for it. Claude 3.7 Sonnet’s reliable knowledge ends around October 2024. Claude 4.5 extends to January 2025. Newer models add real-time search in certain configurations via Retrieval-Augmented Generation (RAG), but even then, the base model’s pre-trained biases influence how it interprets what it retrieves.
You’re not competing in a keyword auction. You’re competing for space in a model’s learned reality.
The 3 Signals That Actually Shape Claude AI Brand Visibility
Claude doesn’t rank brands by advertising spend or domain authority. Its recommendation logic reconstructs from three learned patterns.
Mention Frequency on Trusted Third-Party Sources
The correlation between brand mentions and AI citation probability is 0.664. The same correlation for traditional backlinks is 0.218. That gap tells the whole story.
Claude treats a mention on a high-authority domain as a qualitative signal of trust, not just a navigational pointer. Wikipedia currently accounts for roughly 13% of AI model citations. Reddit’s share grew 87% in 2025 and now represents over 10% of ChatGPT citations, with similar patterns showing in Claude’s responses for community-driven queries.
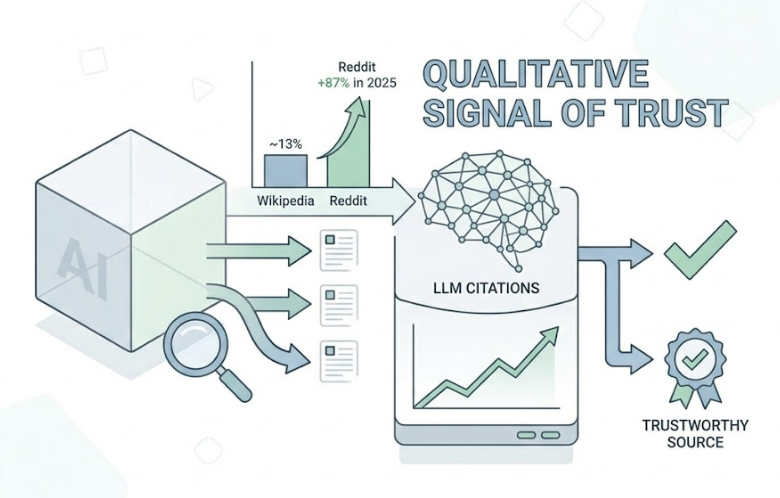
The implication: it’s not about how many pages your brand owns. It’s about how many credible, independent sources reference you, and in what context.
Contextual Consistency Across Sources
If your brand is described as “an enterprise data integration platform” on your website but “a workflow automation tool” on G2 and “an ETL solution” on Reddit, Claude’s model faces conflicting signals. The result is lower confidence in any recommendation.
This is what researchers call “entity blending,” where the model either avoids citing the brand altogether or misattributes its features to a competitor. Consistent category language across LinkedIn, Crunchbase, review platforms, and media coverage reduces that ambiguity significantly.
Schema alignment matters here too. Implementing structured data that mirrors your visible content gives the model a cleaner extraction surface.
Category Association and Prompt Relevance
Claude maps brands to topic clusters based on their relationship to adjacent concepts in the training data. If your brand is consistently co-mentioned with “zero-trust architecture” and “enterprise cybersecurity” in technical publications and forum discussions, Claude learns to surface you when those prompts appear.
This is niche positioning at the model level. And it explains why a smaller brand with precise topical coverage can outperform a much larger competitor relying on broad, generic positioning.
Being Online Is Not the Same as Being Recommended
This is the finding most brand teams find uncomfortable: 73% of brands have zero mentions in AI-generated responses despite ranking on page one of traditional search results.
It’s not a measurement error. It’s a structural gap.
Traditional SEO satisfies crawlers. Claude’s recommendation logic satisfies a different standard: semantic authority. The degree to which a brand is treated as the definitive answer to a problem across independent digital discourse.
The core issue is the over-reliance on owned media. Your website, your blog, your branded content. Claude’s Constitutional AI training actively filters for commercial bias, which means self-promotional content is processed with skepticism built in.
The data confirms this. Promotional tone in content has a -26.19% correlation with citation probability. That means typical marketing copy, the kind most brands default to, is actively working against AI visibility.
On the flip side, third-party sources account for 80-85% of AI citations. Your own domain contributes 15-20% at most, and primarily for technical specifications, not authority signals.
Why Competitor Brands Keep Showing Up Instead
When a user asks Claude for a recommendation, the model typically surfaces three to five brands. Not ten. Not twenty.
That compression is important. The “ten blue links” of Google become a winner-take-all scenario in generative responses. If your competitor is in that shortlist and you’re not, you don’t just lose visibility. You effectively don’t exist for that user’s decision.
Competitors who dominate these responses typically share one characteristic: a stronger external signal network. More “best of” list inclusions. More independent comparison coverage. More community discussion with their brand name attached to specific use cases.
Research by Stacker in 2026 found that distributed earned media is 5.3x more likely to be the sole source of a brand’s AI visibility than the brand’s own domain. Syndicating structured content through credible publishers can triple cross-platform coverage across Claude, ChatGPT, and Perplexity simultaneously.
That’s not a PR strategy. That’s a model-level visibility strategy.
You Can’t Improve What You Can’t See
Here’s the practical problem: Claude’s conversations are private. Traditional analytics can’t track what the model says to users about your brand, whether it’s recommending you, misrepresenting your product, or citing a three-year-old negative review.
That black box is where most optimization efforts stall.
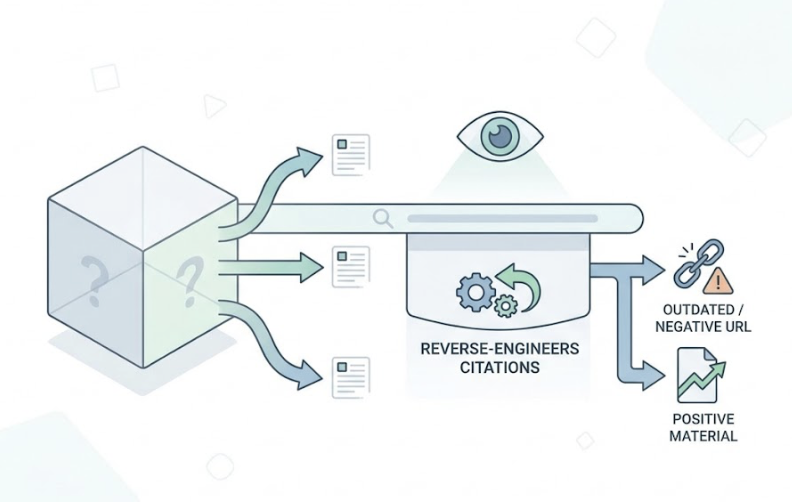
Topify was built specifically to make that black box visible. Its Source Forensics capability reverse-engineers the citations Claude generates, identifying the exact URLs influencing its recommendations. If the model is citing outdated or negative coverage, you know which URL to target for a content refresh or to dilute with higher-authority positive material.
Topify’s Sentiment Velocity tracking goes further: it monitors not just what Claude says about your brand today, but the direction that sentiment is moving over time. A static score tells you where you stand. Velocity tells you where you’re heading.
Hallucination Alerting flags in real time if Claude starts generating false claims about your product, giving PR teams the window to flood the ecosystem with corrective, verified data before the misrepresentation compounds.
The platform also tracks Entity Confidence, measuring how cleanly Claude distinguishes your brand from competitors or generic category terms. Low entity confidence is often the hidden cause of “brand invisibility,” where Claude knows your category but can’t reliably surface your specific name.
4 Things That Actually Move the Needle
Strategy matters less than execution sequence here. These four levers are statistically validated to increase citation probability and recommendation frequency.
Seed high-weight third-party domains. Digital PR in tier-1 publications like TechCrunch or Forbes, combined with community presence on Reddit and detailed outcome-specific reviews on G2 or Capterra, builds the external signal network Claude’s model treats as authority evidence. This is mention-building, not link-building.
Unify your descriptive language. Synchronize how your brand is described across Wikipedia, LinkedIn, Crunchbase, and your website. Pick clear category language and commit to it across every surface. The goal is a “clean signal” the model can decode without ambiguity.
Map content to specific prompt scenarios. Don’t write for broad topics. Write for specific problems. Content that directly answers “How to fix data pipeline latency?” with a proprietary framework gives Claude something extractable and citable. Comparison pages that acknowledge product limitations, counterintuitively, earn higher model trust than pages that claim universal superiority.
Monitor continuously, not annually. Adding factual statistics to content increases AI visibility by 40%. Citing authoritative sources adds another 40%. Expert quotations add 28%. Keyword stuffing reduces it by 10%. These numbers shift as model versions update. Weekly or bi-weekly tracking of share of voice and sentiment across Claude, ChatGPT, and Perplexity turns optimization from a one-time project into a compound advantage.
Conclusion
Claude’s recommendation logic rewards accuracy, external validation, and descriptive clarity. It penalizes promotional language, inconsistent positioning, and over-reliance on owned media.
That’s a different game than SEO. The brands winning AI visibility today aren’t necessarily the ones with the biggest budgets or the longest domain histories. They’re the ones with the most reliable, consistent, and independently verified footprint across the digital commons.
The gap between “being online” and “being recommended” is real. It’s also measurable, and it’s closeable. But only if you can see it first.
FAQ
Does Claude AI update its brand knowledge in real time?
Generally, no. Claude’s core recommendations come from parametric memory with fixed training cutoffs. Some implementations add real-time search via RAG, but even then the base model’s pre-trained weights shape how new data gets interpreted. Core brand knowledge typically changes only when the model is retrained, which happens every few months to a year.
Is Claude AI brand visibility the same across different Claude versions?
No. Different versions have different training cutoffs and reasoning behaviors. A brand that launched in late 2024 may be invisible to Claude 3.5 Sonnet but recognized by Claude 4.5 or 4.7. Newer models also apply Constitutional AI filters more rigorously, which can result in more neutral or cautious brand recommendations across the board.
How long does it take to see changes after optimizing for Claude?
Core parametric knowledge updates with model retraining, which takes months. But if Claude is using agentic search tools or RAG in a given deployment, high-authority third-party content published and indexed by search engines can start influencing responses within days to a few weeks.
Can smaller brands compete with established names in Claude’s recommendations?
Yes, and often more effectively than in traditional search. Claude prioritizes specific match quality and factual density over broad name recognition. A smaller brand that answers a niche problem with precision and earns validation on a few high-trust sources, such as specialized Reddit communities or industry journals, can consistently outrank a larger competitor relying on generic marketing content.

