
Your ChatGPT dashboard looks healthy. Mentions are up. Sentiment is mostly positive. You feel covered.
Then someone on your team actually tests Claude AI and discovers your brand is either missing entirely or described with qualifiers you’d never approve. That’s when it becomes clear: Claude isn’t an extension of your ChatGPT strategy. It’s a separate system with its own logic, its own sources, and its own criteria for which brands deserve a recommendation.
Here’s how to build a monitoring framework that tells you exactly where you stand inside Claude’s answers.
Claude AI Doesn’t Recommend Brands the Way ChatGPT Does
The first mistake brands make is assuming Claude and ChatGPT share the same recommendation logic. They don’t, and treating them the same is where most Claude AI brand visibility efforts fall apart.
ChatGPT’s recommendations lean heavily on Bing’s search index and broad public consensus. Brands with strong Wikipedia presence and high general awareness tend to surface reliably. Claude operates differently. Its real-time search is powered by Brave Search rather than Bing, which means a brand that ranks #1 on Google or Bing can still be practically invisible to Claude if it hasn’t been indexed through Brave’s Web Discovery Project.
That’s a structural gap most brands never account for.
The core difference in how Claude sources and weights brand mentions
Claude’s weighting system rewards technical depth and logical structure over brand recognition. Research from this domain shows that structured, data-backed content is cited approximately 30% more often than standard marketing copy within Claude’s outputs. The model’s Constitutional AI framework also makes it more cautious: when Claude can’t verify a claim about a brand, it tends to omit the brand rather than generate a plausible-sounding answer.
ChatGPT’s typical citation sources skew toward Wikipedia (around 47.9%) and Reddit (around 12%). Claude skews toward industry blogs (around 43.8%), expert reviews, and technical documentation. If your content strategy has been built for Wikipedia authority and social proof, it won’t perform the same way inside Claude’s evaluation logic.
Why your ChatGPT visibility score doesn’t carry over to Claude
Only 11% of domains get cited by both ChatGPT and other AI platforms for the same query. That number should reframe how you think about AI brand visibility entirely. It means your visibility is almost certainly not transferring across models.
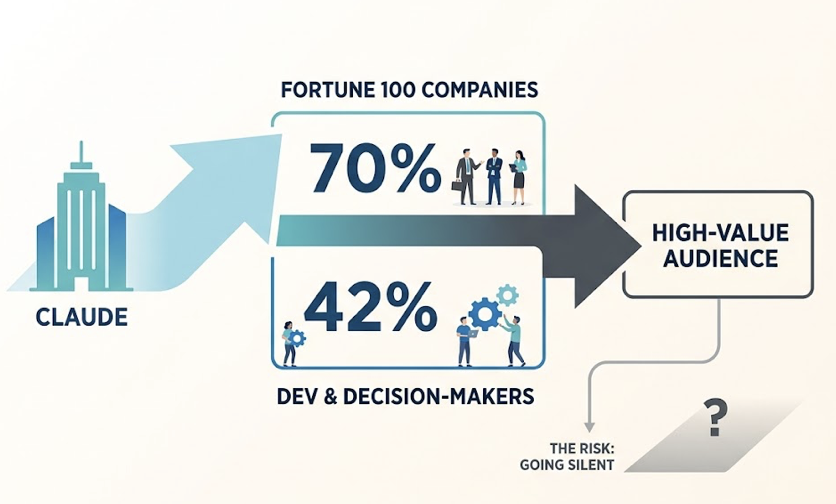
There’s also a business case that makes Claude-specific monitoring worth prioritizing. Claude has an estimated 70% penetration rate among Fortune 100 companies, and roughly 42% of developers and technical decision-makers use it regularly. That’s the audience segment making high-value purchasing decisions. Going silent in Claude’s answers isn’t a minor gap. It’s losing the room where enterprise deals get researched.
Step 1 — Map the Prompts That Shape Your Claude AI Brand Visibility
Most brands test 3 to 5 keyword variants and call it a baseline. In Claude’s environment, that approach misses how users actually query the model. Claude handles long-context, scenario-specific questions that don’t map neatly to traditional keyword research. You need a structured prompt set to cover the full range of contexts where your brand should appear.
Category prompts, comparison prompts, and use-case prompts
Three prompt structures determine most of a brand’s visibility inside Claude, and each requires a different content strategy to win.
Category prompts are exploratory. “What are the best enterprise CRM platforms in 2026?” Claude typically returns a structured list here. Your visibility depends on whether you’ve made it into the model’s parametric knowledge or the top results of a Brave-powered search.
Comparison prompts hit mid-to-late decision stage. “Compare [your brand] and [competitor] on data privacy and compliance.” Claude is strong at nuanced trade-off analysis. If your technical documentation is thin, Claude may flag you as “limited information available” rather than defend your position.
Use-case prompts are where brand authority compounds quietly. “How do I automate cross-border logistics clearance using AI tools?” Your brand may not be mentioned by name, but if Claude pulls your content as the framework for solving the problem, that’s the kind of citation that builds durable recommendation weight.
How to build a 50-prompt test set for your industry
A statistically useful test set requires what’s called swarm probing: running multiple variants of the same intent to see how consistently Claude surfaces your brand across phrasings, formality levels, and persona framing.
A working 50-prompt structure looks like this: identify 10 core scenarios where your brand must show up, then build 5 variants per scenario by adjusting query length, persona framing (“as a CTO evaluating options…”), geographic constraints, and technical specificity. Include 2 to 3 negative control prompts, unrelated queries where your brand should not appear, to check whether Claude is making erroneous entity associations.
That last piece matters more than people expect. If Claude is linking your brand to contexts where it doesn’t belong, that’s an accuracy problem you need to catch early.
Step 2 — Run Structured Tests and Record What Claude Actually Says
Manual testing works, but only if the results are reproducible. Claude’s outputs are probabilistic. Run the same prompt twice and you’ll get different phrasings. Run it in a continued session versus a fresh one and you may get different brand mentions entirely. Standardization isn’t optional here.
What to capture beyond “yes or no”
Each test session needs a clean slate. Start a new conversation before every prompt run to prevent Claude’s long-context memory from carrying over previous brand associations. Log which model version you’re testing (Claude Sonnet 4.6 versus Opus 4.6, for instance, can produce different results), because different versions have different training cutoff dates and retrieval strategies.
If your team operates across regions, multi-location sampling matters too. Claude’s Brave-powered search can return different results depending on geographic context when search mode is enabled.
Sentiment, position, and source citation: the three data points that matter
Recording whether Claude mentioned your brand is the minimum. The three data points that actually drive content decisions are:
Sentiment framing. Claude doesn’t just list brands, it describes them. Is your brand characterized as “an established player with proven enterprise integrations” or “a platform that some users find has a steeper learning curve”? That framing shapes how B2B buyers interpret the recommendation before they visit your site.
Position rank. In AI-generated text, first mention isn’t just first, it’s dominant. Brands appearing in the opening paragraph or at the top of a list capture over 80% of the reader’s attention. By the fourth position, perceived authority drops sharply. Position is as much a conversion factor as sentiment.
Source citation. This is the data point most brands overlook and the one most directly actionable. Which URLs is Claude actually pulling from when it describes your brand? Is it your own product pages, a G2 review you haven’t managed in two years, or a competitor’s comparison post written to make you look weaker? That answer tells you exactly where your content investment needs to go.
4 Metrics That Tell You More Than a Mention Count in Claude AI
A raw mention count is a vanity metric in GEO. What you need is a composite measurement system that connects Claude’s outputs to real brand risk and real content priorities.
Visibility rate is the baseline: how often does your brand appear across your full prompt test set? In B2B SaaS, early-stage brands typically land between 2% and 8%. To be considered a category leader inside Claude’s answers, you generally need 35% to 50% across tested prompts. Anything below 10% means you’re effectively invisible in AI-assisted research for your category.
Sentiment score is where Claude’s Constitutional AI creates a higher bar than other models. Claude tends to add qualifiers and caveats when its confidence in a brand’s claims is low. If Claude is consistently prefacing your mention with “though some users have noted reliability concerns,” your sentiment score is working against you even when you’re showing up. Research indicates B2B SaaS brands cluster between 50% and 77% positive sentiment, and anything below 50% signals a reputation problem that content alone won’t fix.
Answer Placement Score (APS) weights your position within the response. A brand in first position scores 1.0. Second position scores roughly 0.6. Third and beyond drops off sharply. Tracking your APS average across key comparison prompts tells you whether you’re winning the category or just participating in it.
Owned citation rate is the most actionable of the four. What percentage of the time Claude mentions your brand is it sourcing from URLs you control? If Claude is consistently reaching for third-party reviews or competitor content to describe you, your own web properties aren’t meeting Claude’s technical density threshold. That’s a fixable content architecture problem, not a PR problem.
Step 3 — Build a Monitoring Cadence Before Claude’s Outputs Shift
Claude’s recommendations are not static. Model updates shift its internal knowledge base. Changes to its search infrastructure can restructure which sources it prioritizes overnight. A monitoring system without a defined cadence will always be reacting late.
Weekly spot-checks versus monthly full-cycle audits
A practical two-tier cadence covers both fast-moving signals and long-term strategic measurement.
Weekly spot-checks should cover about 20% of your highest-intent prompts: the comparison and use-case queries most likely to influence purchase decisions. This layer catches early signals of visibility drops caused by model fine-tuning or narrative shifts in Claude’s indexed sources like Reddit or industry review sites.
Monthly full-cycle audits run your complete 50 to 100-prompt set. This is the only way to measure whether longer-horizon GEO strategies, content rebuilds, third-party placements, technical documentation updates, are actually moving your metrics inside Claude.
Quarterly, layer in a cross-channel correlation. Connect AI visibility trends to CRM lead source data and traditional SEO performance. The goal is to isolate what percentage of pipeline can be attributed to AI-assisted research, even when the attribution isn’t directly tracked.
The triggers that should prompt an immediate re-test
Outside your scheduled cadence, certain events require dropping everything and running a full audit. A major Claude model version upgrade, the kind that shifts reasoning capability by 10% or more, typically comes with a moved training cutoff date that can reset your brand’s parametric presence. A confirmed change in Claude’s search infrastructure partners would restructure which sources get prioritized entirely. A PR event, acquisition, or executive-level news item will get absorbed into Claude’s real-time retrieval layer quickly and may change how Claude frames your brand in comparison queries. And if you discover Claude is misstating your pricing or mischaracterizing a core feature, that’s a signal that an outdated or inaccurate third-party source has gained weight in Claude’s retrieval pipeline. Address it immediately.
Where Manual Claude AI Visibility Tracking Breaks Down at Scale
Manual tracking is a legitimate starting point. It’s not a sustainable monitoring infrastructure.
Run the math: 50 prompts across 4 platforms (Claude, ChatGPT, Gemini, Perplexity), running bi-weekly, generates 400 operations per month. Add swarm probing at 10 variants per prompt for statistical confidence and you’re looking at 4,000 responses to process monthly. That’s thousands of tokens of output to parse for sentiment classification, position ranking, and source URL extraction.
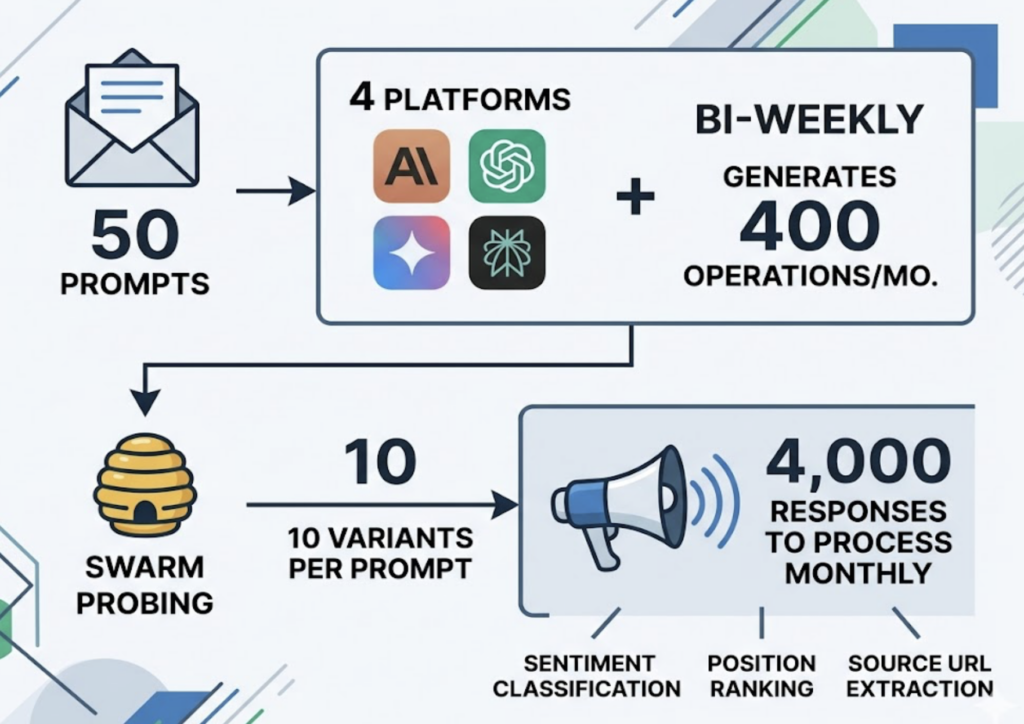
The cost compounds further. Calling Claude’s flagship API at scale for monitoring purposes can consume a year’s worth of SEO budget in a few months. And that’s before accounting for the analyst time required to turn raw outputs into structured tracking data.
This is the scale problem Topify was built to solve. Its monitoring architecture uses tiered model routing: low-cost models handle initial mention detection, while Claude’s more capable tiers are called only for sentiment depth and citation analysis. The result is a reported 95%+ reduction in monitoring costs compared to direct API calls for the same coverage.
Topify’s platform tracks seven core metrics automatically: visibility score, sentiment polarity, position ranking, intent alignment, mention volume, source citation origin, and Conversion Visibility Rate (CVR), which estimates the likelihood that a Claude answer drives a user toward brand engagement. Competitor Monitoring runs in parallel, so when a rival starts gaining ground in Claude’s answers for your target prompts, you see it in the same dashboard rather than discovering it weeks later.
Turning Claude AI Visibility Data into Content Actions
Data without a content response is just reporting. The goal is closing the loop between what Claude says about your brand and what your content team builds next.
If Claude is citing your competitors’ sources instead of yours
This gap has a name: the mention-source gap. Claude acknowledges your brand exists, but the URLs it pulls from are a competitor’s comparison post, a G2 page you haven’t updated in 18 months, or a Reddit thread where your product was criticized.
The fix isn’t more content volume. It’s content structure. Claude’s retrieval system responds to what researchers call machine-readable authority: schema markup (JSON-LD) that explicitly defines relationships between your services, your team’s expertise, and your case studies. It also requires Brave Search indexability. If fewer than 20 unique Brave users have visited your key product pages, those pages may not carry enough weight in Brave’s Web Discovery Project to register as a reliable source in Claude’s pipeline.
Third-party signal management also matters. If Claude consistently surfaces Reddit as a source for your category, the strategy isn’t to avoid Reddit. It’s to be represented there with high-quality, technically precise contributions that Claude can extract as expert signal rather than consumer complaint.
If your sentiment score is stuck at neutral
Neutral sentiment in Claude typically means your content lacks a distinct point of view or verifiable authority. Claude is trained to filter out content that reads as AI-generated filler or promotional copy without factual grounding.
The structural fix is rebuilding core pages around what’s called the Generative Engine Answer Format (GEAF). The principle is that Claude is looking for content structured like a high-quality answer, not a sales page.
That means H2 headings framed as the questions your buyers would actually ask Claude. A 40 to 60-word summary at the top of each section that gives Claude a quotable “answer capsule.” Ordered lists and fact blocks rather than paragraphs of descriptive prose. Data points with verifiable sources attached to every significant claim. And E-E-A-T signals, expert quotes, author credentials, original research, that increase Claude’s confidence weighting for your content in analytical queries.
Topify’s Source Analysis feature maps exactly which of your URLs Claude is currently citing and which are being bypassed. That data turns a vague content audit into a prioritized list of pages to rebuild against GEAF standards.
FAQ
How often does Claude AI update its brand recommendations?
Two separate layers affect how often Claude’s outputs change. At the model layer, Anthropic releases updates and fine-tuned versions roughly every two months, which shifts Claude’s internal training knowledge. At the retrieval layer, Claude’s Brave-powered search can reflect new internet content within days or even hours. Weekly spot-checks are the minimum cadence to catch shifts at both layers before they compound.
Can I track Claude AI visibility without a paid tool?
Yes, at small scale. A structured spreadsheet with 10 to 20 core prompts, tested weekly in fresh Claude sessions, will give you a baseline. Record mention presence, sentiment phrasing, position, and any URLs Claude cites. This won’t give you share-of-voice calculations or competitor benchmarking, but it’s a valid starting point for building initial GEO awareness before investing in automated infrastructure.
What’s a realistic visibility rate benchmark for Claude AI?
It depends on your category and growth stage. In B2B SaaS, a Series A brand typically targets 8% to 20% visibility across tested prompts. Category leaders aiming for dominant positioning should be tracking toward 35% to 50%. More important than the absolute number is the trend. A brand moving from 6% to 14% over a quarter with improving sentiment is outperforming a brand sitting at 40% with a declining APS average.
How is Claude AI monitoring different from Google Search Console?
GSC measures clicks and impressions from traditional search rankings. It tells you what happened after a user decided to visit your site. Claude monitoring tells you what the AI intermediary said about you before the user ever saw your domain. In a zero-click AI research environment, that’s the decision-shaping layer GSC has no visibility into at all.
Conclusion
Claude AI isn’t a feature of your existing monitoring stack. It’s a separate evaluation system with its own sources, its own quality threshold for brand content, and its own logic for deciding which brands deserve a first-mention position in a high-stakes enterprise research query.
The brands that figure this out first will have a compounding advantage. Every piece of content restructured to meet Claude’s technical density standards, every Brave-indexed page that earns owned citation, and every weekly cadence that catches a sentiment shift before it hardens into a lost deal represents a gap between you and competitors still treating Claude as an afterthought.
Build the prompt matrix. Run the structured tests. Track the four metrics that actually move decisions. And when manual tracking hits its scale ceiling, let the infrastructure carry the load so your team can focus on the content actions that change what Claude says next.

